

1 引言
针对特定细分领域新闻开展技术监测是科技情报工作中常见的任务 ,新闻文
本的自动分类又是其基础。区别于传统的以粗粒度主题(如娱乐、体育、军事
等)为分类依据的新闻分类体系,细分领域新闻分类是指针对某一领域的子领域
新闻根据特定任务需要构建细分分类体系并分类,如体育新闻可以根据体育项目
不同划分为足球、篮球、乒乓球等细分领域。与涵盖广泛主题的开放域文本不
同,细分领域文本存在语义区分度低、再细分类目预设困难、优质现成语料稀缺
而人工标注难度较高等一系列问题,使传统面向开放域的文本分类方法难以直接、
有效地应用于细分领域新闻分类上。
由于在大多数细分领域中缺乏针对新闻分类的标注语料 ,因此细分领域新闻
分类任务是一个典型的低资源自然语言处理问题,其难点主要集中在两方面:一
方面,细分领域新闻的类目划分受资源内容分布情况决定,现有分类法中的类目不
适合网络新闻分类,即使是领域专家参与,也难以在未经资源调研的状态下设计出
能有效概括指定领域新闻内容的类目;另一方面,常用的文本分类算法往往依赖标
注语料作为训练集,而大多数细分领域缺乏优质的已标注文本分类语料,且由于数
据集不平衡、长短文本并存、主题区分度不高
[1]
等客观问题的存在,使人工标注语
料成本过高。
上述问题导致在细分领域新闻分类任务上难以直接运用通用的文本分类算
法,且即使人工参与,其效率也较为低下。因此,如何降低类目设置和语料标注的成
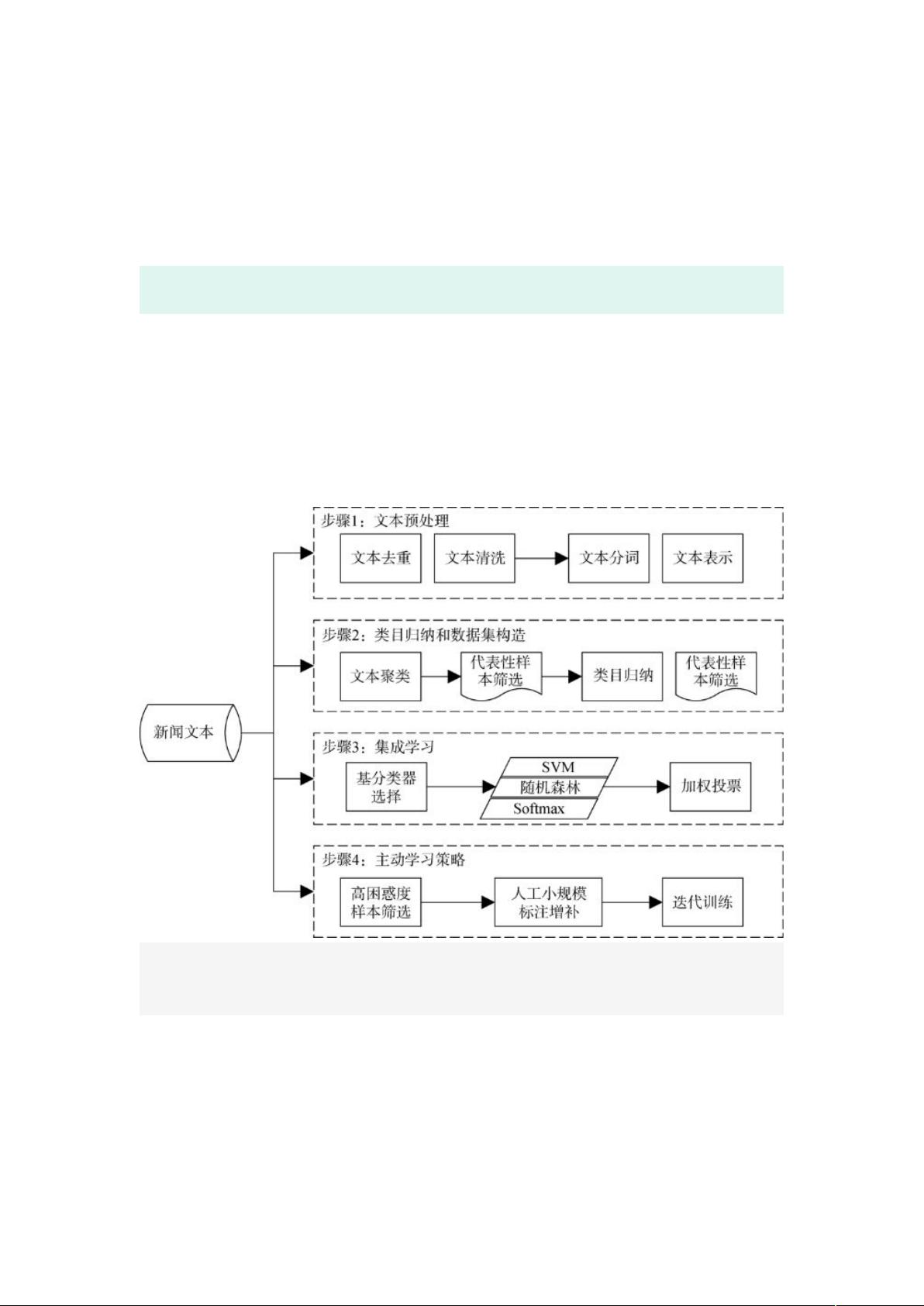
本并提高分类器泛化性能是需要解决的关键问题。因此 ,本文提出一套完整的融
合半监督学习和主动学习的低成本细分领域新闻分类方案。其思路是通过文本
聚类筛选代表性新闻以辅助专家设定类目,并在代表性样本构成的训练集上使用
集成学习训练初始分类器,最后利用主动学习方法迭代优化初始分类器。
2 相关研究
2.1 细分领域新闻分类相关研究
新闻文本分类研究主要分为两种:一种是采用以政治、军事、娱乐等作为
分类大纲,以主题为主的粗粒度分类体系,这类研究主要以新闻文本作为实验对象
来判定分类算法的可靠性
[2,3, 4]
;另一种则是以舆情监测、情感分析、情报追踪等实
际需求为背景,针对特定领域新闻构建细粒度分类体系和分类模型,以解决实际任
务。例如,在公共安全领域突发事件新闻分类研究中,张永奎等
[5]
和杨丽英等
[6]
依据
《国家突发公共事件总体应急预案》构建公共安全领域突发事件细分分类体系,
并采用传统的有监督机器学习方法,基于类别关键词构建文档向量空间,对公共安
全领域突发事件新闻进行分类;夏华林等
[7]
在此细分分类体系的基础上构建类别关
键词规则库,将规则与统计方法相结合,进一步提高了公共安全领域突发事件新闻
分 类 的 效 率 和 准 确 率 ; 宋 英 华 等
[8]
则 采 用 深 度 学 习 方 法 , 将 卷 积 神 经 网 络
( Convolutional Neural Networks,CNN ) 、 长 短 期 记 忆 网 络 ( Long Short-
Term Memory,LSTM)和多层感知机(Multi-Layer Perceptron,MLP )融合构
建集成模型,显著地提升了分类模型对公共安全领域多级突发事件新闻的识别与
分类效果。此外,葛艳等
[9]
采用 BiLSTM 并结合注意力机制对化工领域新闻进行分

剩余11页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 4494
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 使用python爬取数据并采用Django搭建系统的前后台,使用Spark进行数据处理并进行电影推荐项目源码
- 基于C++的简易图书管理系统(含exe可执行文件)
- Python毕业设计基于知识图谱的电影推荐系统源码(完整项目代码)
- 国际象棋棋子检测3-YOLO(v5至v9)、COCO、CreateML、Darknet、Paligemma、TFRecord数据集合集.rar
- Hadoop复习资料题库.zip
- 基于python和协同过滤算法的电影推荐系统
- 基于resnet的动物图像分类系统(python期末大作业)PyQt+Flask+HTML5+PyTorch.zip
- 电动蝶阀远程自动化控制系统的构建与应用
- 使用机器学习算法基于用户的社交媒体使用情况预测用户情绪
- jQuery信息提示插件
- 国际象棋棋子检测8-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- 2023最新仿蓝奏云合集下载页面系统源码 带后台版本
- Cisco Packet Tracer实用技巧及网络配置指南
- 基于SpringBoot+Vue的家具商城系统设计与实现(编号:97913147)(1).zip
- 基于springboot+vue的大学生创业项目的信息管理系统(编号:96166263).zip
- 基于Springboot的本科实践教学管理系统(编号:1407703).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


