基于RoBERTa-BiSRU++-AT的微博谣言早期检测模型.docx
版权申诉
34 浏览量
2022-12-01
09:06:21
上传
评论
收藏 545KB DOCX 举报


1. 引言
由于社交网络信息传播快速,谣言经社交媒体传播后,会对个人或者社会造成毁灭性
的后果
[1]
.舆论导向属于网络安全的重点问题,网络舆情表现方式主要为微博、新闻评论、
BBS 论坛等,而这些社交平台已经逐渐成为虚假信息的主要滋生场所,导致了严重的网络
安全问题.然而,从海量的微博社交信息中正确识别谣言正成为一项艰巨的挑战
[2]
.
谣言早期检测旨在谣言产生之初就进行检测,避免谣言传播带来的社会危害,微博谣
言早期仅有谣言原始文本,不存在转发和评论信息
[3]
.而传统的谣言检测需要结合大量的其
他信息特征如转发和评论信息才可以进行有效检测,具有滞后性.在微博谣言产生早期缺乏
大量转发和评论信息的情况下,如何使用原始微博文本进行有效的谣言检测,是未来谣言
检测的一个重要研究方向.目前关于社交网络谣言检测的研究多数基于深度学习方法.微博文
本谣言检测实质上是一个二分类问题.
文献[4]将微博内容文本矢量化,通过 CNN
[5]
(Convolutional Neural Networks)模型挖掘
文本深层特征,避免了复杂的特征构建过程.文献[6]充分结合时间序列信息,提出了基于
RNN
[7]
(Recurent Neural Natwork)的谣言检测模型.以上模型使用随机初始化 Embedding 层进
行文本向量化,无法较好地表示词的语义.
Word2vec
[8]
、Glove
[9]
等传统词向量工具舍弃了词的上下文信息,无法表示多义词.如
“苹果”,可表示水果中的苹果,也可以代表苹果手机,相同的词在特定上下文语境中有着
不同的含义.基于双向 LSTM 的 Elmo
[10]
、基于 Transformer 模型的 BERT
[11]
等预训练模型由
于其能够动态学习词在不同上下文语境下的语义表征,,故不存在多义词问题.RoBERTa
[12]
是基于 BERT 的改进版本,提出了动态掩码任务,调整了训练批次大小并加入了更多的数
据,在多个自然语言处理任务上取得最佳效果.
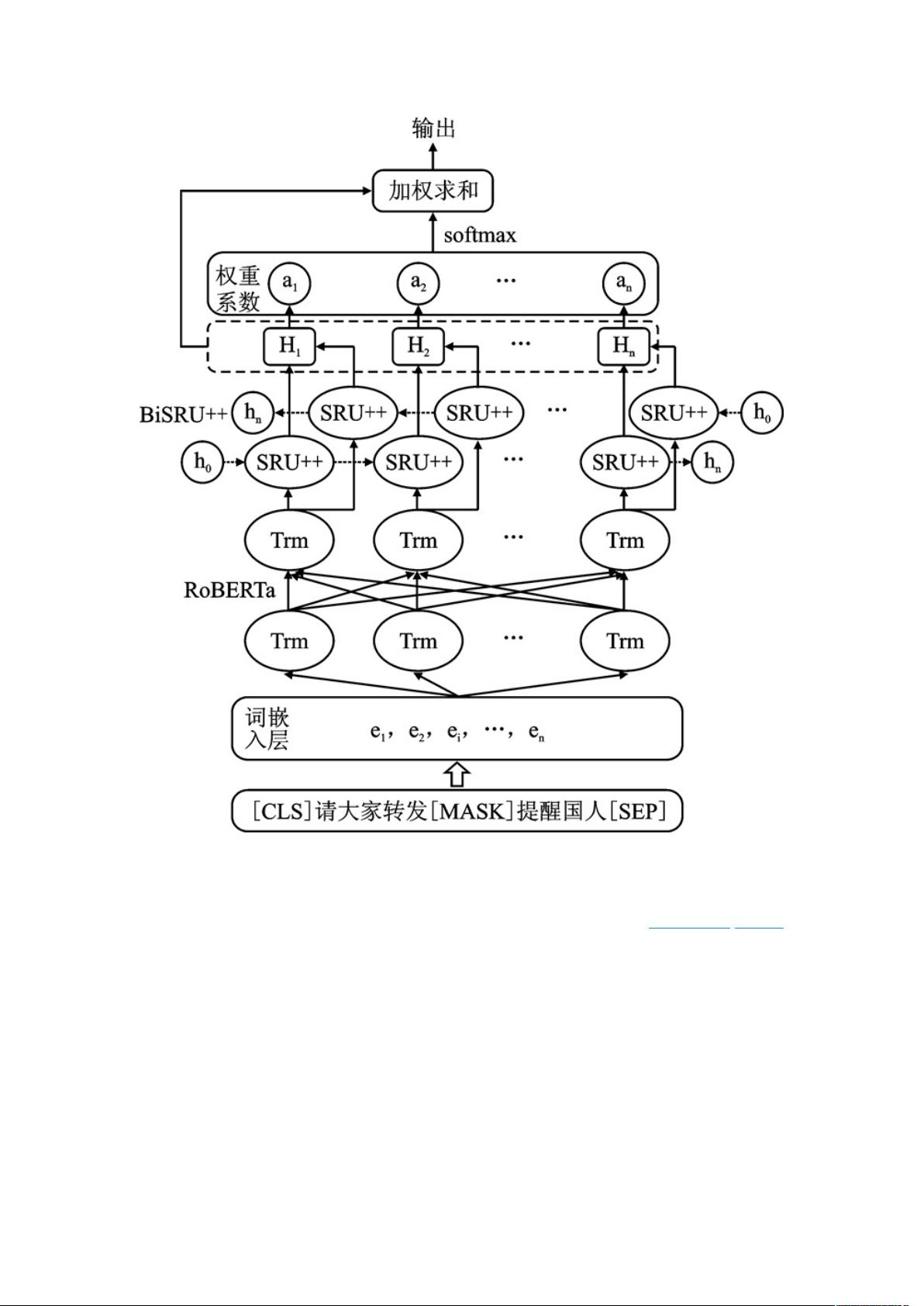
文献[13]提出了 BERT-RCNN 模型用于早期谣言检测,针对谣言检测的滞后性问题,
仅利用早期产生的微博原始文本进行谣言识别,在微博数据集上取得了不错效果,但通过
最大池化对 RCNN 模型输出进行特征选取,未考虑文本中每个词对分类结果的影响程度.文
献[14]提出了 BERT-CNN-Attention 谣言检测模型,将微博文本和其相对应评论合并作为输
入,由 CNN 捕获谣言文本局部复杂语义特征,再引入注意力机制赋予关键特征较高权
重,有效提升模型分类性能,但 CNN 缺乏对句子序列特征学习的能力,导致特征提取不
全面.在微博谣言文本中,如涉及到国家名称的“中国”、“日本”,或者关于散布谣言请求的
“请”、“转发”和目标对象“家人”、“朋友”,在谣言文本中一般占据较大比例,微博文本中每
个词对分类结果影响力应该是不一致的.因此,文献[15]将注意力机制融入 RNN 模型,计算
RNN 每个时间步隐状态输出影响力大小,有利于模型关注到对分类结果有着重要影响的
词,有助于提升模型谣言检测性能.文献[16]运用多头自注意力机制来进行谣言检测,从上
下文信息中提取特征并由 CNN 获取文本局部特征,将注意力机制应用到谣言检测,解决
了输出结果影响力的问题.文献[17]提出了 BERT-Att-biLSTM 模型,实现对医学健康信息文

剩余13页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3591
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











