基于不确定性损失函数和任务层级注意力机制的多任务谣言检测研究.docx
版权申诉
11 浏览量
2022-06-26
15:02:13
上传
评论
收藏 379KB DOCX 举报

1 引言
近年来互联网科技发展迅速以微博、知乎、论坛等为代表的社交媒体在信
息传播方面扮演着越来越重要的角色。人们仅仅需要一台移动通信设备 便可在
社交平台上发布和传播信息。每天数以亿计的信息在各个平台自由流动 为谣言
的产生和传播提供前所未有的有利条件。而谣言通常被认定为为达某种目的而
被凭空捏造的信息。这类信息的传播可能会对社会生活、经济、政治等各个方
面带来重大影响因此谣言识别一直是亟待解决的热点和难点问题。
等
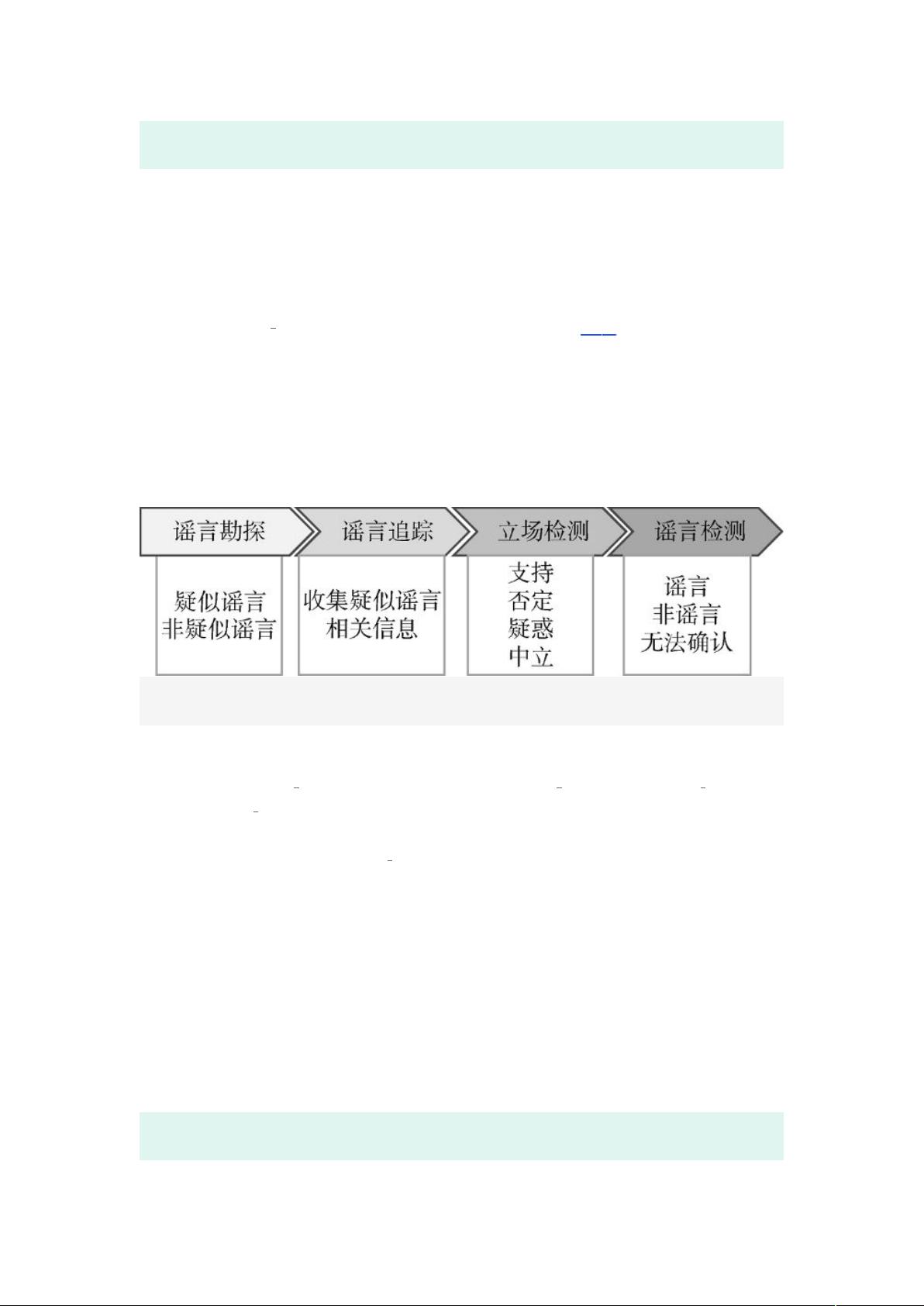
将谣言识别细分为以下 个子任务如图
所示。谣言勘探:该
任务从海量的文本中将无法辨别真伪的信息筛选出来 这些信息被视为疑似谣言
文本并在接下来的任务中做进一步判别谣言追踪:一旦疑似谣言信息被确认之
后关联追踪其相关信息包括但不限于评论信息和用户相关信息立场检测:通过
疑似谣言下的相关评论确定用户的态度谣言检测:作为谣言识别的最终步骤用
于判断疑似谣言的真假。
图
图 1谣言识别流程
Fig.1Rumor Identification Process
目前国内外对于谣言识别研究主要聚焦于单一的谣言检测任务采用基于内
容的谣言检测方法
通过谣言传播过程的文本特征
、用户内容特征
以及随时
间变化的趋势
进行谣言识别。但谣言识别研究中多个任务如何相互作用如何将
各个任务作为一个整体以有效地解决谣言问题是一个十分值得探究且有意义的
课题。已有的多任务谣言检测
研究对于各个任务的层次关系的界定都是通过
人工设定各个任务的权重将任务划分为主任务和辅助任务。该方法存在以下不
足:首先各个任务间设定一个合理的权重关系需要对于数据分布有着深刻的理
解和大量的实验基础其次当模型更换不同的数据集各个任务间的权重是否需要
发生变化有待考究。因此人工划分主任务和辅助任务是否具有必要是一个值得
讨论的问题。
基于以上问题本文通过引入同方差不确定性对损失函数加以优化并使用层
级注意力机制对模型加以改进使模型在训练不同的数据集时自发寻找任务之间
的最优权重避免人工划分主任务和辅助任务最终得到满意效果。本文以谣言检
测为解决谣言问题的关键步骤联合谣言勘探和立场检测任务构建基于不确定性
损失函数和任务层级注意力机制的多任务神经网络模型。
2 研究现状



剩余15页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3541
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











