深度学习的人-物体交互检测研究进展.docx
版权申诉
127 浏览量
2022-11-02
16:12:03
上传
评论
收藏 1.79MB DOCX 举报


随着信息技术的发展,计算机已经能够协助人们完成很多工作,帮助解决人
们无法解决的难题,甚至在某些领域已经可以取代人类。图像是人类获取信息
的主要形式,有 80%的信息都是以图像的形式获取的。常见的图像任务,如目标
检测、动作识别和图像分割等都属于计算机视觉任务的范畴。而近几年,这些
任务也随着深度学习在计算机视觉领域的深入应用得到了快速发展。在此基础
上针对个体对象更高层的图像语义研究,如人的动作识别、姿态估计等也取得
了较为明显的进步。但是仅凭这样的个体对象识别还远远不能理解图像中发生
的事情,还需要识别出不同对象之间的关系。由于人与物的交互占据了大多数
的人类活动,检测和识别每个人与周围物体的交互方式对于有效理解图像内容
十分重要,这个任务被称为人-物体交互检测
[1]
,主要目的是定位人体、物体,并识
别它们之间的交互关系。简单来说,就是检测图像中的<人体,动词,物体>三元组,
如图 1 所示。这样的输出能够帮助回答很多与图像相关的问题。它可以告诉更
多关于图像中描绘的场景的当前状态,帮助更好地预测未来,还能够反过来帮助
理解动作。人-物体交互检测(human-object interaction,HOI)技术已经被运
用在监控视频的自动识别检测中,识别检测出视频图像中的异常行为,做到及时
预警
[2]
。此外,该技术对于智能交通、信息检索以及人机交互
[3]
等诸多领域的研
究有重要帮助。
图 1



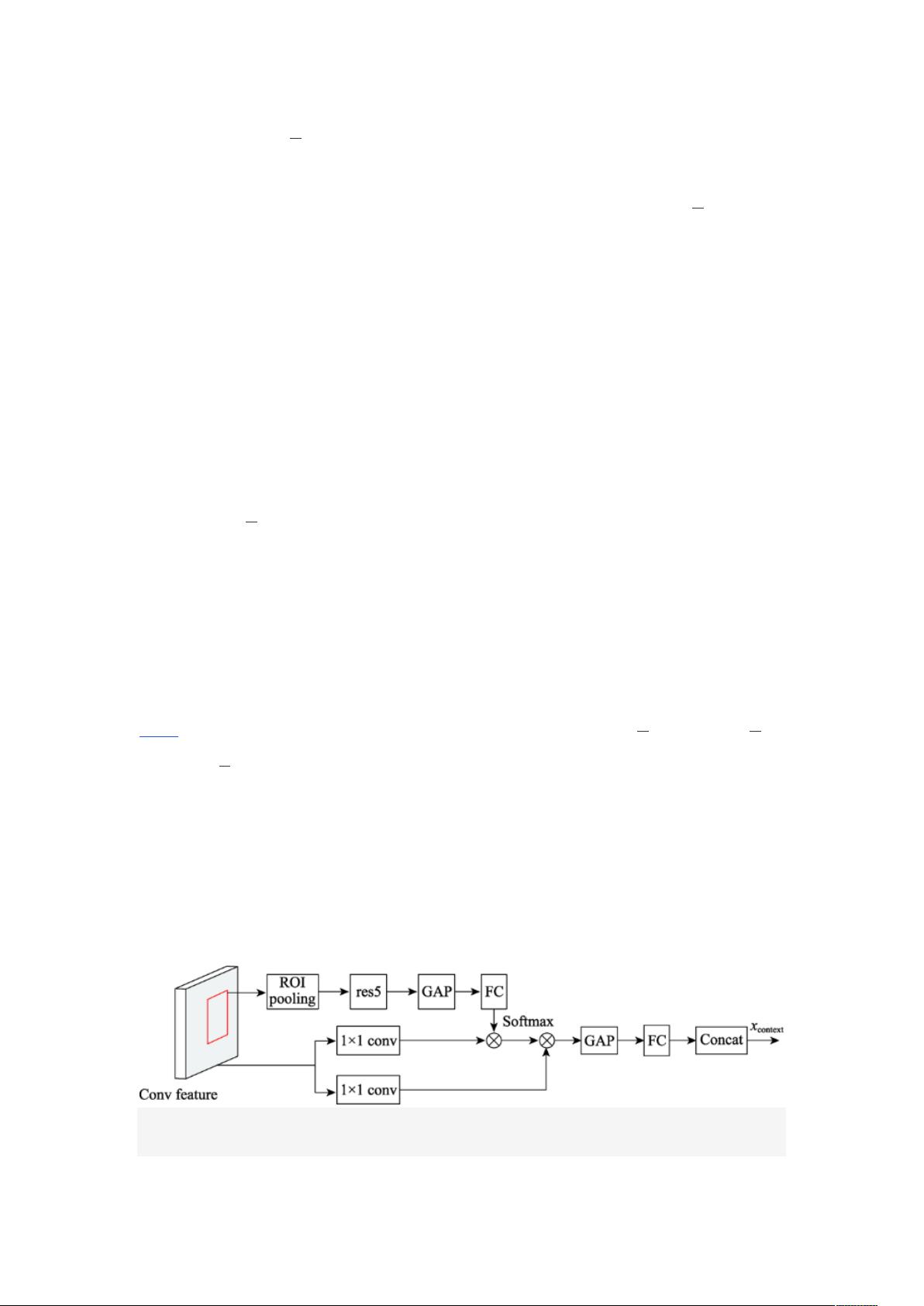
剩余21页未读,继续阅读

罗伯特之技术屋
- 粉丝: 3691
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP


相关推荐
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0
最新资源