






逐字精读 Vision in Transformer
2022年04⽉10⽇15:53:19
基本信息介绍
题⽬:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE
RECOGNITION AT SCALE
期刊:Published as a conference paper at ICLR 2021
博客推荐:ViT 快速理解 Vision Transformer
原⽂链接
代码实现
过程理解
Self-Attention⾃注意⼒机制
作者团队
ABSTRACT
当Transformer成为NLP任务中的标准结构时,但它在机器视觉的应⽤中任然存在很多限制。
在视觉任务中,注意⼒机制已经与卷积神经⽹络结合使⽤,或者被⽤作替换卷积中的某些组件
来保持其结构完整性。卷积神经⽹络不是必要的,我们能够将原始的transformer直接应⽤在
图像序列块上,且能够在图像分类任务中很好的work。当在⼤型数据集上进⾏预训练时,然

后迁移到中⼩型数据集上进⾏识别(如,ImageNet、CIFAR-100、VTAB等),ViT能够⽐最
sota的卷积神经⽹络模型还要达到更好的结果,相⽐⽽⾔还能够⽤更少的资源去训练。
1 INTRODUCTION
基于⾃注意⼒的结构,尤其是Transformers,逐渐成为了NLP所选择的模型。主要⽅法是基于
⼤型⽂本资料库进⾏预训练,然后在更⼩的特定数据集上进⾏微调。感谢Transformer计算的
有效性及可扩展性,它让训练前所未有规模的模型成为可能,模型超过100B的参数。随着模
型和数据的不断增⻓和更新,性能还没有呈现出任何饱和状况。
机器视觉中,尽管卷积的结构保持着主要地位。受到NLP巨⼤成功的启发,很多⼯作都在努⼒
尝试结合卷积和⾃注意⼒,⼀些⼯作完全去掉了卷积层。对于后⾯这种模型,它理论上是有效
的;由于使⽤了特殊的注意⼒模式,它未能在现代硬件加速器上进⾏有效的扩展。因此,在⼤
规模的图像分类中,基于ResNet的⻣架⽹络任然能够取得sota。
受到Transformer在NLP领域⼤规模成功的启发,我们实验时直接将⼀个标准的Transformer应
⽤到图像上,并伴随着尽可能少的改动。我们把图像划分成patch块并让它们经过序列映射
linear embeddings,作为像Transformer⼀样的输⼊。图像块patch的处理⽅式与NLP中的
token词向量是相同的。我们在图像分类中⽤有监督的⽅式训练模型。
当在中等规模的数据集如ImageNet上训练没有很好的regularization,这些模型的结果⽐同等
规模的ResNet准确率要低⼏个百分点。这令⼈沮丧的结果似乎是可以预期的:Tranformers与
CNN相⽐缺乏固定的inductive biases感应偏差,就像平移不变性、尺度不变性等(translation
equivariance and locality),因此在数据量不⾜的训练集上训练没有产⽣⼀个很好的预期。
如果在⾜够的数据集上进⾏训练(14M-300M images),那么情况就会发⽣改变。我们发现
在⼤规模数据集进⾏训练能够⽐卷积的归纳偏置更好。我们的ViT在⾜够规模数据进⾏预训练
后再迁移到更⼩规模的任务中能够达到更好的结果。当在共有数据集ImageNet-21K或者JFT-
300M上进⾏预训练后,ViT能够打败其它基于各种的识别⻣⼲⽹络。特别的,在ImageNet上
达到88.66%准确率、在ImageNet-ReaL上为90.72%、CIFAR-100为94.55%,在VTAB的19种
任务中达到77.63%。
(Fine-tuning code and pre-trained models are available at https://github.com/google-resea
rch/vision_transformer)

2 RELATED WORK
Transformers由Vaswani等⼈在机器翻译中提出,在许多NLP任务中都达到了sota。⼤型基于
Transformer的模型,通常都是基于⼤型语义库预训练,然后微调去处理⼿头的⼯作:BERT
(2019)使⽤去噪的⾃监督预训练任务,同时GPT⼯作线将语⾔建模作为其训练前的任务。
单纯的应⽤⾃注意⼒到图像需要每⼀个像素点都关注其它像素点。由于像素平⽅级的计算开
销,⽆法扩展到实际的图像输⼊。因此,为应⽤Transformer到图像处理中,过去类似的⼯作
在被展开。Parmar等⼈应⽤⾃注意⼒时仅仅是基于局部像素⽽不是全局。这样的局部多头⾃
注意⼒块,能够完全取代卷积(2019-2020)。在不同的⼯作,Sparse Transformer近似可伸
缩的全局注意⼒为了应⽤到图像中。⼀种可替代的⽅式是应⽤缩放的注意⼒针对其不同⼤⼩的
块,在极端案例下仅沿单个维度进⾏操作。许多不同的特定注意⼒结构都很好的证明了
Transformer在机器视觉任务中是很有前景,但是需要复杂的⼯程量以及⾼效的可加速计算的
硬件。
与我们的模型最接近的是Cordonnier的⼯作(2020),从图像输⼊中提取2×2⼤⼩的patch并
在顶部完全应⽤⾃注意⼒。这个模型和ViT⾮常相似,但我们的⼯作从更加⻓远的⻆度证明了
在⼤规模预训练后Transformer能够取得甚⾄⽐sota-CNN模型更好的结果。此外,Cordonnier
等⼈,使⽤⼀个2×2像素的⼩patch仅仅把模型应⽤在⼩分辨率的图像上,同时,我们处理了
中等分辨率的图像。
也有很多⼈对结合CNN的⾃注意⼒⽹络感兴趣,如,增强特征映射图⽤于图像分类,或者利
⽤⾃注意⼒处理CNN的输出,如⽬标检测,视频处理,图像分类,⽆监督的对象发现,或者
统⼀的⽂本视觉任务。
另⼀个最近相关的模型是图像GPT(2020a),应⽤Transformer到减⼩分辨率之后的图像及颜
⾊空间。这个模型是⼀种⽆监督的⽣成模型,结果表明模型能够被预训练微调或线性探测⽤于
提⾼分类性能。在ImageNet实现了72%的准确率。
我们的⼯作增加了⽐标准ImageNet数据集更⼤范围内探索图像识别论⽂的数量。Mahajan等
⼈使⽤额外的数据实现了sota的结果基于标准基准。此外,Sun等⼈研究了CNN的性能与数据
⼤⼩的关系,Djolonga等⼈从⼤规模数据集ImageNet-21K和JFT-300M对CNN迁移学习进⾏实
证探索。我们更加倾向这两个数据集,训练Transformer替代以前基于ResNet的模型。
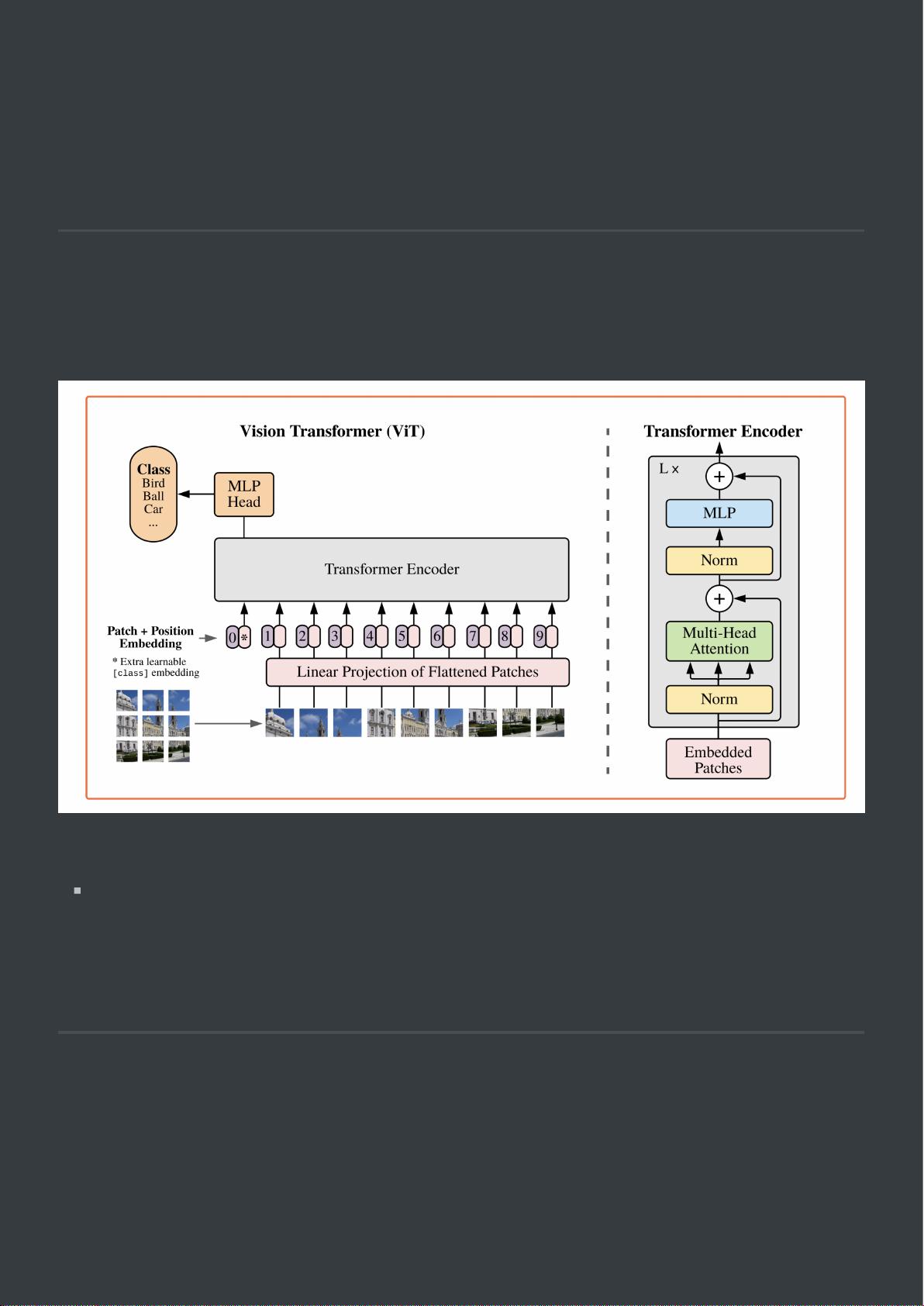
图1 模型概述
3 METHOD
模型的设计我们尽可能遵循原始的Transformer(Vaswani 2017)。这种有意简化设计的⼀个
优点就是,可扩展的NLP Transformer架构及能够及拿及⽤的⾼效的实现。
3.1 VISION TRANSFORMER (ViT)
模型的简要概述如图1:
我们把图像划分成固定⼤⼩的图像块,对全部进⾏线性映射,增加位置信息编码,然后把
序列的结果向量传⼊标准的Transformer Encoder。为了分类,我们使⽤标准的⽅法往序
列中添加⼀个额外的可学习参数“classification token”。上图右边的Transformer Encoder
插图灵感来源于Vaswani(2017)。
(回到原⽂)标准的Transformer接收的是1-维的token embedding序列。为了处理2-维的图
像,我们reshape图像[x ∈ R(H×W×C)]成2-维的patch块[x_p∈ R(N×(P^2×C))],H和W原始图像
的分辨率,C是通道数,(P,P)是每个图像块的分辨率, N=HW/P^2是patch块的数量,这
也是作为Transformer有效输⼊的序列⻓度。Transformer所有层使⽤的都是固定的向量,⼤⼩
为D;所以我们将patch块flatten拉平成⼀维序列然后通过线性映射到D维(如图1)。我们称

线性映射层this projection的输出为patch embedding。
与BERT的[class] token相似,我们给序列映射后的编码准备了⼀个可学习的映射x_class,
Transformer encoder的输出⽤序列的(z^0)图像表示y(Eq.4)。基于预训练和微调,z^0⽤
于分类头。分类头在预训练时,由⼀个隐含层的MLP实现,在微调时由简单的线性层来实现。
位置编码被⽤于增加patch embedding的原始位置信息。我们使⽤1维的位置信息编码,因为
⼆维的位置信息编码并没有发现有更好的性能(D.4)。⽣成的序列向量被⽤于encoder的输⼊。
Transformer encoder包含交替的多头注意⼒机制及MLP块(Eq. 2,3)。LN层被⽤在每个MLP
块前⾯,在每个块之后进⾏残差连接。
MLP多层感知机包含两层以及GELU⾮线性激活函数。
Inductive bias.
归纳偏置,我们注意到Vision Transformer⽐起CNN针对图像⽽⾔有更少的归纳偏置。CNN
中,每⼀层卷积核的局部性、⼆维领域结构、平移不变性等始终贯穿整个模型。在ViT中,只
有MLP层有这些特性,⾃注意⼒层都是全局信息。⼆维的结构很少被⽤在ViT中:模型最初,
把图像剪切成很多图像块,在微调时调整不同图像分辨率的位置信息(如下所述)。位置信息
编码在初始化时没有携带任何的2维图像块信息,所有位置信息的空间关系都需要从头开始学
习。
Hybrid Architecture.
作为原始图像块的替代,输⼊的序列可以由卷积获取的特征图来替代。在这个hybrid模型中,
patch embedding projection从CNN特征图中进⾏提取。特别的,特征图的⼤⼩可以是特殊的
1×1,这意味着可以简单的把卷积的特征图拉平并投影变换到Transformer的维度。如上所示,
添加了分类的输⼊及位置编码。














评论0