由于训练的公开视频数据集(源视频域)和真实视频(目标视频域)之间的域差异,训
练的基于现有数据集的视频模型在直接部署到真实世界的应用程序时,会有显著的性能下
降。此外,由于视频注释的成本较高,使用无标记的视频进行训练更加实用。为了统一解
决视频高标注成本以及性能下降的问题,引入了视频无监督域自适应(VUDA),通过减
轻视频域偏移,提高视频模型的通用性和可移植性,从标记源域适应到无标记目标域。
虽然具有深度学习的UDA通过处理领域转移大大提高了模型的通用性和可移植性,但之
前对视觉应用的研究通常集中在图像数据上。同时,通过传统的视频特征提取器获得的视
频表示主要来自于空间特征。然而,视频不仅包含空间特征,而且还包含时间特征以及其
他模式的特征,如光流和音频特征,所有这些特性都会发生域偏移。
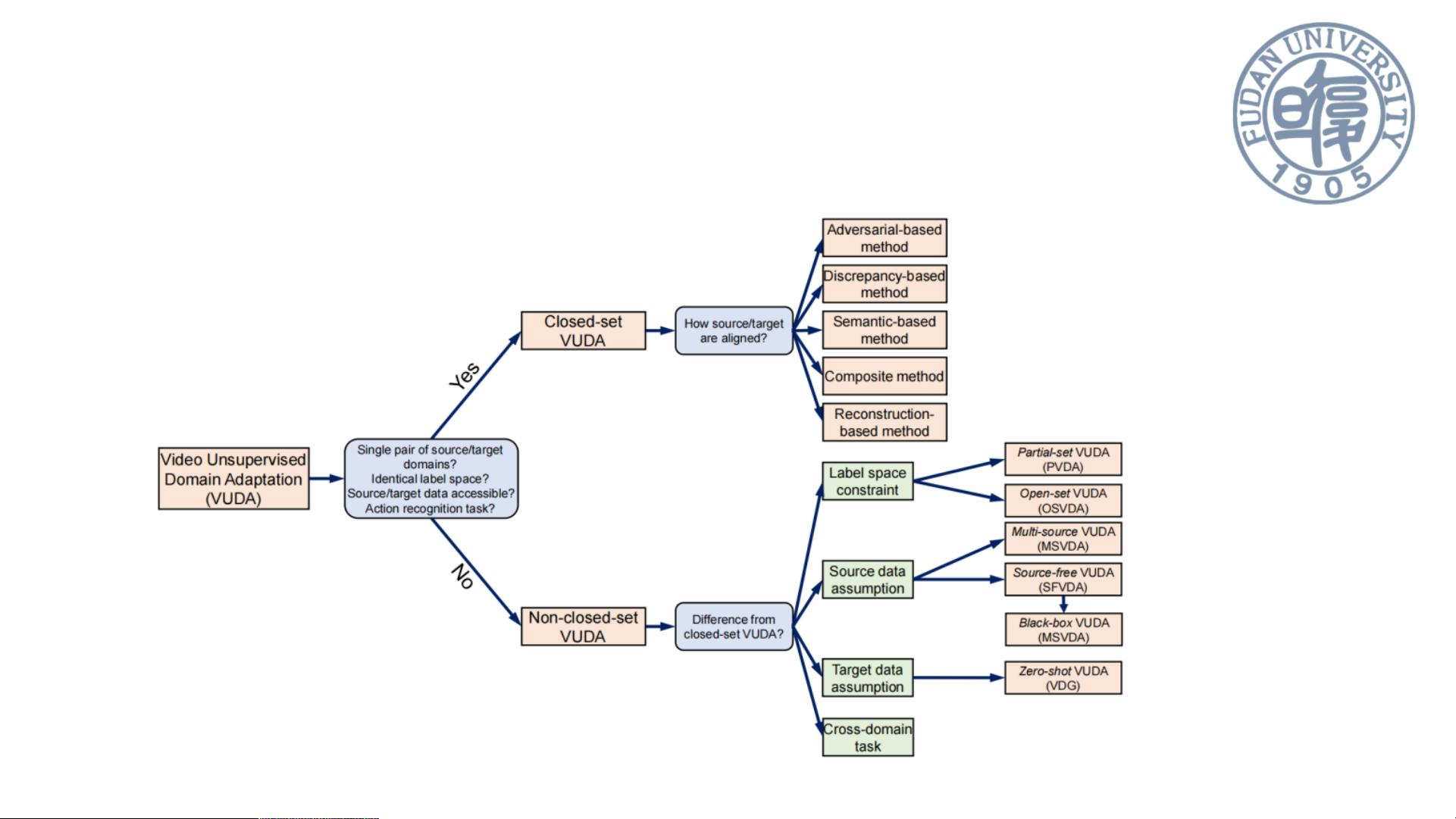
VUDA提出背景