融合启发式和Boosting的子图匹配基数估计方法.docx
版权申诉
131 浏览量
2022-11-28
20:30:47
上传
评论
收藏 290KB DOCX 举报


随着网络大数据的迅速发展,社交关系、知识表示等领域大放异彩。图数
据库作为一种描述关系数据的天然模型,已成为当前海量网络数据管理的解决
范式。因此,图数据管理技术也成为当前的研究热点。近年,以子图匹配为代表
的图数据上基础操作的性能得到了巨大提升。但是,一个完善的高吞吐的图数
据库系统还应具备自适应的任务调度能力;为了实现这个目标,图数据库系统需
要对系统中的任务进行代价估计——特别是对中间结果基数的尽可能准确估
计,从而优化多任务执行的序列与配置。本研究以子图匹配任务为例,研究针对
该任务的基数估计的有效方法。
子图匹配是图数据库管理、查询等各项工作中的基础操作。为提高子图匹
配操作的执行效率,现有研究对其执行过程进行了有效的剪枝、索引构建等优
化,但精确的子图匹配问题仍然是一个 NP 完全问题,随着待匹配结点的增多,匹
配将难以在有效的时间内完成。若能在匹配执行之前就能够尽可能准确地估算
匹配结果的基数,便可帮助实现对匹配执行过程和多个匹配任务的整体优化,对
于提升图数据库管理系统的效率和吞吐量意义重大。
当前,在关系型数据库管理系统领域,学者已经提出一些机器学习的方法和
传统的非机器学习方法来对查询结果的数据库查询任务的基数进行预测
[1,2,3]
,而
这些方法往往基于数据库的连接过程,无法直接应用到以图为结构的图数据库
匹配的基数估计工作中。另一方面,现有的用于子图匹配基数估计的部分研究
[4,5]
依赖于离线统计的方法,无法充分利用图数据中的结构信息,且没有一个适用
于多结点查询图匹配基数估计的框架。
鉴于此,本研究旨在设计一个通用方法来实现多结点查询图的预测框架,并
通过对图数据的结构信息建模、编码,应用 Boosting 学习的思想,实现鲁棒的多
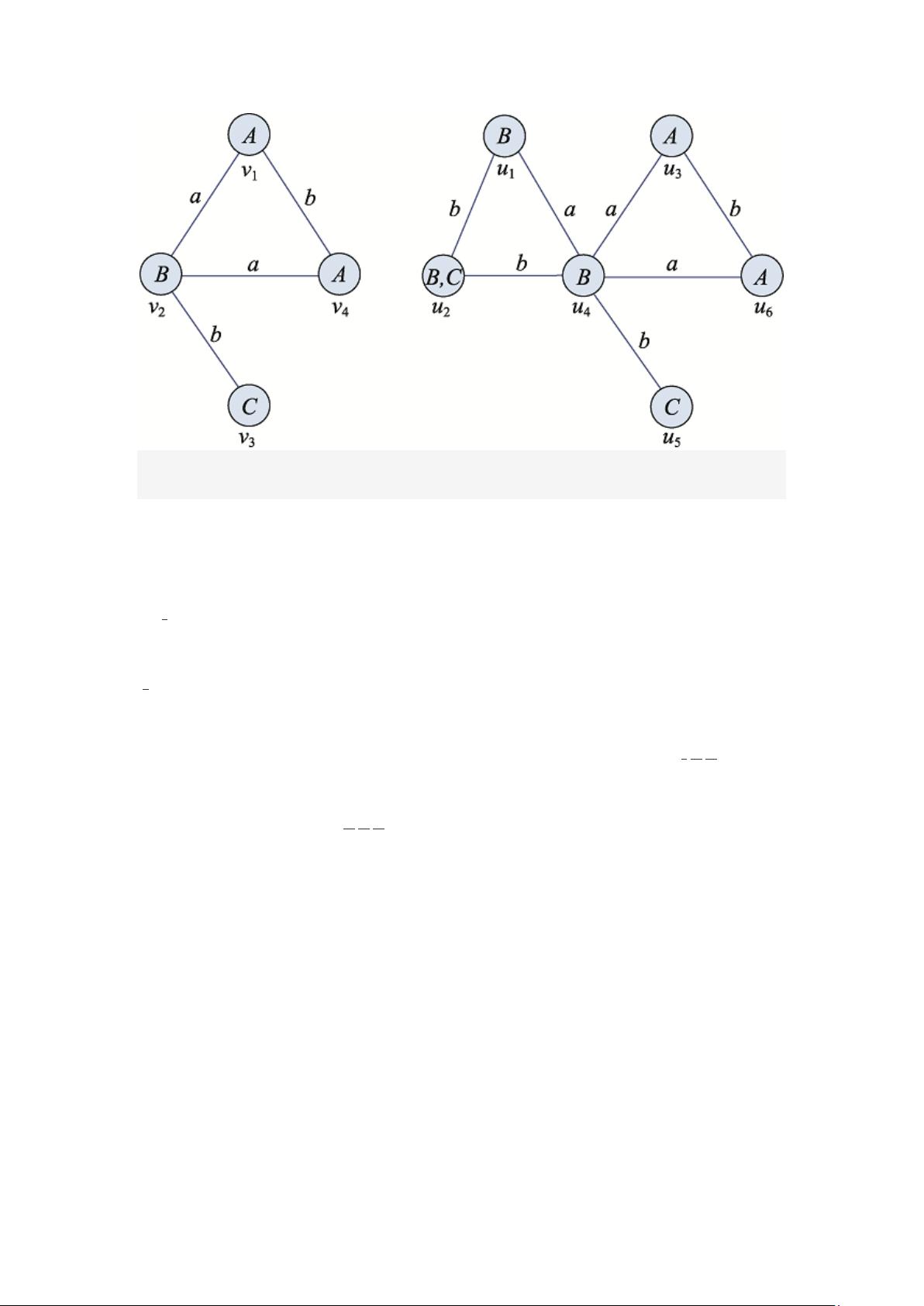
结点子图在大规模数据图中匹配基数的预测工作。具体地,提出 BoostCard 方
法,它首先针对数据图中结点的邻居信息建模,将结点分类并构建 相应索引,然
后对不同类型结点之间能否连成一边的概率进行预测,并基于上述信息,对多结
点子图的匹配基数进行预测,最后运用机器学习的方法对匹配结果的基数进行
补偿。
简言之,文章的主要贡献是将图数据的结构信息建模到子图匹配结果的基
数估计工作中,并根据 Boosting 学习思想,提出适用于多结点子图的匹配结果预
测方法(Boosting cardinality estimator,BoostCard)。

剩余16页未读,继续阅读

罗伯特之技术屋
- 粉丝: 3945
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP


相关推荐
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0
最新资源