MXNet框架中基于OpenCL核函数的多维线性数据处理.docx
版权申诉
179 浏览量
2022-11-02
16:44:29
上传
评论
收藏 306KB DOCX 举报


引言
随着信息产业的快速发展,相关的数据分析需求也在逐渐增加。深度学习
作为数据分析的主流方式,承担了绝大部分场景的数据处理和模型训练的任务。
但是,随着产业化背景下对模型精 度要求的提高,相应的模 型规模也在增大,建
立模型所需要的学习数据也在急剧增加,最终导致深度学习方法对算力资源提
出了更高的要求
[1]
。
为了应对这一问题,并行计算方法被大规模应用到深度学习中,其中比较主
流的便是在 GPU 上采取异步并行的方式对数据流进行处理
[2]
。根据费林分类
法(Flynn’s Taxonomy),GPU 计算模型满足单一指令流多数据流的计算模型,非
常适合用作深度学习任务并行执行的负载以及对相关任务执行的加速
[3]
。
在实际运用中,由于 OpenGL 等图形编程语言的使用门槛较高,在很长一段
时间内,通用 GPU 编程是很难实现的,直到 2007 年 NVIDIA 推出了 CUDA
[4-5]
框
架才将这一问题解决。CUDA 是一种新的操作 GPU 进行计算的软件和硬件架
构,它将 GPU 视为数据并行计算的设备,从而无需将这些计算映射到图形 API
中
[6]
。
与此同时,更加通用的 OpenCL
[7]
(Open Computing Language,即开放式运
算语言),作为一种统一的开放式异步并行运算平台也被提出。不同于 CUDA
架构,OpenCL 框架的目的是为异构系统提供统一的并行计算开发平台。简而言
之 ,CUDA 是 针 对 NVIDIA 公 司 的 GPU 及 相 关 生 态 所 构 建 的 计 算 平 台 , 而
OpenCL 是 一 种 更 加 通 用 的 计 算 框 架 。 因 此 ,在 本 项 目 的 条 件 下 ,我 们 选 择
OpenCL 作为深度学习框架移植的目标并行运算平台。本文就多维数据处理任
务在并行计算平台间的迁移问题提出了分析和解决方案。
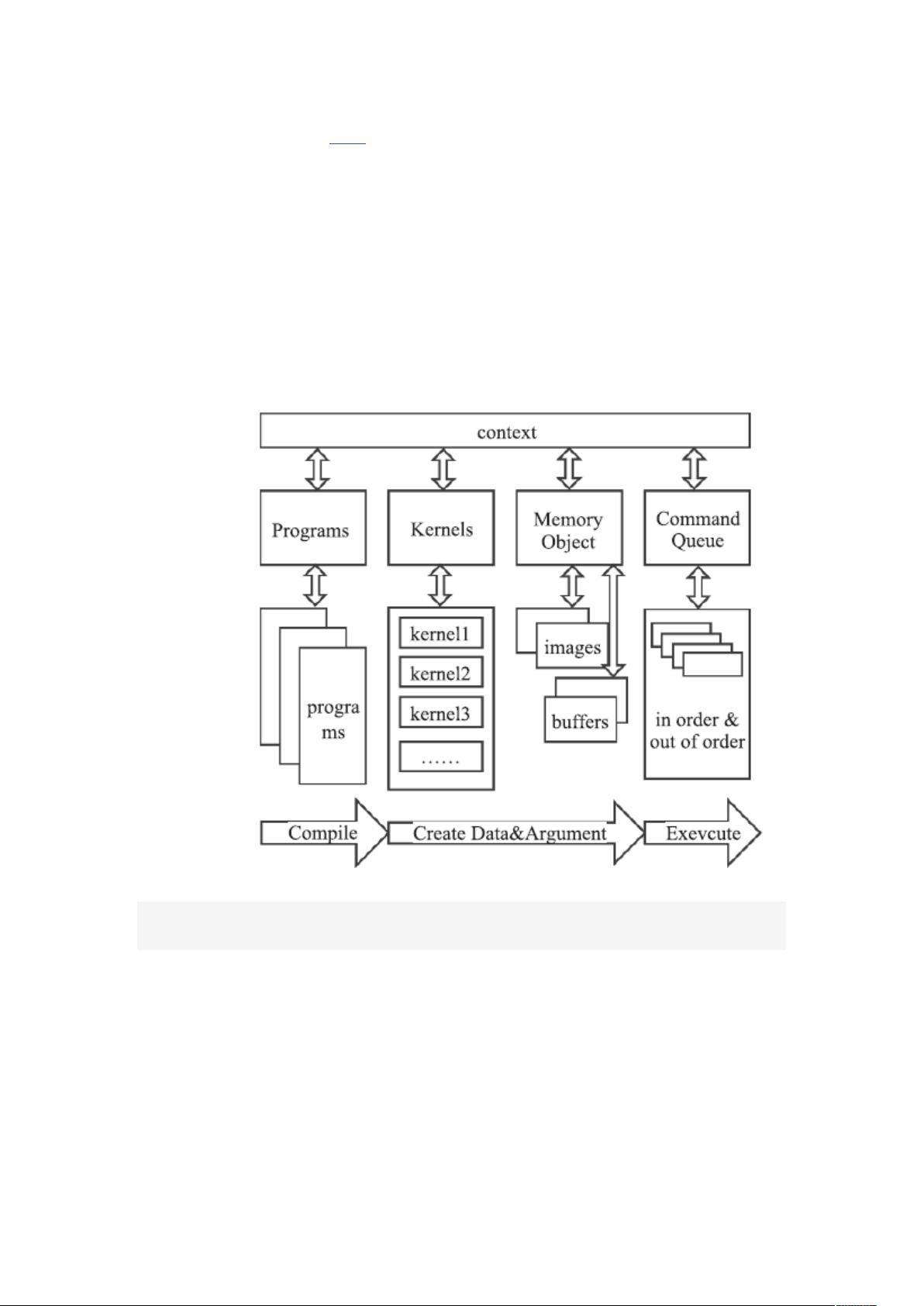
1 问题分析
1.1 并行计算平台运 行机制
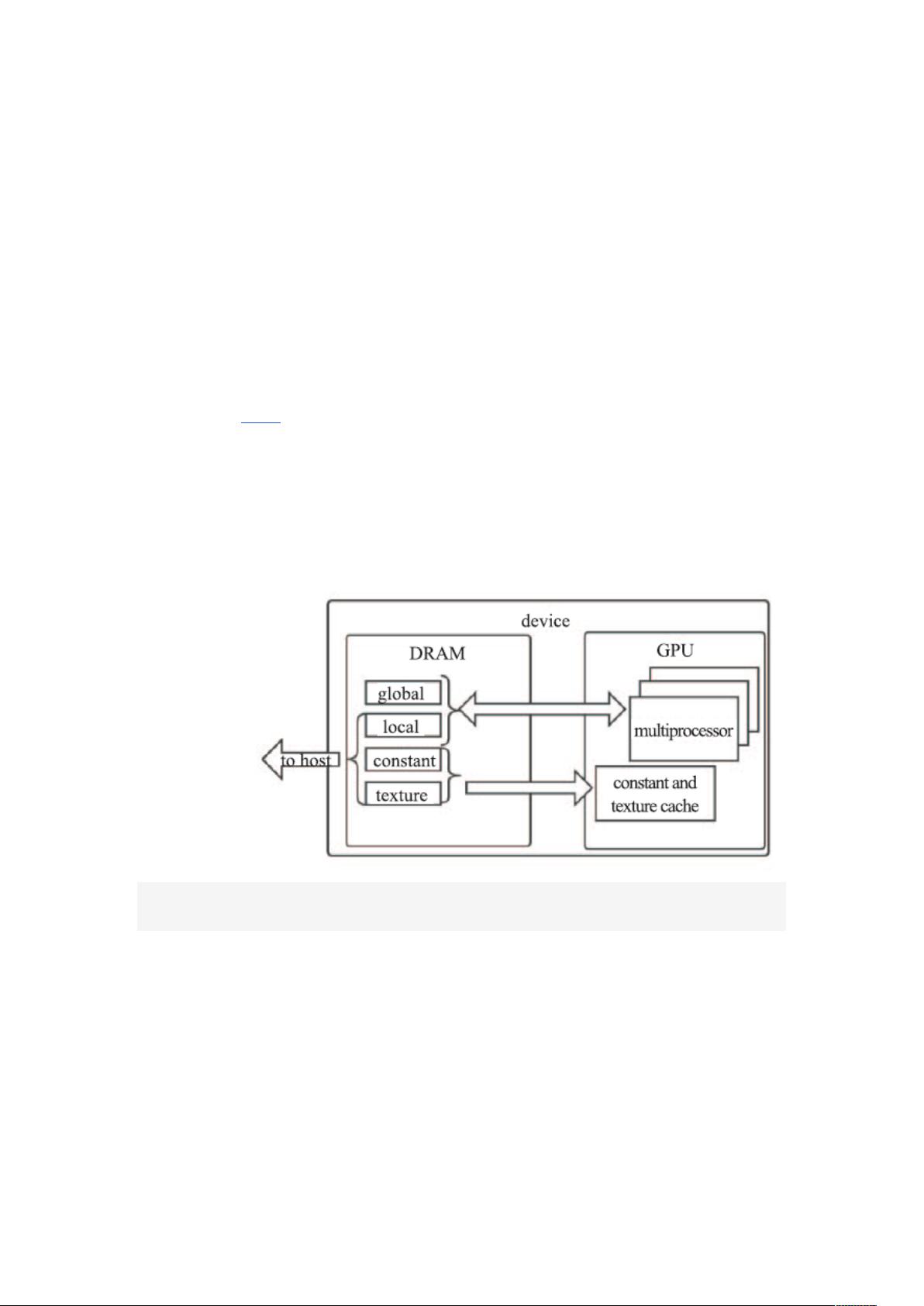
1.1.1 CUDA 并行运算平台
在明确多维数据在并行计算框架上的运行逻辑之前,我们需要了解不同并
行运算平台的差异
[8]
。首先,我们需要了解 CUDA 并行运算框架的编程模型,明
确在 CUDA 架构下,多维数据的处理是如何进行的。
剩余14页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3541
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











