基于注意力机制的多特征融合人脸活体检测.docx
版权申诉
170 浏览量
2022-11-03
12:06:09
上传
评论
收藏 513KB DOCX 举报

0 引言
随着信息技术向智能化的不断迈进,人脸识别技术得到了极大的普及与发展,在访问控制和登录系
统等方面得到了广泛的应用. 但大多数现有的人脸识别系统非常容易受到人脸欺骗攻击的影响. 人脸欺骗
攻击指的是非法用户试图通过某种欺骗手段绕过人脸认证系统和人脸检测系统. 因此,在人脸识别系统中
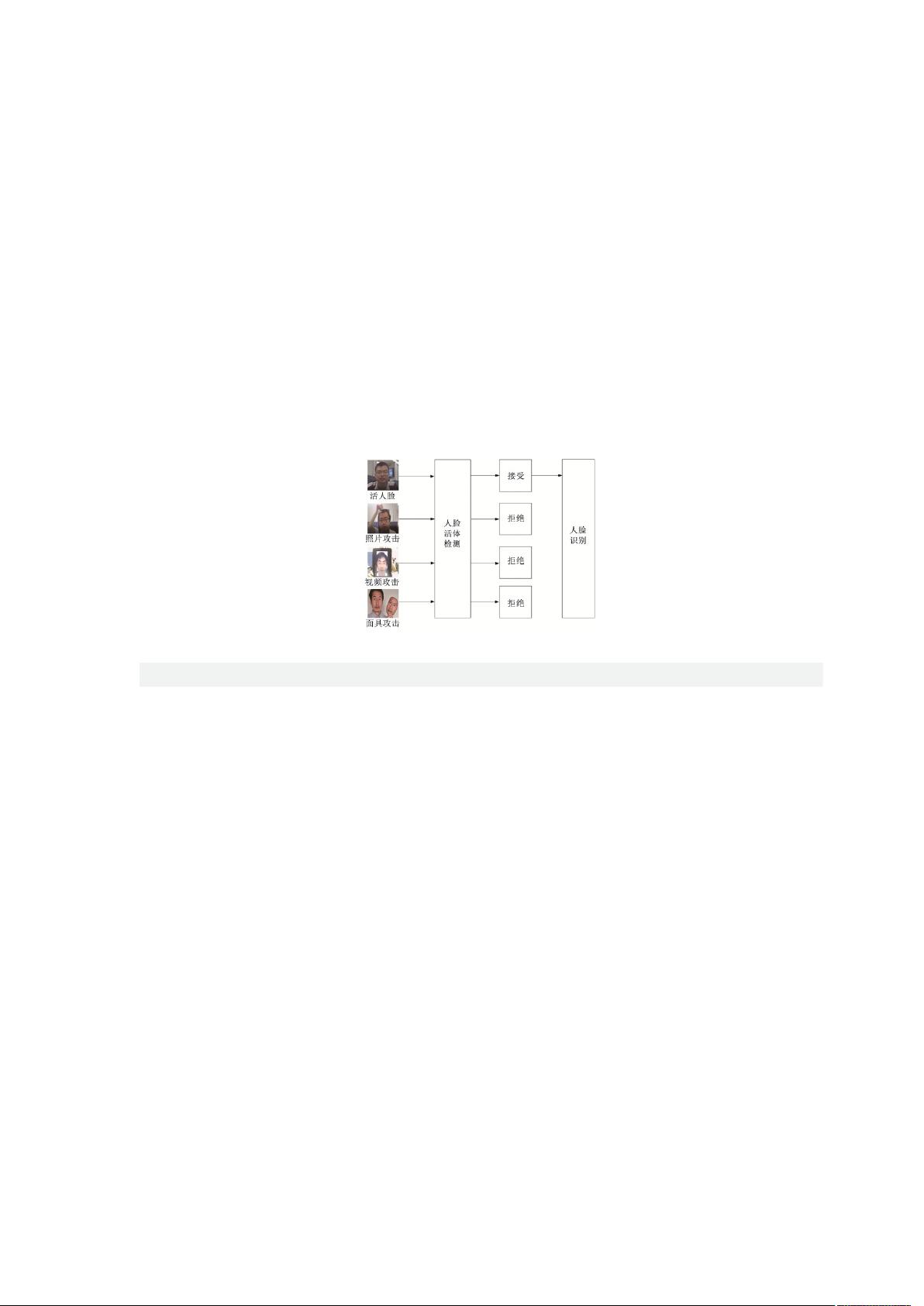
要加入人脸活体检测环节来抵御这些欺骗攻击. 如图 1 所示,只有被人脸活体检测系统判断为活体时才会
被接受,并进行下一步的人脸识别
[1]
. 常见的欺骗攻击如打印的照片攻击
[2]
、各种智能电子设备重放的视
频攻击
[3]
、3D 面具攻击等
[4]
. 照片攻击指的是攻击者首先通过互联网平台获取合法用户的人脸图像、偷拍
合法用户的人脸图像或者从视频中截取一部分图像,然后通过打印照片或者纸张形式呈现给认证系统的攻
击. 重放的视频攻击指的是非法用户通过视频重放进行的攻击,来显示几乎与真实人脸活体具有相似的行
为. 面具攻击是攻击者制作真人的塑料面具或者硅面具来进行攻击
[5]
.
图 1 人脸欺骗攻击和人脸活体检测任务 Fig.1 Face spoofing attacks and face liveness detection task
图选项
人脸活体检测是生物识别和计算机视觉的基本问题之一,只有检测到真实人脸才能进行下一步工
作,否则,便将其视为欺骗攻击.
为了确定在摄像机前呈现的人脸是真实人脸,还是虚假欺骗的人脸攻击,许多学者已经提出了很多
有研究价值的人脸活体检测方法,基本可以分为:基于人工设计特征的方法、基于深度学习的方法和基于
融合策略的方法这三类
[6]
.
在最初的几年里,基于手工设计的特征的方法更加普遍. 例如基于纹理的特征,Li 等
[7]
利用傅里叶
谱分析发现了二维图像和三维图像的纹理差异,二维图像和三维图像的频率分布不同,在频域上对人脸的
真假进行判断,虽然傅里叶频谱分析方法相对简单,但仅使用频谱分析的算法的鲁棒性不强,且容易受图
像光照和分辨率等的影响. Määttä
[8]
等采用局部二值模式(local binary patterns,LBP)来描述图像的微观纹
理信息,进行活体检测,这种局部特征方法的优点是算法快速,对光照强度改变的鲁棒性较好,不足之处
是对位置方向的改变和声音方面的敏感性都不是很突出. 文[9]提出一种基于 LBP-TOP 的算法,将图像的
空间和时间信息进行结合,成为一个单一的多分辨率纹理描述符的检测攻击策略,其性能优于文[8]中基于
LBP 的方法. 还有其它的特征,如高斯差分(difference of Gaussian,DOG)
[10]
、尺度不变特征转换(scale-
invariant feature transform,SIFT)
[11]
、加速稳健特征(speeded up robust features,SURF)
[12]
等,都是对
欺骗检测有意义的特征. 虽然这些基于手工设计特征表达的方法也能取得不错的活体检测效果,但对不同
的光照、姿态和特定的身份对象比较敏感,特征描述子的层次较低,且这些方法不能捕捉到活人脸和欺骗
人脸之间最具区别性的线索.


剩余12页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3571
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











