

2023/6/28 22:31
2202年了,继续大比拼ViT、MLP、CNN结构有意义吗??
https://mp.weixin.qq.com/s/zW0B8T9NO3T1adzuiz6V6g
1/10
2202年了,继续大比拼ViT、MLP、CNN结构有意义吗??
收录于合集
#卖萌屋@计算机视觉
15个
文 | 卖 萌 菌
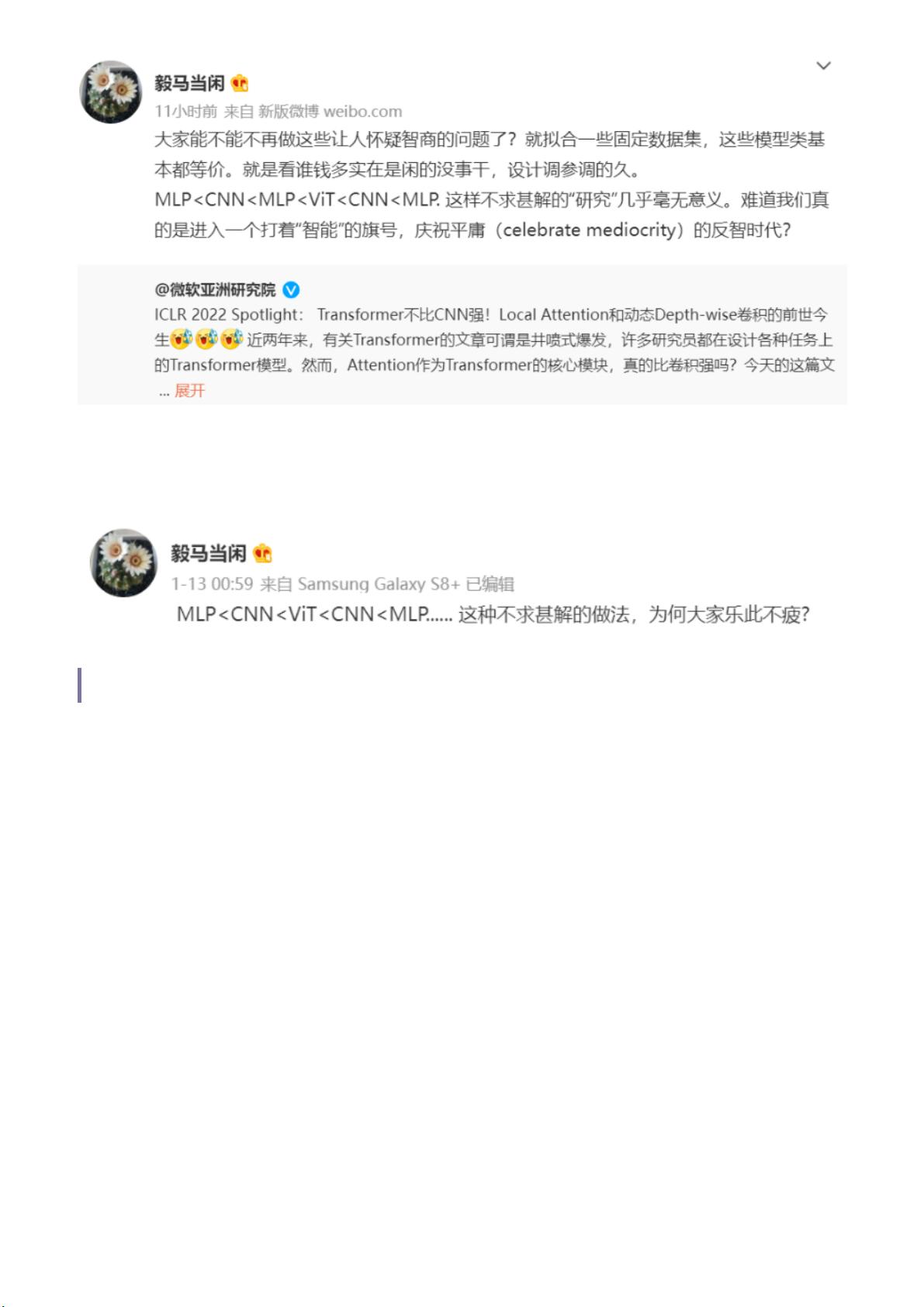
近 日 , MSRA 发 布 了 一 篇 题 为 《 Transformer 不 比 CNN 强 Local Att entio n 和 动 态 Depth-
wise卷 积 前 世 今 生 》的博文,再次谈论了这个老生常谈的话题。文中提到,Depth-wise CNN
和 attention 存在高度相似的结构,调参优化之后,从结果上来看,指标上也没相差多少。如
果从输入到输出的传播路径上来看,CNN 和 self-attention ,从视角上看,其最终汇总到的特
征,的确都是类似的,例如,self-attention 一层可以看作是全连接的一跳,经 N 层之后,形
成了 N 跳可达。CNN 则也类似,二者都是在整个输入空间下,各单元之间的关联强度。只是
实现路径不同。
博文发出之后,加州大学伯克利分校,统计学大佬,马毅教授转发并评论:
卖萌菌 2022-05-11 12:05 发表于四川
原创
夕小瑶科技说
剩余9页未读,继续阅读
资源评论


普通网友
- 粉丝: 1263
- 资源: 5619









最新资源
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


