# boris-spider

## 重要声明
⚠️⚠️⚠️ 本框架已重命名为feapder,本项目已废弃,直接看新项目即可
新项目地址:[https://github.com/Boris-code/feapder](https://github.com/Boris-code/feapder)
文档地址:[https://boris.org.cn/feapder](https://boris.org.cn/feapder)
## 简介
**boris-spide**r是一款使用Python语言编写的爬虫框架,于多年的爬虫业务中不断磨合而诞生,相比于scrapy,该框架更易上手,且又满足复杂的需求,支持分布式及批次采集。
官方文档:https://spider-doc.readthedocs.io
爬虫开发的一些经验分享:https://mp.weixin.qq.com/s/cIUNatRCUtlAi0HAkbmcwA
## 特性
### 1. 支持周期性采集
周期性抓取是爬虫中常见的需求,如每日抓取一次商品的销量等,我们把每个周期称为一个批次。
这类爬虫,普遍做法是设置个定时任务,每天启动一次。但你有没有想过,若由于某种原因,定时任务启动程序时没启动起来怎么办?比如服务器资源不够了,启动起来直接被kill了。
另外如何保证每条数据在每个批次内都得以更新呢?
本框架支持批次采集,引入了批次表的概念,详细记录了每一批次的抓取状态

### 2. 支持分布式
面对海量的数据,分布式采集必不可少的,本框架原生支持分布式,且可随时重启爬虫,任务不丢失
### 3. 完善的报警机制
为了保证数据的全量性、准确性、时效性,本框架内置报警机制,有了这些报警,我们可以实时掌握爬虫状态
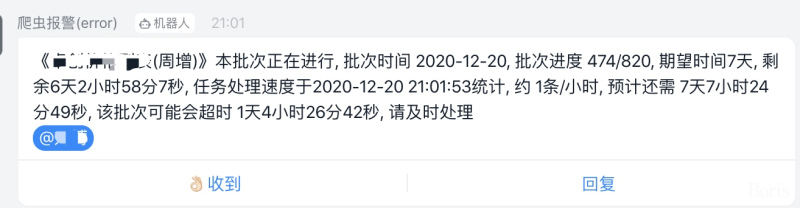
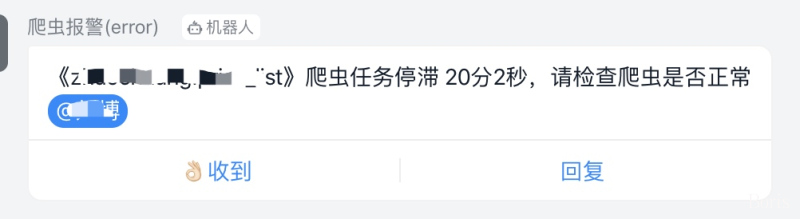
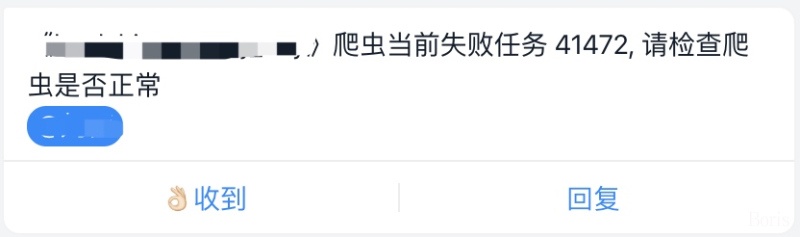
## 框架流程图
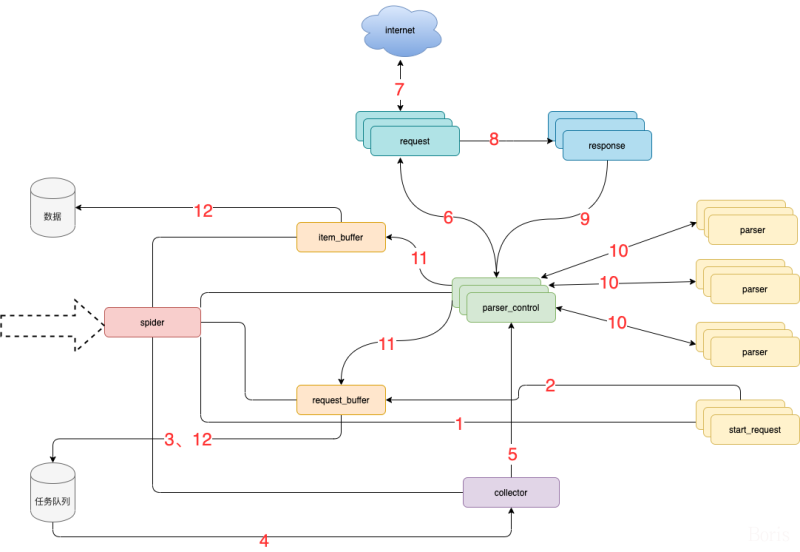
### 模块说明:
* spider **框架调度核心**
* parser_control **模版控制器**,负责调度parser
* collector **任务收集器**,负责从任务队里中批量取任务到内存,以缓冲对任务队列数据库的访问频率及并发量
* parser **数据解析器**
* start_request 初始任务下发函数
* item_buffer **数据缓冲队列**,批量将数据存储到数据库中
* request_buffer **请求任务缓冲队列**,批量将请求任务存储到任务队列中
* request **数据下载器**,封装了requests,用于从互联网上下载数据
* response **数据返回体**,封装了response, 支持xpath、css、re等解析方式。自动处理中文乱码
### 流程说明
1. spider调度**start_request**生产任务
2. **start_request**下发任务到request_buffer中
3. spider调度**request_buffer**批量将任务存储到任务队列数据库中
4. spider调度**collector**从任务队列中批量获取任务到内存队列
5. spider调度**parser_control**从collector的内存队列中获取任务
6. **parser_control**调度**request**请求数据
7. **request**请求与下载数据
8. request将下载后的数据给**response**,进一步封装
9. 将封装好的**response**返回给**parser_control**(图示为多个parser_control,表示多线程)
10. parser_control调度对应的**parser**,解析返回的response(图示多组parser表示不同的网站解析器)
11. parser_control将parser解析到的数据item及新产生的request分发到**item_buffer**与**request_buffer**
12. spider调度**item_buffer**与**request_buffer**将数据批量入库
## 环境要求:
- Python 3.6.0+
- Works on Linux, Windows, macOS
## 安装
From PyPi:
pip3 install boris-spider
From Git:
pip3 install git+https://github.com/Boris-code/boris-spider.git
window下若报bitarray安装错误,可手动安装bitarray,然后再安装此框架。安装步骤:
下载解压:https://github.com/ilanschnell/bitarray/archive/1.5.3.zip
cd bitarray-1.5.3
python setup.py install
## 快速上手
创建爬虫
spider create -p first_spider
创建后的爬虫代码如下:
import spider
class FirstSpider(spider.SingleSpider):
def start_requests(self, *args, **kws):
yield spider.Request("https://www.baidu.com")
def parser(self, request, response):
# print(response.text)
print(response.xpath('//input[@type="submit"]/@value').extract_first())
if __name__ == "__main__":
FirstSpider().start()
直接运行,打印如下:
Thread-2|2020-05-19 18:23:41,128|request.py|get_response|line:283|DEBUG|
-------------- FirstSpider.parser request for ----------------
url = https://www.baidu.com
method = GET
body = {'timeout': 22, 'stream': True, 'verify': False, 'headers': {'User-Agent': 'Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36'}}
百度一下
Thread-2|2020-05-19 18:23:41,727|parser_control.py|run|line:415|INFO| parser 等待任务 ...
FirstSpider|2020-05-19 18:23:44,735|single_spider.py|run|line:83|DEBUG| 无任务,爬虫结束
## 福利
框架内的utils/tools.py模块下积累了作者多年的工具类函数,种类达到100+,且之后还会不定期更新,具有搬砖价值!
## 学习交流
想了解更多框架使用详情,可访问官方文档:https://spider-doc.readthedocs.io
如学习中遇到问题,可加下面的QQ群
群号:750614606

知识星球:

星球会不定时分享爬虫技术干货,涉及的领域包括但不限于js逆向技巧、爬虫框架刨析、爬虫技术分享等
boris-spider是一款使用Python语言编写的爬虫框架.zip

版权申诉
176 浏览量
2024-03-01
12:30:09
上传
评论
收藏 112KB ZIP 举报
 boris-spider是一款使用Python语言编写的爬虫框架,于多年的爬虫业务中不断磨合而诞生,相比于scrapy,该框架更易上手,且又满足复杂的需求,支持分布式及批次采集。.zip (55个子文件)
boris-spider是一款使用Python语言编写的爬虫框架,于多年的爬虫业务中不断磨合而诞生,相比于scrapy,该框架更易上手,且又满足复杂的需求,支持分布式及批次采集。.zip (55个子文件)  SJT-code spider
SJT-code spider  __init__.py 739B dedup __init__.py 6KB bitarray.py 4KB expirefilter.py 2KB bloomfilter.py 12KB README.md 2KB utils __init__.py 129B custom_argparse.py 2KB export_data.py 5KB redis_lock.py 4KB log.py 6KB tools.py 57KB VERSION 6B templates spider main.py 1KB items __init__.py 0B setting.py 2KB parsers __init__.py 0B item_template.tmpl 216B parser_template.tmpl 464B core __init__.py 130B handle_failed_requests.py 2KB parser_control.py 28KB scheduler.py 20KB base_parser.py 6KB spiders __init__.py 347B single_spider.py 3KB spider.py 15KB batch_spider.py 48KB collector.py 5KB setting.py 3KB
__init__.py 739B dedup __init__.py 6KB bitarray.py 4KB expirefilter.py 2KB bloomfilter.py 12KB README.md 2KB utils __init__.py 129B custom_argparse.py 2KB export_data.py 5KB redis_lock.py 4KB log.py 6KB tools.py 57KB VERSION 6B templates spider main.py 1KB items __init__.py 0B setting.py 2KB parsers __init__.py 0B item_template.tmpl 216B parser_template.tmpl 464B core __init__.py 130B handle_failed_requests.py 2KB parser_control.py 28KB scheduler.py 20KB base_parser.py 6KB spiders __init__.py 347B single_spider.py 3KB spider.py 15KB batch_spider.py 48KB collector.py 5KB setting.py 3KB requirements.txt 180B network __init__.py 0B response.py 11KB proxy_pool.py 23KB request.py 14KB user_agent.py 6KB selector.py 6KB item.py 4KB commands __init__.py 0B create_builder.py 17KB shell.py 2KB cmdline.py 1KB db __init__.py 130B memory_db.py 769B redisdb.py 26KB mysqldb.py 9KB buffer __init__.py 130B request_buffer.py 5KB item_buffer.py 11KB setup.py 2KB LICENSE 1KB tests first_demo.py 410B MANIFEST.in 192B .gitignore 134B README.md 6KB
requirements.txt 180B network __init__.py 0B response.py 11KB proxy_pool.py 23KB request.py 14KB user_agent.py 6KB selector.py 6KB item.py 4KB commands __init__.py 0B create_builder.py 17KB shell.py 2KB cmdline.py 1KB db __init__.py 130B memory_db.py 769B redisdb.py 26KB mysqldb.py 9KB buffer __init__.py 130B request_buffer.py 5KB item_buffer.py 11KB setup.py 2KB LICENSE 1KB tests first_demo.py 410B MANIFEST.in 192B .gitignore 134B README.md 6KB资源评论


JJJ69
- 粉丝: 6167
- 资源: 5789

下载权益

C知道特权

VIP文章

课程特权
开通VIP











