kafka基础理论与一些问题的回答
需积分: 0 79 浏览量
2024-03-20
18:18:31
上传
评论
收藏 1.44MB DOCX 举报

Flink 的必备基础:
Flink 相比传统的 SparkStreaming 区别?
这个问题是一个非常宏观的问题,因为两个框架的不同点非常之多。但是在面试时有非常重要的一点一定
要回
答出来:Flink 是标准的实时处理引擎,基于事件驱动。而 SparkStreaming 是微批(Micro-Batch)的
模型。
下面我们就分几个方面介绍两个框架的主要区别:
1.架构模型 SparkStreaming 在运行时的主要角色包括:Master、Worker、Driver、Executor,Flink 在
运行
时主要包含:Jobmanager、Taskmanager 和 Slot。2.任务调度 SparkStreaming 连续不断的生成微小的
数据批次,构建有向无环图 DAG,SparkStreaming 会
依次创建 DStreamGraph、JobGenerator、JobScheduler。Flink 根据用户提交的代码生成
StreamGraph,经过优
化生成 JobGraph,然后提交给 JobManager 进行处理,JobManager 会根据 JobGraph 生成
ExecutionGraph,
ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
3. 时间机制 SparkStreaming 支持的时间机制有限,只支持处理时间。Flink 支持了流处理程序在时间上
的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。4.容错机制
对于 SparkStreaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次
checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰好一次处理语义。
Flink 则使用两阶段提交协议来解决这个问题。
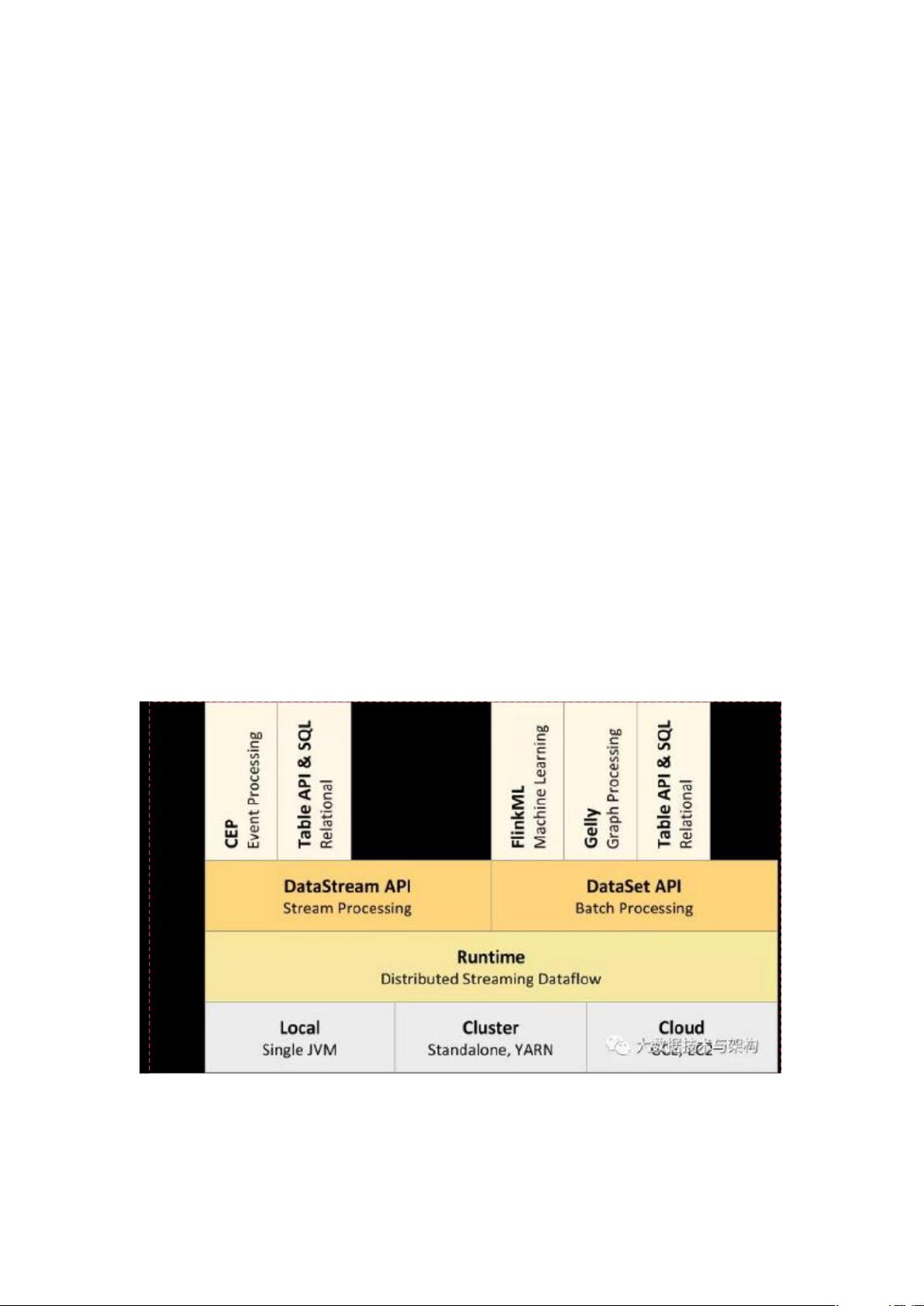
Flink 的组件栈有哪些
根据 Flink 官网描述,Flink 是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务
于上层组件。
自下而上,每一层分别代表:Deploy 层:该层主要涉及了 Flink 的部署模式,在上图中我们可以看出,Flink
支
持包括 local、Standalone、Cluster、Cloud 等多种部署模式。Runtime 层:Runtime 层提供了支持 Flink
计算的核
资源评论













