DeepRIoT: Continuous Integration and Deployment Of
Robotic-IoT Applications
Meixun Qu
∗,†
, Jie He
∗,†
, Zlatan Tucaković
†
, Ezio Bartocci
†
, Dejan Ničković
‡
, Haris Isaković
†
, Radu Grosu
†
Technische Universität Wien
†
, AIT Austrian Institute of Technology
‡
ABSTRACT
We present DeepRIoT, a continuous integration and continuous de-
ployment (CI/CD) based architecture that accelerates the learning
and deployment of a Robotic-IoT system trained from deep rein-
forcement learning (RL). We adopted a multi-stage approach that
agilely trains a multi-objective RL controller in the simulator. We
then collected traces from the real robot to optimize its plant model,
and used transfer learning to adapt the controller to the updated
model. We automated our framework through CI/CD pipelines, and
nally, with low cost, succeeded in deploying our controller in a
real F1tenth car that is able to reach the goal and avoid collision
from a virtual car through mixed reality.
KEYWORDS
Deep Reinforcement Learning, Sim2Real, DevOps, CI/CD
1 INTRODUCTION
Deep Reinforcement Learning [
1
] (RL) has been gaining momen-
tum in the control tasks of Robotic-IoT systems [
2
–
4
]. Although RL
has achieved state-of-the-art in some simulation benchmarks, there
are still many factors that hinder its application in real Robotic-IoT
systems, for example, the sample ineciency problem of RL algo-
rithms, the generalization problem of deep neural networks, the
unavoidable noise in the sensors, and the deviation of the simulation
from the real system (Sim2Real problem [5]).
Unfortunately, there is no systematic approach that takes the
aforementioned problems into consideration, to guide the training
and deployment of RL in real Robotic-IoT systems. In this paper,
we ll in this blank by proposing DeepRIoT, a practical framework
that aims at accelerating the learning and deployment for RL algo-
rithms. To achieve this goal, we leverage the DevOps [
6
] practices
that integrate the process of software development (Dev) with the
monitoring of the real system during its operation (Ops). In our con-
text, the collection of the execution traces of the real Robotic-IoT
running the RL policy is used to improve the models and thus the
RL policy in the simulation environment. Using DevOps machinery
we can fully automate the integration of model changes w.r.t. the
real system execution, RL policy retraining in the simulation en-
vironment and its continuous deployment in the real Robotic-IoT.
These processes are referred as Continuous Integration [
7
] (CI) and
∗
Both authors contribute equally to this paper.
Permission to make digital or hard copies of part or all of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full citation
on the rst page. Copyrights for third-party components of this work must be honored.
For all other uses, contact the owner/author(s).
DAC ’24, June 23–27, 2024, San Francisco, CA, USA
© 2024 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-0601-1/24/06.
https://doi.org/10.1145/3649329.3658250
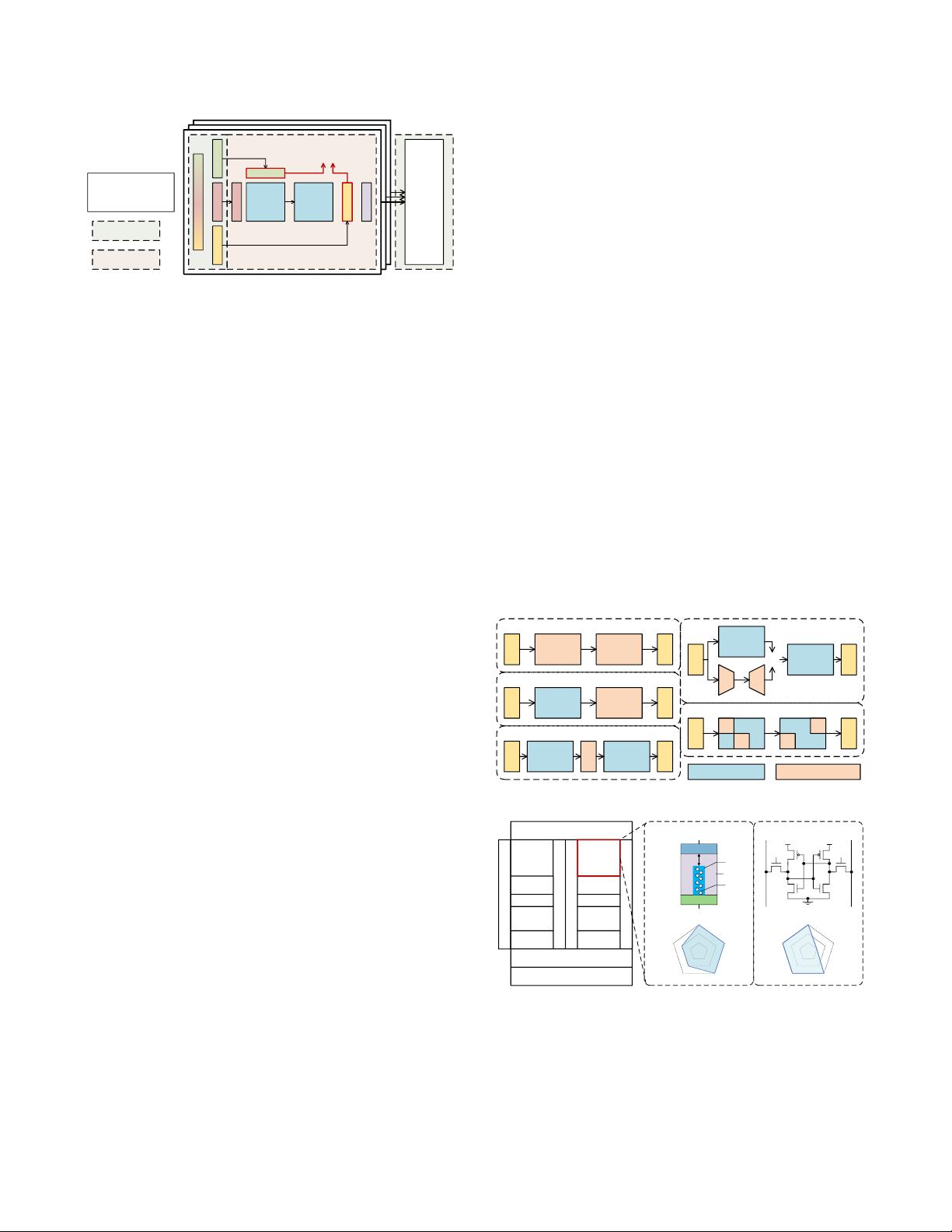
Figure 1: De epRIoT architecture and workow
Continuous Deployment [
8
] (CD). To accelerate RL in the simulation
environment, we further enhance this process by using models of
the real Robotic-IoT of dierent complexity.
We select a classic use case in motion planning to demonstrate
our approach. We perform our experiments using F1tenth [
9
], an
open-source autonomous vehicle platform. Our task is to teach an
F1tenth car to reach the goal position from a starting point while
avoiding collisions with static obstacles and other vehicles.
DeepRIoT Architecture. We sketch the architecture of DeepRIoT,
depicted in Fig. 1. The architecture consists of Pipelines (A-E).
Pipeline A. Here we specify requirements
Φ
for the given robotic
tasks. These requirements are given in the form of formal speci-
cations using Signal Temporal Logic (STL) [
10
]. There are two
major advantages of using formalized requirements. First, one can
use runtime monitors to measure the degree to which the observed
robotic behaviors satisfy or violate the specications (see Pipelines
C-E). Second, these same specications are used to engineer the
reward function during the agent training process [
11
] (Pipeline C).
After selecting a suitable simulator for training the robotic tasks,
we begin to construct the training environment in the context of
RL, e.g., dening states, actions, and reward functions.
Pipeline B. This further constructs observers and lters for the
states according to pre-dened feature rules. For example, we add
Gaussian noises to the LiDAR model to make it more realistic. When
we teach the car to avoid collision to obstacles, we only consider
laser scans whose lengths are within a specied range.
Pipeline C. This is responsible for training the RL policy. It takes
the inputs processed by the previous two pipelines, and starts from
picking a simple kinematics model (KiModel) to simulate the dy-
namics of the car. Every step of training yields a four-tuple called
experience that includes current state, current action, next state and