大数据编程期末大作业-Hadoop
105 浏览量
2024-03-11
15:00:14
上传
评论
收藏 1.23MB DOCX 举报


大数据编程期末大作业
文章目录
大数据编程期末大作业
一、Hadoop 基础操作
二、RDD 编程
三、SparkSQL 编程
四、SparkStreaming 编程
一、Hadoop 基础操作
在 HDFS 中创建目录 /user/root/你的名字 例如李四同学 /user/root/lisi
首先我们需要启动 hdfs,我们直接在终端输入如下命令:
1 start-dfs.sh
我们在终端输入如下命令创建目录:
1 hadoop fs -mkdir /user
2 hadoop fs -mkdir /user/root
3 hadoop fs -mkdir /user/root/***(这里是你自己的名字)
上面是逐个创建文件夹,我们还可以使用参数-p 一次性创建多级目录:
1 hadoop fs -mkdir -p /user/root/***
创建本地文件 a.txt,文件内容:You love Hadoop ,并将改文件上传到 HDFS 中第 1 题所创建
的目录中
我们直接在终端的 root 目录下面创建我们的本地文件并输入题目要求的内容:
1 vim a.txt
然后我们再在终端输入上传命令:
1 hadoop fs -put a.txt /user/root/***
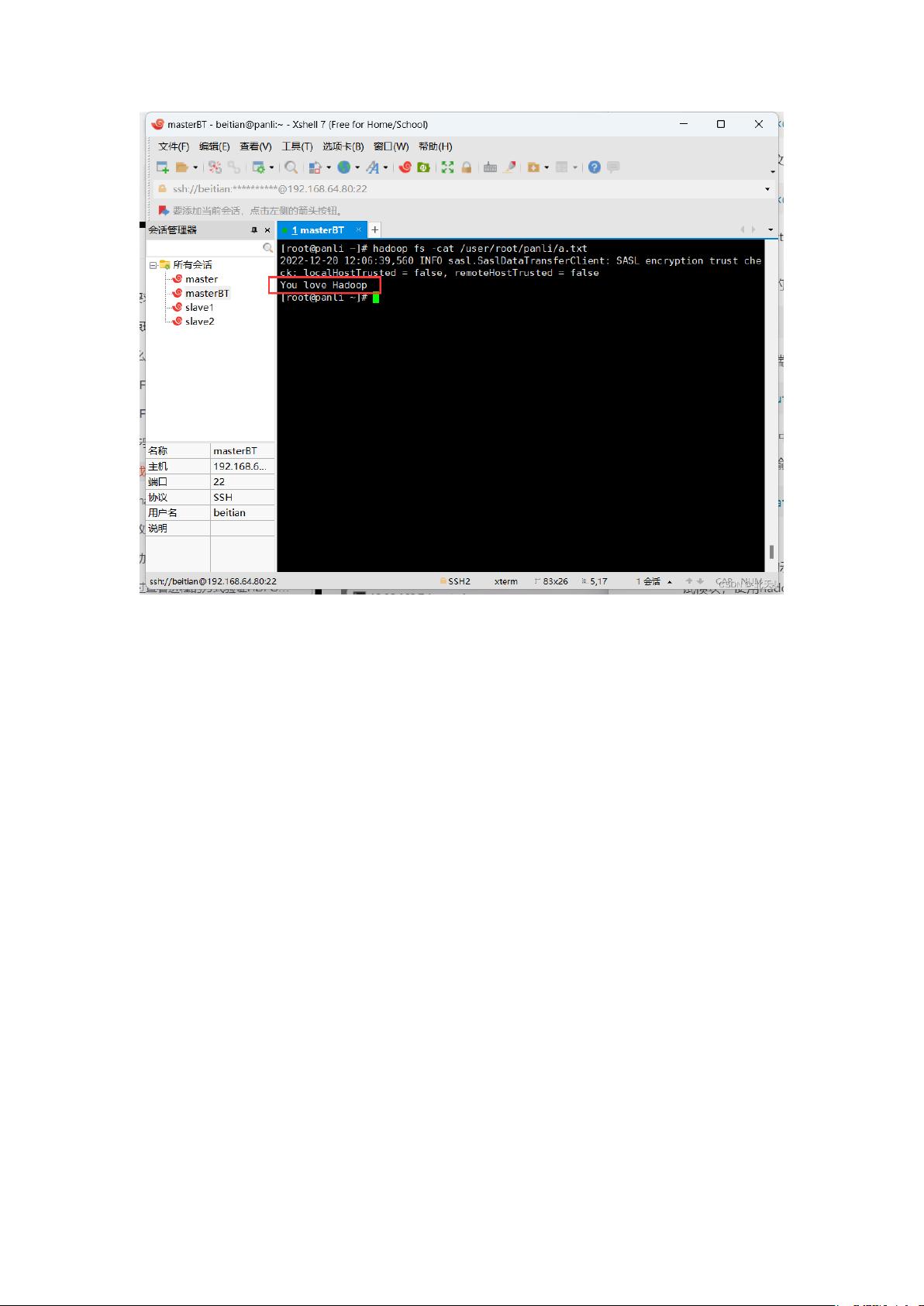
查看上传到 HDFS 中的 a.txt 文件的内容
我们直接在终端输入查看命令:
1 hadoop fs -cat /user/root/***/a.txt
剩余10页未读,继续阅读
资源评论













