

简介
DataStage 使用了 Client-Server 架构,服务器端存储所有的项目和元数据,
客户端 DataStage Designer 为整个 ETL 过程提供了一个图形化的开发环境,
用所见即所得的方式设计数据的抽取清洗转换整合和加载的过程。Datastage
的可运行单元是 Datastage Job ,用户在 Designer 中对 Datastage Job 的
进行设计和开发。Datastage 中的 Job 分为 Server Job, Parallel Job 和
Mainframe Job ,其中 Mainframe Job 专供大型机上用,常用到的 Job 为
Server Job 和 Parallel Job 。本文将介绍如何使用 Server Job 和 Parallel
Job 进行 ETL 开发。
Server Job
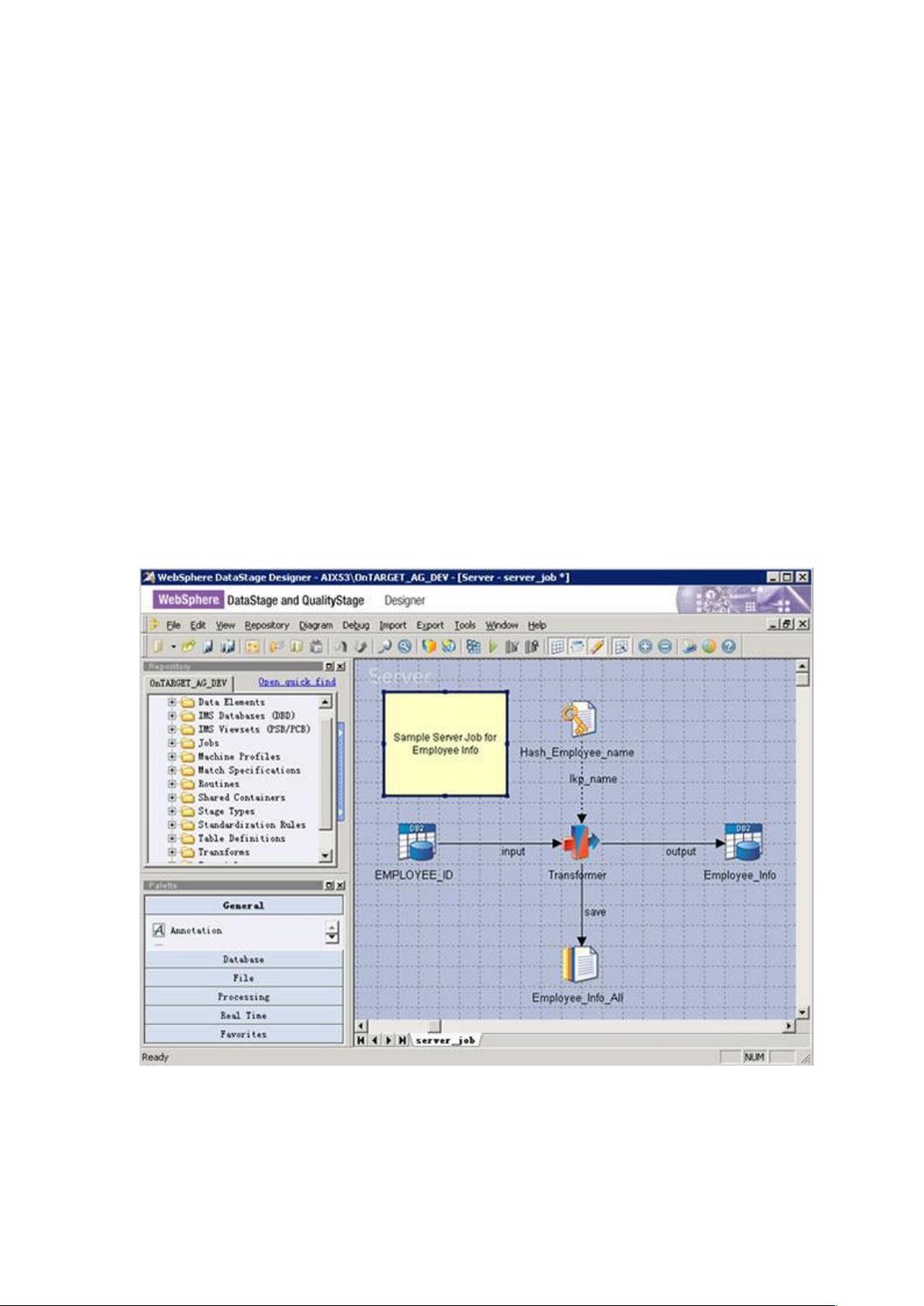
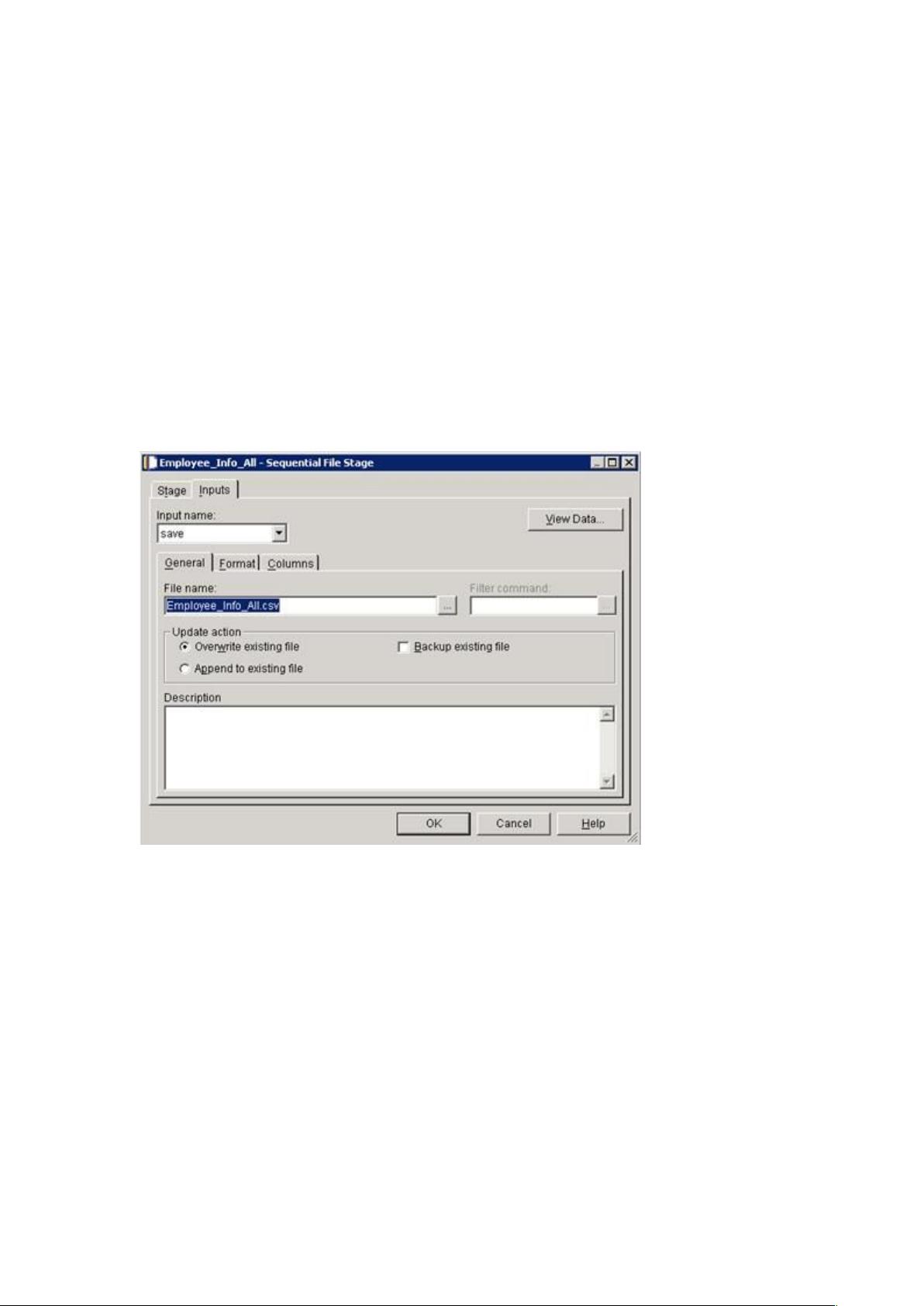
一个 Job 就是一个 Datastage 的可运行单元。Server Job 是最简单常用的
Job 类型,它使用拖拽的方式将基本的设计单元 -Stage 拖拽到工作区中,并
通过连线的方式代表数据的流向。通过 Server Job,可以实现以下功能。
1. 定义数据如何抽取
2. 定义数据流程
3. 定义数据的集合
4. 定义数据的转换
5. 定义数据的约束条件
6. 定义数据的聚载
7. 定义数据的写入

剩余23页未读,继续阅读
资源评论













