基于自学习中枢模式发生器的仿人机器人适应性行走控制.docx
版权申诉
179 浏览量
2023-02-23
20:17:57
上传
评论
收藏 728KB DOCX 举报


仿人机器人具有双手、双足、躯干等人类外形特征, 无需改造就能适应人类日常环境
和使用工具, 更容易成为辅助人类生活、工作和完成危险作业的帮手, 因此可认为是下一代
服务机器人最典型、最友好的本体特征. 行走控制是仿人机器人的基础科学问题, 但仿人机
器人自由度多、传感器多, 是一个不稳定的非线性强耦合动力学系统, 行走的自然性、环境
适应性、突发环境变化时的平衡控制是长期困扰仿人机器人发展和应用的难题. 目前, 行走
控制方法主要基于编程作业机制, 使得仿人机器人的本体特性不能得到充分的发挥
[1]
.普遍
采用的基于零力矩点(Zero moment point, ZMP)的步行控制方法
[2-7]
, 允许机器人按照预先设
计的轨迹行走并保持平衡, 但是由于预先设计的轨迹是固定的, 一旦地形发生变化, 则机器
人无法完成行走任务. 对于机器人的环境适应性行走控制, 需要具有自适应产生轨迹的能
力.
改变传统的思维模式, 研究和抽象生物的行走机理并加以模仿, 可能是突破机器人行
走控制瓶颈的有效途径. 该思想也引起相关学者的广泛关注, 其中, 比较著名的方法是基于
中枢模式发生器(Central pattern generator, CPG)的生物诱导的机器人行走控制方法
[8-13]
. 由于
其突出的适应性优势已经广泛应用在机器人运动控制中, 特别是在游泳、爬行、多足机器
人的运动控制中取得了成功实验效果
[14-21]
. 然而目前存在的 CPG 模型基本只能产生正弦或
类似正弦的输出, 如 Hopf 模型
[22-23]
、Kuramoto 模型
[24-25]
等. 即使存在能够在一定程度上调
整输出波形形状的模型, 如 Matsuoka 模型
[26-28]
, 但是模型参数与输出波形的形状之间没有
明确的对应关系, 只能通过试凑法不断地尝试. 并且只能对输出进行简单调整, 无法准确模
拟某一特定形状.在 Righetti 等
[29-30]
的工作启发下, 我们提出了一种基于快速傅里叶变换的自
学习 CPG (Self-learning CPG, SL-CPG)模型. 提出的模型可以学习周期性任意形状输入信号,
解决了以往 CPG 模型输出上的局限性.自学习 CPG 模型可以通过调整参数在线平稳调整其
输出频率和幅值, 为引入传感器信号提供了便利.
另一方面, 如何将 CPG 模型应用于机器人的节律运动控制是该研究的另一难点问题.
目前 CPG 机器人生物诱导控制方法应用较多的是关节空间控制法. 通常将一个 CPG 单元
分配给一个自由度, 优化 CPG 拓扑网络, 生成多维协调信号, 直接控制关节运动实现运动
控制. 关节空间方法在爬行、游泳、多足等机器人上取得了突出的研究成果. 但是仿人机器
人自由度多、结构复杂, 如果直接将 CPG 分配到机器人关节空间, 利用 CPG 之间的相互耦
合组成 CPG 网络, 网络庞大, 参数众多. 一些学者将 CPG 和进化算法结合来实现仿人机器
人的行走控制
[31-34]
, 参数的进化是 CPG 产生满足要求控制信号的关键, 但参数和 CPG 网络
的输出轨迹的关系并不直观. 部分学者探索在机器人的工作空间来有效利用 CPG 的适应性
[35-41]
, 取得了不错的实验效果.
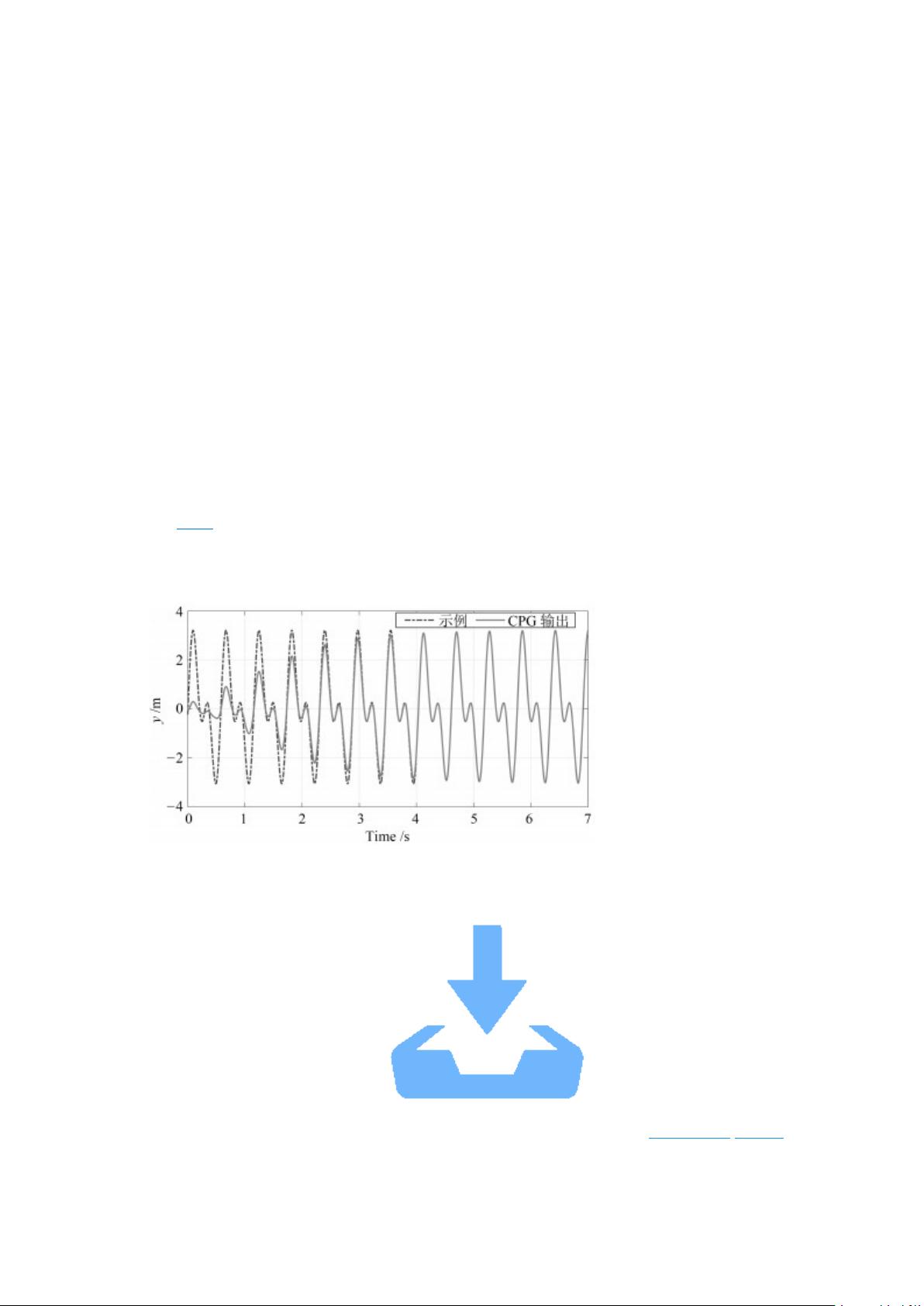
基于学者们的前期研究, 我们提出了生物诱导的仿人机器人工作空间行走模型. 本文
中, 我们采用自学习 CPG 模型在线生成仿人机器人质心和脚掌轨迹. 分别利用两组 SL-
CPG, 通过对示例轨迹的训练学习, 形成可以在线调制的轨迹生成器. 通过传感器测得机器
人自身姿态信息作为轨迹发生器的反馈输入, 因此可以根据具体的地面环境适应性调节输
出轨迹. 机器人的行走速度、腿的支撑段和摆动段的时间、迈步跨度和抬腿高度等可以实
时地调整, 这是实现环境适应性行走的重要前提条件. 基于工作空间的方法大大简化了



剩余25页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3749
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











