

一、实验题目
大数据技术实践——Spark 词频统计
二、引言
本次作业要完成在 Hadoop 平台搭建完成的基础上,利用 Spark 组件完成文
本词频统计的任务,目标是学习 Scala 语言,理解 Spark 编程思想,基于 Spark
思想,使用 IDEA 编写 SparkWordCount 程序,并能够在 spark-shell 中执行代码
和分析执行过程。
三、技术/算法介绍
1. 基本介绍:
Spark 是一种由 Scala 语言开发的基于内存的快速、通用、可扩展的大数据
分析引擎。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。
与 Hadoop 不同,Spark 和 Scala能够紧密集成,其中的 Scala 可以像操作本地
集合对象一样轻松地操作分布式数据集。
Spark,拥有 Hadoop MapReduce 所具有的优点;但不同于 MapReduce 的是
——Job 中间输出结果可以保存在内存中,从而不再需要读写 HDFS,因此
Spark 能更好地适用于数据挖掘与机器学习等需要迭代的 MapReduce 的算法。
另外,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可
以优化迭代工作负载。
2. 基本原理:
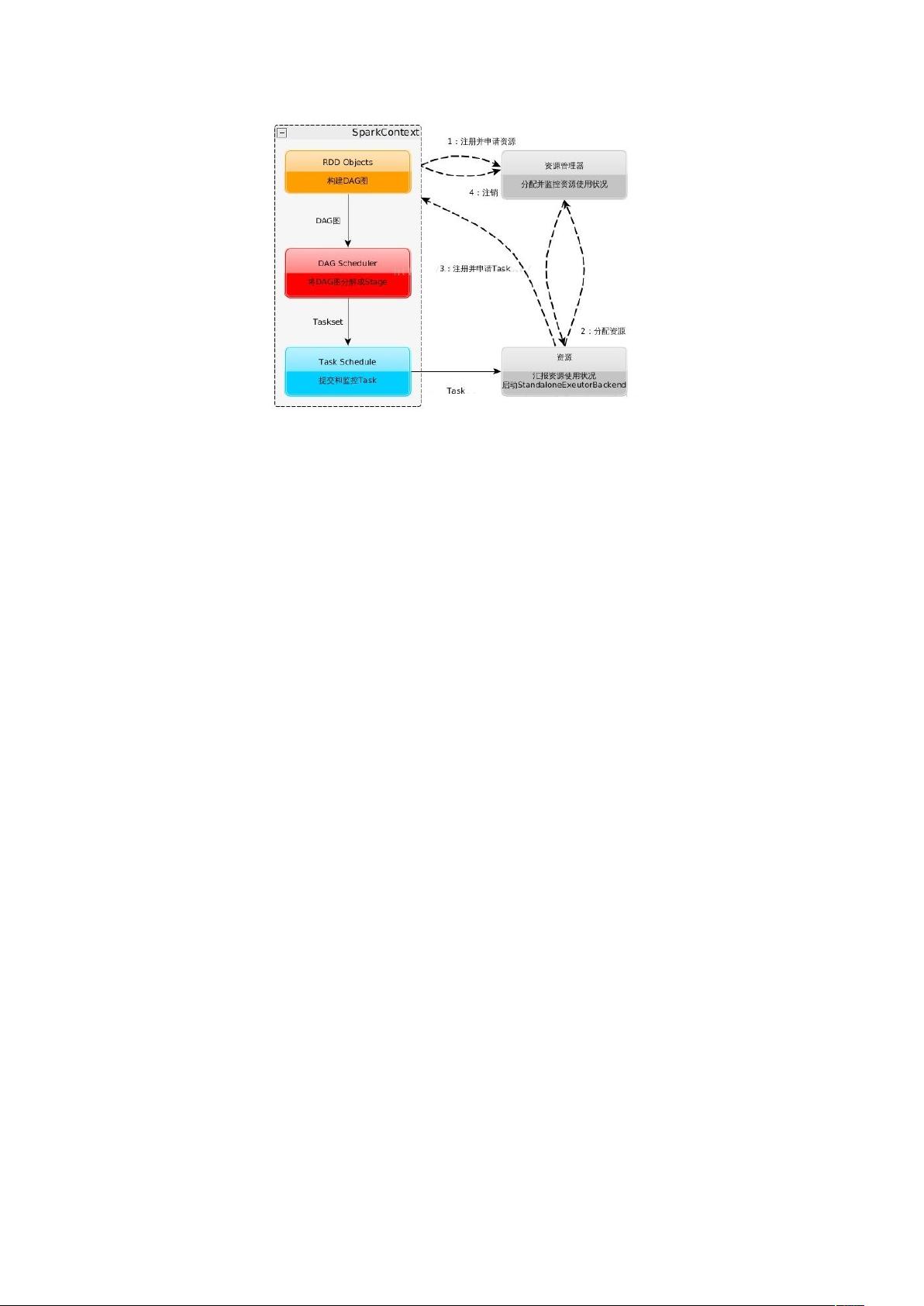

剩余13页未读,继续阅读
资源评论

 行走的瓶子Yolo2023-07-25这篇文章对Spark词频统计进行了详实的描述,并提供了一些实战案例,非常值得一读。
行走的瓶子Yolo2023-07-25这篇文章对Spark词频统计进行了详实的描述,并提供了一些实战案例,非常值得一读。 会飞的黄油2023-07-25作者深入浅出地阐述了Spark词频统计的原理和应用场景,对于新手来说也很友好。
会飞的黄油2023-07-25作者深入浅出地阐述了Spark词频统计的原理和应用场景,对于新手来说也很友好。 黄涵奕2023-07-25该文件的解释清晰,图文并茂,让人容易理解和跟随操作步骤。
黄涵奕2023-07-25该文件的解释清晰,图文并茂,让人容易理解和跟随操作步骤。 十二.122023-07-25文章的观点中肯,结合实际情况讲解了大数据技术中Spark词频统计的重要性。
十二.122023-07-25文章的观点中肯,结合实际情况讲解了大数据技术中Spark词频统计的重要性。 罗小熙2023-07-25这篇文件对Spark词频统计进行了实践,内容丰富,给予了很多有用的示例。
罗小熙2023-07-25这篇文件对Spark词频统计进行了实践,内容丰富,给予了很多有用的示例。

小鱼uua
- 粉丝: 5
- 资源: 1









最新资源
- 基于二阶自抗扰ADRC的轨迹跟踪控制,对车辆的不确定性和外界干扰具有一定抗干扰性,基于carsim和simulink仿真 跟踪轨迹为双移线,效果良好,有对应复现资料,是学习自抗扰技术快速入门很好的资料
- 基于python的网页自动化工具项目全套技术资料100%好用.zip
- MATLAB【逆变器二次调频模型】 微电网分布式电源逆变器DROOP控制二次调频模型,加入二次控制实现二次调频控制,及二次调压控制,程序可实现上图功能,工况有所改变 需要matlab2021A版
- 抢购软件:快速复制信息
- 单机无穷大系统发生各类(三相短路,单相接地,两相接地,两相相间短路)等短路故障,各类(单相断线,两相断线,三相断线)等断线故障,暂态稳定仿真分析
- 微信文章爬虫项目全套技术资料100%好用.zip
- 基于动态窗口算法的AGV仿真避障 可设置起点目标点,设置地图,设置移动障碍物起始点目标点,未知静态障碍物 动态窗口方法(DynamicWindowApproach) 是一种可以实现实时避障的局部规划算
- Power Quality Disturbance:基于MATLAB Simulink的各种电能质量扰动仿真模型,包括配电线路故障、感应电机启动、变压器励磁、单相 三相非线性负载等模型,可用于模拟各种
- 数据爬虫项目全套技术资料100%好用.zip
- 聊天系统项目全套技术资料100%好用.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


