

1 引言
面对海量文本,如何快速、精准地获取最有价值的信息是一个有着重要意义
的研究,信息抽取技术应运而生。关系抽取作为其重要的子任务,主要负责从无结
构文本中识别出实体并抽取实体之间的语义关系,最终生成实体关系三元组,即<
主实体,关系,客实体>。获取的三元组及其关联关系能够为知识图谱、智能搜索
引擎、自动问答等任务提供内容支持。关系抽取的研究对篇章理解、自动摘要
生成等领域也蕴含深刻意义,具有广阔的应用场景。在基于深度学习的有监督关
系抽取范畴下,当前主流的方式有流水线学习方法和联合学习方法。相较之下,后
者可以避免误差传播及信息冗余且能提取任务间存在的关联性 ,但若采用统一标
注的联合方法,在一定程度上会忽略语句的内部结构。另外,当下对于同一实体参
与多个三元组的单实体重叠和同一实体对之间存在多个关系的实体对重叠问题
还有待进一步探究。
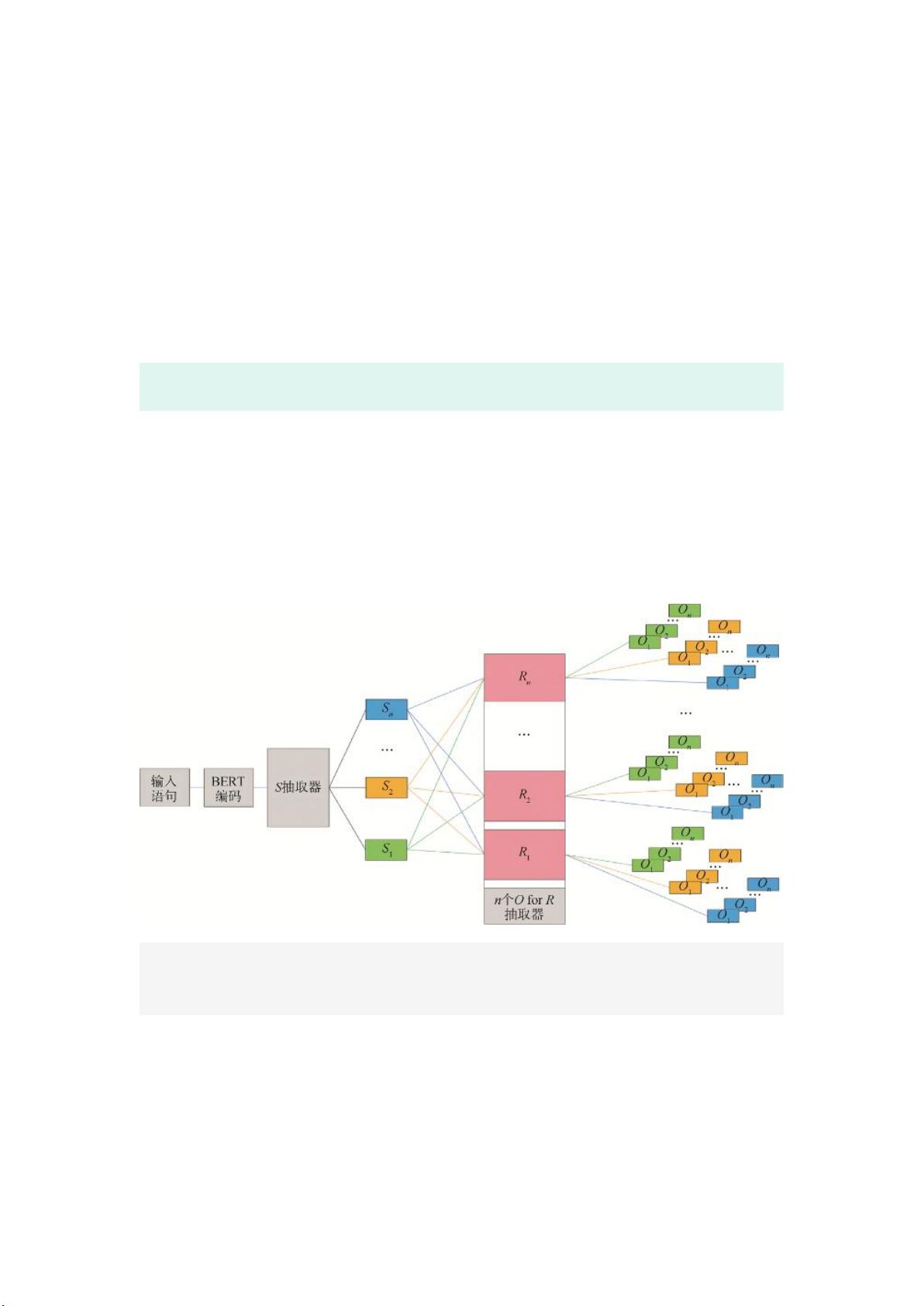
为了更全面、更有效地抽取实体关系三元组,本文设计了一种辅以位置感知
的标记方法抽取实体关系三元组,属于共享参数的联合抽取方式。不同于此前研
究中大多将关系视为离散标签进行分类并与实体识别作为两种独立任务分别处
理,本文使二者融合为一个分步标记过程,将关系作为预设属性,通过分步标记出主、
客实体得到三元组。模型设有两类抽取器,一类用于确定主实体 S,另一类用于确
定关系 R 和其对应的客实体 O。处理流程是先抽取出所有 S,然后将其逐一送入
具有不同关系属性 R 的抽取器中抽取相应的 O。这种方式为所有主实体和客实
体提供了在每种关系下组合的机会,涵盖了包括单实体重叠和实体对重叠在内所
有可能的三元组,因而能妥善处理重叠情况。为提升抽取效果,本文结合自然语言
形态结构特点设置了多重位置感知信息作为重要辅助。另外 ,考虑到不同抽取过
程所需特征有差异,模型结合注意力机制优化了编码的共享方式。相较于其他基
线模型,本文方法在中文公开数据集 DuIE 上取得了最佳抽取结果,并通过消融研
究证实了各辅助模块的有效性。
2 相关研究
2.1 传统方法
早期的关系抽取经历了移植性较差且成本高昂的人工构造语法及语义规则
来进行模式匹配的方法、灵活性差且局限性大的词典驱动方法以及比较复杂的
基于本体的方法。这些方法能够处理的文本规模比较小,在具有复杂词法和句法
的中文领域更是成效甚微。为解决种种限制,研究人员将注意力投向以特征为核
心的传统机器学习方法,如有监督抽取领域中的基于特征向量和基于核函数的方
法。虽然取得了不错的效果,但是有监督的机器学习方法依赖人工构建,且处理复
杂耗时久,难以扩展至大规模文本中。
2.2 深度学习方法
深度学习的概念是在 2006 年由 Hinton 等
[1]
首次正式提出的。基于深度学习
的抽取方法能够自动提取特征,减少对人工的依赖,且具有良好的泛化能力,可用于

剩余12页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 4459
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


