基于启发式深度Q学习的多机器人任务分配算法.docx
版权申诉
98 浏览量
2023-02-23
20:14:39
上传
评论
收藏 1.23MB DOCX 举报


随着人工智能的发展,多机器人任务分配或任务调度
[1-3]
(multi-robot task allocation,
MRTA)技术受到人们广泛的关注,而多机器人任务分配算法的准确性和时效性直接影响了完成
任务所产生的代价,具有很高的实际研究价值,近年来国内外很多学者对此进行了深入的研究
[4-6]
。
强化学习作为多机器人任务分配领域的一个重要研究方向,主要利用智能体与环境的实时
交互和错误判断机制,获得累积最大奖赏值的方式,训练出算法的最优动作决策序列
[7-8]
。随着
强化学习相关应用领域的快速发展,强化学习在解决单机器人智能决策问题上取得了辉煌的成
就
[9]
。传统的强化学习都是应用于单机器人决策,如何将单智能体强化学习应用到多机器人强
化学习中,国内外学者进行的大量的探索,主要的实现方法为基于值函数。基于值函数的多机
器人强化学习算法主要包括 Q 学习(Q-Learning)、分层强化学习(hierarchical reinforcement
learning, HRL)和深度 Q 学习(deep Q network, DQN)算法
[10-12]
,算法通过结合值函数和奖励函
数来模拟多机器人强化学习中机器人之间的协作和竞争,进而达到全局最优的策略效果。
针对复杂环境下分层强化学习处理多机器人任务分配存在的维度灾难问题。本文提出一种
启发式深度 Q 学习(heuristically accelerated deep Q network,HADQN)算法解决复杂环境下
多机器人任务分配的问题。该算法采用神经网络进行 Q 值的存储和计算,一定程度上避免了强
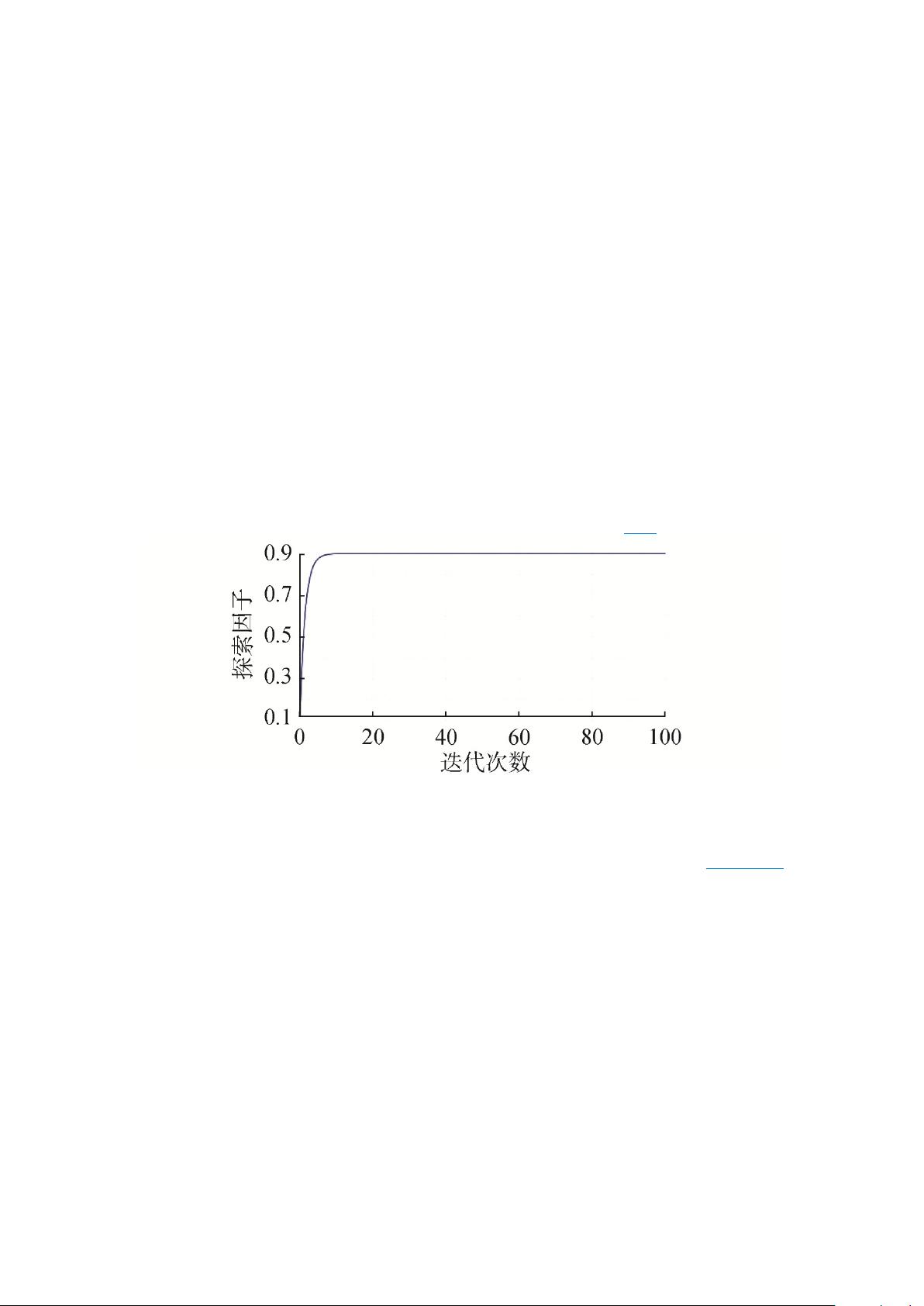
化学习的维度灾难问题;同时引入轨迹池机制和动态探索因子,在提高算法学习效率、探索能
力的同时,保证了算法的收敛性。
1. 基于 HADQN 算法的 MRTA 算法研究
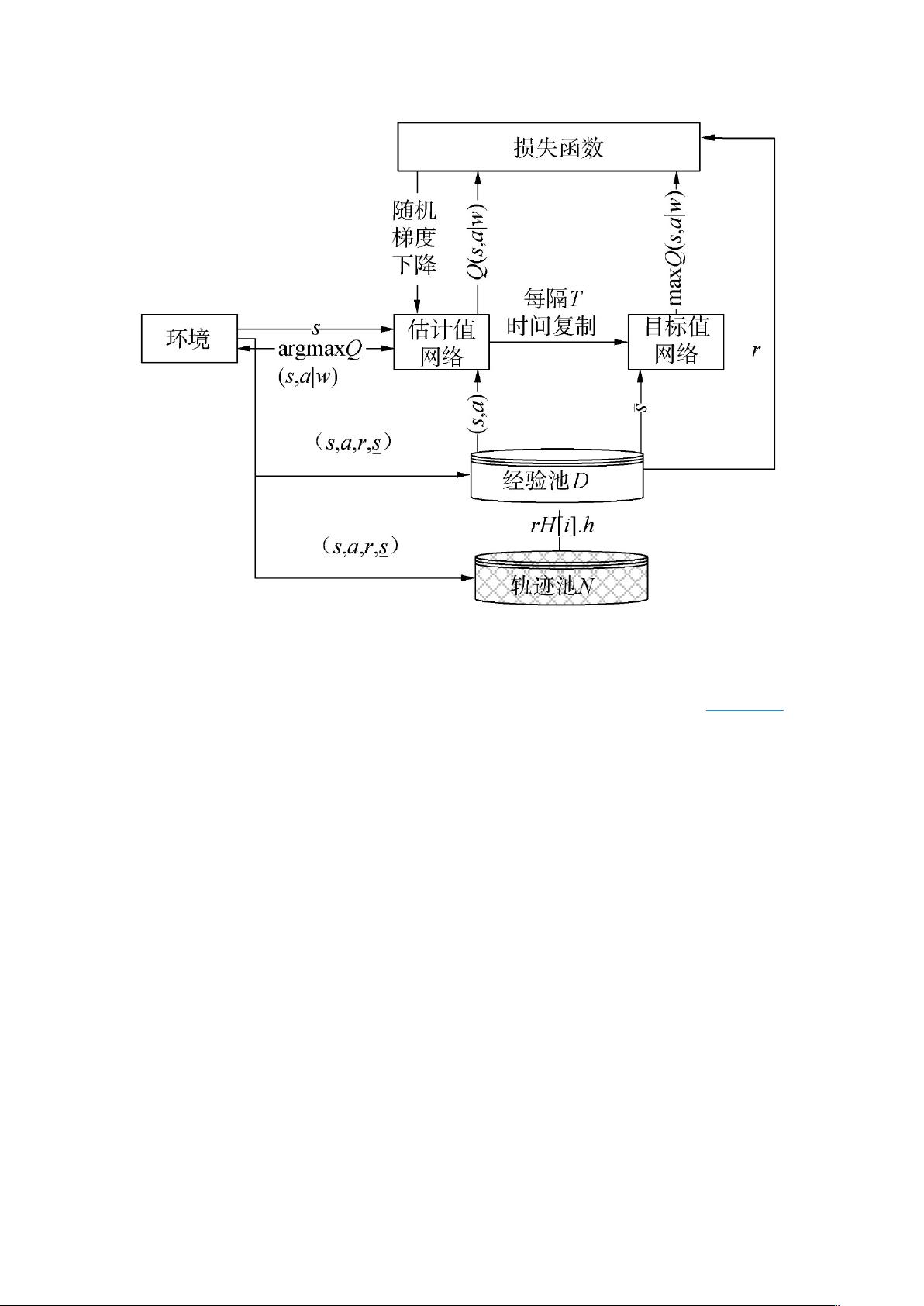
本文提出了可以处理实际应用场景的基于 HADQN 的多机器人多任务分配算法。如图 1
为 HADQN 算法在传统 DQN 算法的基础上引入了轨迹池更新经验池中的数据,促进了 DQN
算法对轨迹池中有效动作的选择。
剩余13页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3542
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











