400
• 2023 IEEE International Solid-State Circuits Conference
ISSCC 2023 / SESSION 28 / HIGH-DENSITY MEMORIES AND HIGH-SPEED INTERFACE / 28.1
28.1 A 1.67Tb, 5b/Cell Flash Memory Fabricated in 192-Layer
Floating Gate 3D-NAND Technology and Featuring a
23.3Gb/mm
2
Bit Density
Ali Khakifirooz
1
, Eduardo Anaya
2
, Sriram Balasubrahmanyam
2
, Geoff Bennett
1
,
Daniel Castro
2
, John Egler
2
, Kuangchan Fan
2
, Rifat Ferdous
1
, Kartik Ganapathi
1
,
Omar Guzman
2
, Chang Wan Ha
1
, Rezaul Haque
2
, Vinaya Harish
2
, Majid Jalalifar
2
,
Owen W. Jungroth
2
, Sung-taeg Kang
1
, Golnaz Karbasian
1
, Jee-Yeon Kim
1
,
Siyue Li
2
, Aliasgar S. Madraswala
2
, Srivijay Maddukuri
2
, Amr Mohammed
1
,
Shanmathi Mookiah
2
, Shashi Nagabhushan
2
, Binh Ngo
2
, Deep Patel
2
,
Sai Kumar Poosarla
2
, Naveen V. Prabhu
2
, Carlos Quiroga
2
, Shantanu Rajwade
1
,
Ahsanur Rahman
2
, Jalpa Shah
2
, Rohit S. Shenoy
1
, Ebenezer Tachie Menson
2
,
Archana Tankasala
1
, Sandeep Krishna Thirumala
1
, Sagar Upadhyay
2
,
Krishnasree Upadhyayula
2
, Ashley Velasco
2
, Nanda Kishore Babu Vemula
2
,
Bhaskar Venkataramaiah
2
, Jiantao Zhou
1
, Bharat M. Pathak
2
, Pranav Kalavade
1
1
Intel, Santa Clara, CA,
2
Intel, Folsom, CA
Successful deployment of multiple generations of the 4b/cell (QLC) floating-gate 3D-
NAND technology has paved the way for the industry-wide adoption of QLC [1-4]. The
transition to 5b/cell (PLC) will be another steppingstone to accelerating bit density growth
and expanding Flash storage to wider markets, where a lower cost at a reasonable
performance is the paramount requirement.
In this paper, we present the first PLC NAND chip that is fabricated in a 192-layer floating-
gate (FG) technology. With a die capacity of 1.67Tb and area of 73.3mm
2
, it delivers a
bit density of 23.3Gb/mm
2
. The chip can also be configured as a 1.33Tb QLC or a 1Tb
3b/cell (TLC), achieving bit densities of 18.6Gb/mm
2
and 14.0Gb/mm
2
, which are 24%
and 21% better than the best previously reported QLC [4] and TLC [5] bit densities.
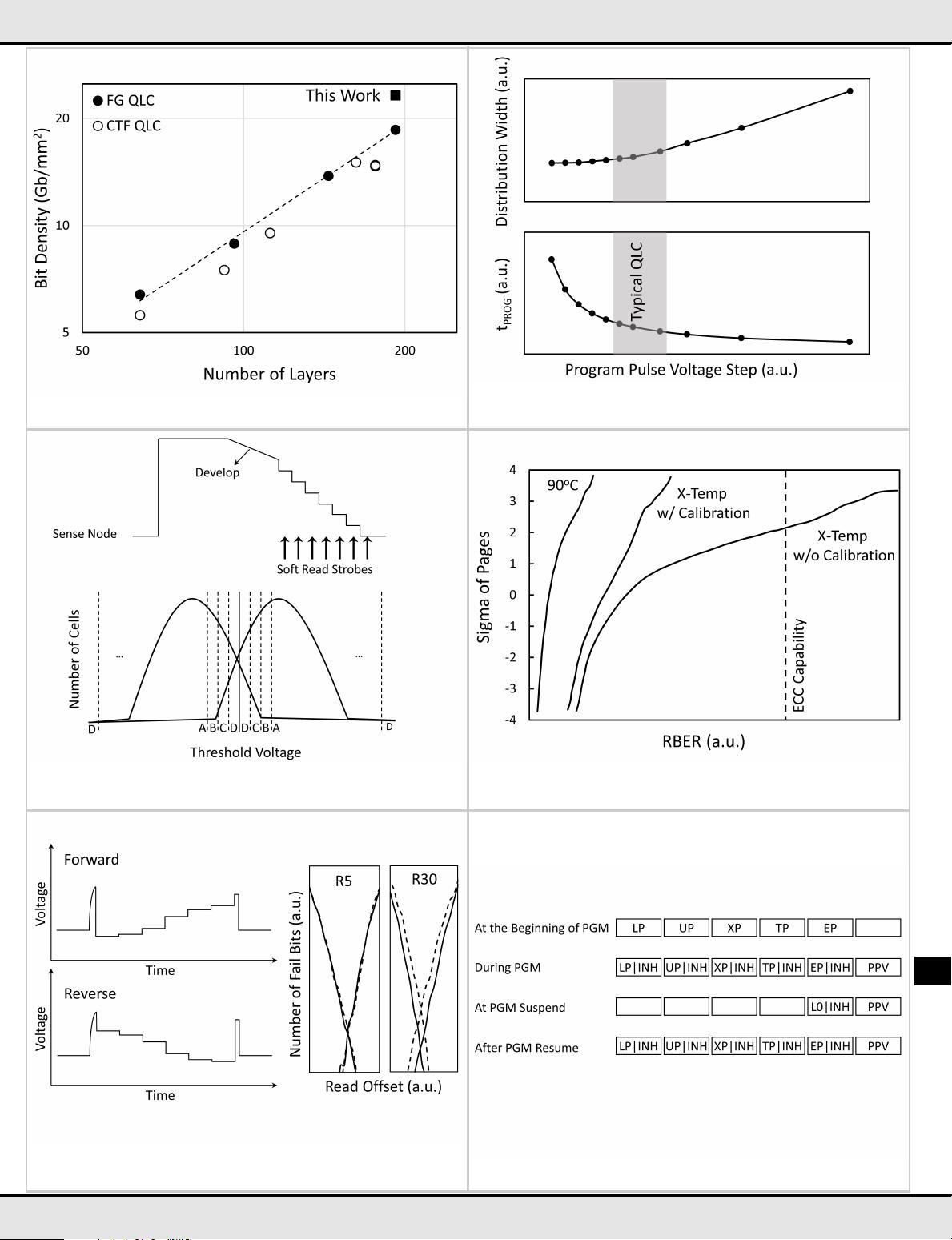
Figure 28.1.1 shows the bit density scaling trend with the number of layers,
demonstrating superior scaling efficiency of this work compared to other QLC
implementations. We describe key innovations to enable reliable PLC operation and the
features implemented to support system-level usage, including a fast soft-bit read
algorithm capable of handling the presence of defective BLs; a fast read-calibration
algorithm, and a reverse-read waveform to improve the read margin, SLC-write-through
and program suspend, as well as a resume algorithm compatible with the above read
operations.
Programming 32 states to encode 5b of data per cell, within a limited threshold voltage
window, poses a significant challenge. To minimize the interference from neighboring
WLs, we use a two-pass coarse/fine programming algorithm. The resilience of floating
gate technology to charge loss, compared to charge-trap Flash technology that suffers
from lateral charge diffusion in the nitride layer, is a key enabler to increasing the number
of bits per cell. However, both technologies are affected by random telegraph noise (RTN)
due to traps in the polysilicon channel and the interfaces, which imposes a lower bound
on how tight the states can be placed. As shown in Fig. 28.1.2, reducing the program
gate step is an efficient way to tighten the threshold voltage distributions for TLC and
QLC at the cost of increased program time; however, it offers diminishing benefits beyond
what is typically used for QLC. Therefore, increasing the error correction code (ECC)
capability is required to reliably read the data. Most QLC implementations have already
increased the number of ECC bytes, compared to their TLC counterparts. However, to
avoid the area penalty we kept the number of ECC bytes unchanged and augmented ECC
correction capabilities with a fast soft-bit read (FSBR) algorithm. To maximize the
information that can be encoded in 2b (for a total of 3b including the hard-bit data), we
implemented a 7-strobe read algorithm, which groups the bits into four buckets from
the strongest to weakest confidence. This is achieved by sensing the cells at different
sense currents instead of different WL voltages, by modulating the voltage applied to
the back of the sensing capacitor after it is discharged in proportion to the BL current,
as shown in Fig. 28.1.3. The average read time (t
R
) for the proposed FSBR is 354s and
a balanced 6-6-7-6-6 Gray code was used to limit the maximum t
R
to 386s.
NAND-Flash memories typically include additional redundant columns to repair defective
BLs. In this work, to further decrease the die area, we reduced the number of redundant
columns by more than 70%, and allow for unrepaired defective BLs, which may be
present in a small percentage of the dies, so long as the unrepaired BLs contribution to
the raw bit error rate (RBER) is significantly smaller than the error correction capability.
However, the presence of unrepaired defective BLs adversely impacts the quality of soft-
read operation since these bits are sensed as the strongest 0s and 1s. To circumvent
this, special open/short sensing operations were added to the read algorithm to identify
defective BLs and place them in the weakest confidence bucket, as shown in Fig. 28.1.3.
With the tight spacing between the threshold voltage states, it is extremely important to
place the read levels at the optimal location between neighboring states. While optimum
read levels are set during NAND manufacturing, die-to-die variations during the lifetime
of the NAND operation and under cross-temperature (x-temp) conditions cannot be fully
compensated. To address this, we implemented a 5-strobe fast read calibration algorithm
by modulating the voltage applied to the back of the sensing capacitor and counting the
number of bits that flip between strobes. Experimental data shows that this scheme is
more accurate than the 3-strobe algorithm proposed earlier [1]. Moreover, compared to
algorithms that are based on counting the total number of bits that belong to different
states [3], the proposed algorithm does not require a perfectly uniform threshold voltage
distribution, which is difficult to achieve with an increased number of states. Figure 28.1.4
reports the RBER distribution; thereby, demonstrating the robustness of the proposed
algorithm to bring the RBER well below the ECC correction capability even under x-temp
conditions.
To further improve the read margin and reduce the RBER, a reverse read waveform is
implemented, as shown schematically in Fig. 28.1.5. Traditionally, the motivation to
implement a reverse read has been to reduce t
R
by avoiding the slow ramp down of the
pass voltage to the lowest read level, which is present in a forward read waveform.
However, in this work the main motivation is to improve the read margin for the higher
read levels with a negligible effect on the lower levels: shown through experimental data
in Fig. 28.1.5. With a forward read waveform, the cells with a higher threshold voltage
are kept in the depletion regime during earlier read levels, with a significantly different
trap occupancy compared to the inversion regime where they are being sensed. The
reverse waveform improves the read margin by maintaining these cells in the inversion
regime prior to their corresponding sense operation.
In order to enable a balanced Gray data encoding, all five pages of data are needed in
both the first and second pass of the program algorithm. While this is the norm for most
QLC implementations except [1], it requires the storage of a few megabytes of data per
die in a DRAM or similar media. Instead, we use a 1b/cell (SLC) cache on the NAND die
to store the data needed for the two-pass PLC programming algorithm. To keep the area
overhead of the SLC cache to less than 2%, we improved the SLC reliability to 250k
program/erase (P/E) cycles, commensurate with 1k of P/E cycle capability in the present
PLC work.
The capability to suspend the program algorithm, to service read requests, is extremely
important for enterprise-level mixed workloads. To minimize the static page buffer (SPB)
area, we did not add extra data latches beyond what is needed for the QLC program
operation and encoded inhibit information during the program algorithm as erase data
(L0). To support FSBR during a program suspend, a minimum of 3 data latches are
needed per BL. To enable this, we rely on the fact that a copy of the data being
programmed is available in the SLC cache. When a program suspend command is
received, the die constructs the inhibit information (INH) by performing a logical AND
operation between the data latches, keeps INH in one of the latches, and releases the
rest of the latches for the read operation. To resume the program operation, the user
data is first read from the SLC cache, combined with the INH information through a
logical OR operation, and then restored to the corresponding data latches, as illustrated
in Fig. 28.1.6.
A die photograph of the fabricated NAND chip is shown in Fig. 28.1.7 along with key
metrics of the present work.
References:
[1] A. Khakifirooz et al., “A 1Tb 4b/Cell 144-Tier Floating-Gate 3D-NAND Flash Memory
with 40MB/s Program Throughput and 13.8Gb/mm
2
Bit Density,” ISSCC, pp. 424-425,
2021.
[2] T. Pekny et al., “A 1-Tb Density 4b/Cell 3D-NAND Flash on 176-Tier Technology with
4-Independent Planes for Read Using CMOS-Under-the-Array,” ISSCC, pp. 132-133,
2022.
[3] W. Cho et al., “A 1-Tb, 4b/cell, 176-stacked-WL 3D-NAND Flash Memory with
Improved Read Latency and a 14.8Gb/mm
2
Density,” ISSCC, pp. 134-135, 2022.
[4] J. Yuh et al., “A 1-Tb 4b/Cell 4-Plane 162-Layer 3D Flash Memory with a 2.4-Gb/s
I/O Speed Interface,” ISSCC, pp. 130-131, 2022.
[5] M. Kim et al., “A 1Tb 3b/Cell 8th-Generation 3D-NAND Flash Memory with 164MB/s
Write Throughput and a 2.4Gb/s Interface,” ISSCC, pp. 136-137, 2022.
978-1-6654-9016-0/23/$31.00 ©2023 IEEE