基于中心点检测和重识别的多行人跟踪算法.docx
版权申诉


多行人跟踪一直是计算机视觉领域的研究热点,在监控安防、自动驾驶、场景解析、
动作识别等方面具有重要的应用价值
[1-4]
。真实场景中光照和尺寸变化,以及行人间频繁遮
挡等问题,给多行人跟踪研究带来很大挑战。
传统的多行人跟踪算法通常采用先检测再跟踪的两步法,如 Faster RCNN 算法
[5]
和
YOLOv3 算法
[6]
。两步法通常利用基于卷积神经网络(convolutional neural network, CNN)
的行人检测器进行定位,首先需要输入视频序列中的所有行人框,然后将框内裁剪图像输
入至下一个行人重识别网络提取特征,通过重识别特征和交并比(intersection over union,
IOU)计算距离代价矩阵,最后利用卡尔曼滤波和匈牙利算法将所有行人框关联成轨迹。文
献[1]提出 SORT(simple online and realtime tracking)算法,使用 Faster RCNN 进行检
测,并利用卡尔曼滤波器对状态进行预测。匈牙利算法基于检测帧位置和 IOU 进行轨迹跟
踪,计算速度快,但未考虑框内的目标特征,因此易发生身份变换。行人重识别可以增加
网络对行人消失和遮挡的鲁棒性,在多目标跟踪(multiple object tracking, MOT)任务中使
用 CNN 在大规模行人数据集上进行训练和提取行人重识别特征,增强了模型对行人身份
的辨别能力。文献[2]在多行人跟踪任务中引入行人重识别模块,提出了 Deep SORT 算
法,使用更可靠的深度关联度量来代替距离关联度量。对于短时预测和匹配,Deep SORT
引入了有效的距离度量;对于长时丢失的轨迹,行人重识别模块保留了行人外观信息。文
献[7]提出的(joint detecting and embedding, JDE)算法将行人重识别模型合并到检测器网
络中,摒弃了两步法的通用范式。多行人跟踪被当作一个多任务学习问题
[8]
,同时输出目
标在图像中的边框位置和检测帧中目标的表征嵌入,可加快多行人跟踪速度。但 JDE 算法
在行人相互遮挡情况下检测器效果较差,行人重识别过于依赖检测器的检测结果。
随着多任务学习的发展,已有许多研究提出了基于 JDE 一体化框架的优良算法,其
中多行人跟踪单步法通过检测器加重识别模块嵌入的框架解决了跟踪准确度和实时性的问
题
[9]
。文献[10]提出了一种基于管道的跟踪 Tube TK 算法,能够实现端到端的训练,将过
去单帧图像先检测后跟踪的框架改为多帧图像连成三维的管道数据,包含了帧内、帧间的
空间和时间信息,能有效应对行人尺度变化,同时对于行人运动也更具鲁棒性。这种基于
管道的模型在遮挡和低可见度条件下表现了良好的跟踪性能,但是 Tube TK 在 MOT15、
MOT16、MOT17 数据集上的跟踪速率分别只有 5.8 Hz、1.0 Hz、3.0 Hz,完全无法达到
视频实时跟踪要求
[10]
。
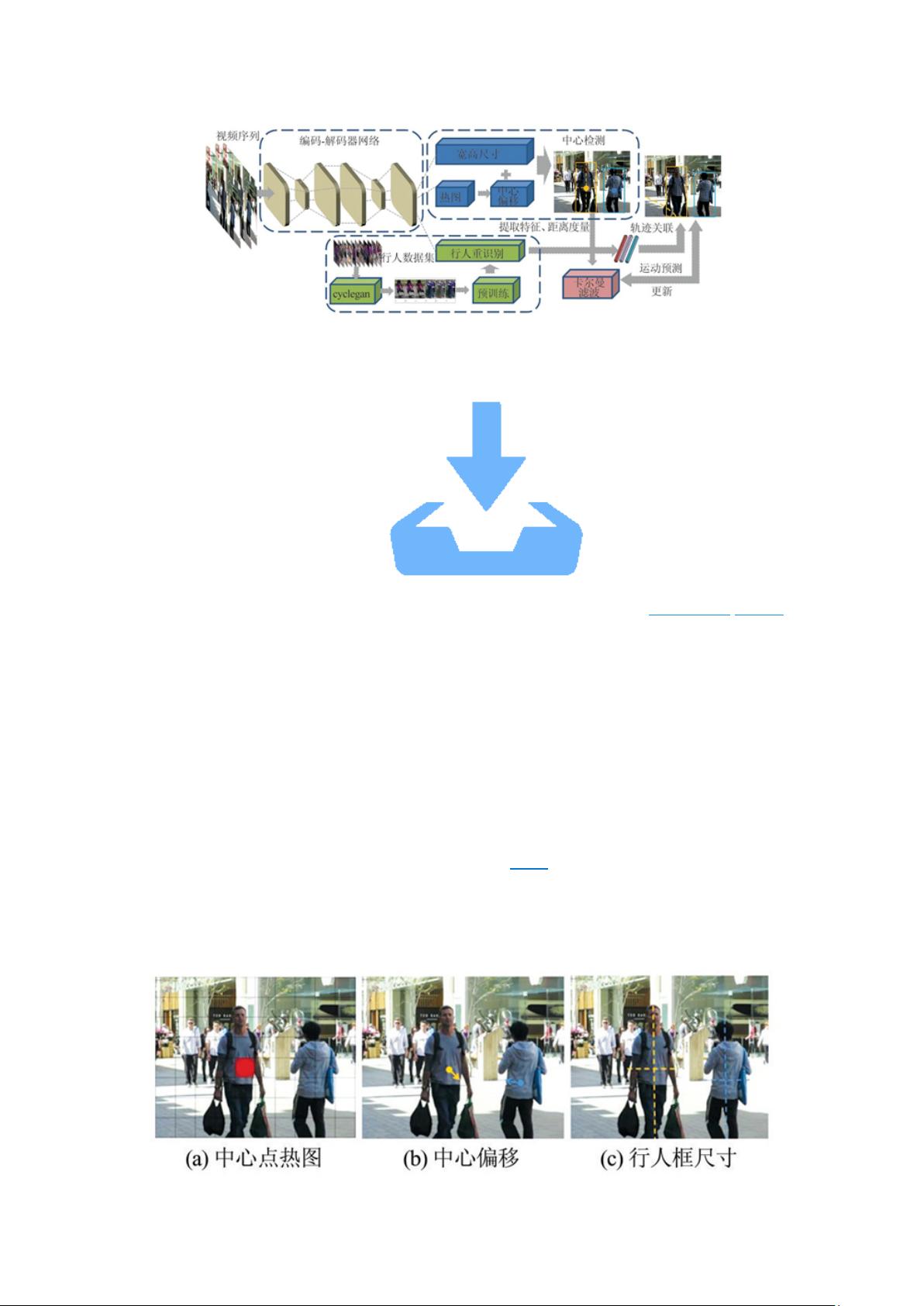
针对多行人跟踪两步法中的低实时性及行人身份切换频繁的问题,本文在单步法的框
架上融合了运动信息和外观信息,将行人重识别模块进行遮挡优化并嵌入行人检测网络
中,由此提出了一种基于中心点检测和重识别的多行人跟踪算法。该算法分为中心点检测
和行人重识别两个模块,整体框架如图 1 所示,两个模块使用同一个网络共享了部分参
数,以提高跟踪速度。同时针对过去的行人重识别相似性距离进行改进,提取到的行人外
观信息联合运动信息可提高跟踪的精准度。

剩余13页未读,继续阅读

罗伯特之技术屋
- 粉丝: 3959
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP


相关推荐
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论1
最新资源