
别让数据坑了你!⽤置信学习找出错误标注(附开源实现)
JayLou娄杰
昨天⼣⼩瑶的卖萌屋
星标/置顶⼩屋,带你解锁
最萌最前沿的NLP、搜索与推荐技术
⽂ | JayLou娄杰(NLP算法⼯程师,信息抽取⽅向)
编 | 北⼤⼩才⼥⼩轶
美 | Sonata
1 前⾔
在实际⼯作中,你是否遇到过这样⼀个问题或痛点:⽆论是通过哪种⽅式获取的标注数据,数据标注质量可能不过关,存在⼀些
错误?亦或者是数据标注的标准不统⼀、存在⼀些歧义?特别是badcase反馈回来,发现训练集标注的居然和badcase⼀样?如
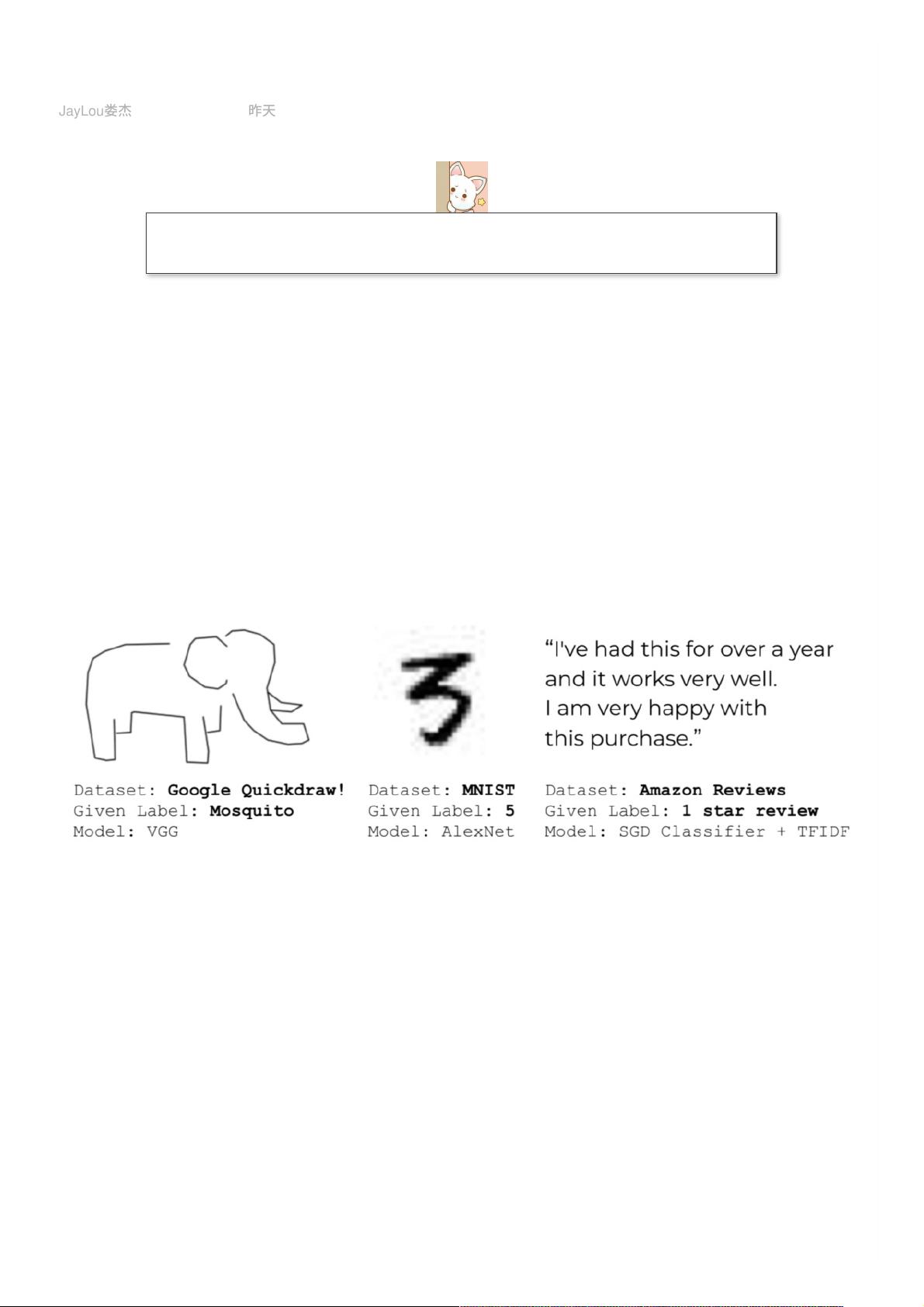
下图所⽰,QuickDraw、MNIST和Amazon Reviews数据集中就存在错误标注。
为了快速迭代,⼤家是不是常常直接⼈⼯去清洗这些“脏数据”?(笔者也经常这么⼲〜)。但数据规模上来了咋整?有没有⼀种
⽅法能够⾃动找出哪些错误标注的样本呢?基于此,本⽂尝试提供⼀种可能的解决⽅案——置信学习。
本⽂的组织架构是:

剩余11页未读,继续阅读
资源评论


普通网友
- 粉丝: 1277
- 资源: 5623









最新资源
- 神经系统化药行业分析:预计到2030年全球神经系统化药年复合增长率(CAGR)为5.0%
- Java源码springboot+vue二次元商品购物商城-毕业设计论文-大作业.zip
- 电力电子三相无源逆变器的控制simulink仿真 电压外环电流内环双闭环 dq解耦控制 PWM调制 LC滤波器 离散仿真
- 可发送邮件的域名出售页源码
- 免税商品优选购物商城 JAVA毕业设计 源码+数据库+论文 Vue.js+SpringBoot+MySQL.zip
- Android天气预报APP
- RedBlackTree&BTree-RB-Tree.c
- java的通讯录管理系统
- 西门子四轴机械手搬运仿真博图V15(含程序和仿真源文件,参数可调整) 动作流程:机械臂下降-物料抓取-旋转-下降-物料放下
- STM32F407最小核心板HAL例程
- JAVA+SQL电子通讯录带系统托盘(LW+源代码).rar
- Prime_Series_Level-1.z01
- Prime_Series_Level-1.z02
- Prime_Series_Level-1.z03
- 基于Keil+51单片机的自行车测速(源码+仿真)
- 私有化部署的IBM Watsonx 介绍及对比
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


