
> Author: Runsen
# 首尔自行车共享需求预测

## 1. 问题陈述
目前,在许多城市引入了租赁自行车,以增强出行的便利性。将租赁自行车在合适的时间提供给公众并使其易于获取非常重要,因为这可以减少等待时间。最终,为城市提供稳定的租赁自行车供应成为一个主要问题。关键部分是对每个小时所需的自行车数量进行预测,以实现稳定的租赁自行车供应。
## 2. 数据描述
该数据集包含天气信息(温度、湿度、风速、能见度、露点、太阳辐射、降雪量、降雨量)、每小时租赁自行车数量和日期信息。
属性信息:
- 日期:年-月-日
- 租赁自行车数量 - 每小时租赁的自行车数量
- 小时 - 一天中的小时
- 温度 - 摄氏温度
- 湿度 - %
- 风速 - 米/秒
- 能见度 - 10米
- 露点温度 - 摄氏温度
- 太阳辐射 - MJ/平方米
- 降雨量 - 毫米
- 降雪量 - 厘米
- 季节 - 冬季、春季、夏季、秋季
- 节假日 - 节假日/非节假日
- 工作日 - 非工作时间、工作时间
## 3. 项目的业务用途是什么?
用户可以核实他们的行程详情(距离、持续时间)和身体活动的度量(消耗的卡路里)。随着这种智能技术和便利性,租赁自行车的使用量每天都在增加。因此,有必要管理自行车租赁需求,并为用户提供持续便利的服务。本研究提出了一种基于机器学习的方法,包括天气数据,以预测整个城市的公共自行车需求。使用机器学习模型来预测每小时所需的租赁自行车数量。自行车需求必须与可用的独立变量建模。管理层可以根据需求的不同特征来调整业务策略,以满足需求水平并符合客户的期望。此外,该模型将是管理层了解新市场需求动态的一种良好方式。
## 4. 模型构建步骤
1)读取和理解数据
2)可视化数据
3)数据准备
4)将数据分割为训练集和测试集
5)对训练数据进行特征缩放
6)构建模型
7)对训练数据进行残差分析
8)使用最终模型进行预测
9)模型评估
## 5. 数据可视化
### 1)热力图
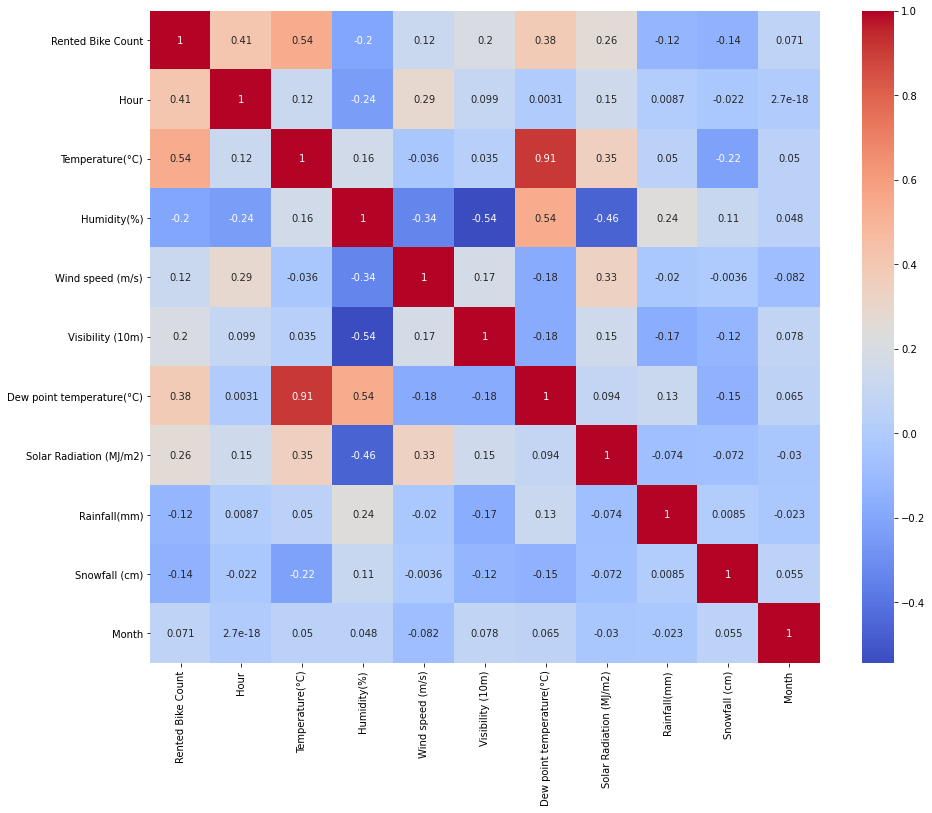
- 从热力图可以明显看出,变量“小时”、“温度”和“露点温度”对目标变量影响较大。
- 我们可以看到独立变量“温度”和“露点温度”高度相关。
### 2)按季节分的租赁自行车数量
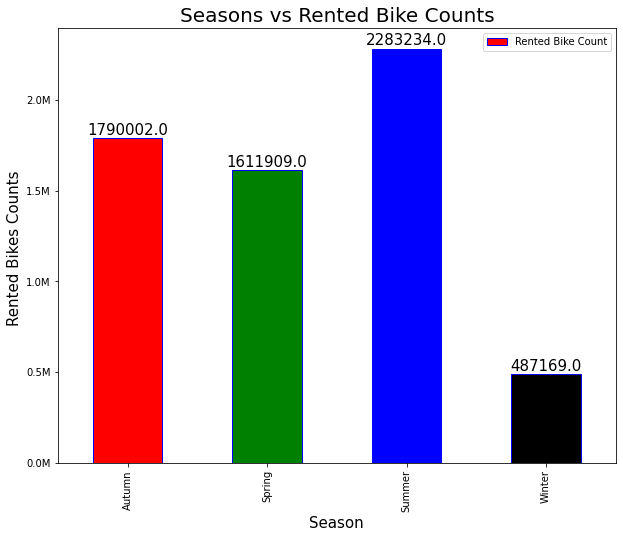
- 从图表中可以看出,夏季租赁自行车数量最多。
- 冬季,与其他季节相比,人们更倾向于租赁较少的自行车。
### 3)假日和非假日租赁自行车数量

- 假日租赁的自行车很少。
- 大多数自行车是在非假日租赁的。
### 4)太阳辐射与租赁自行车数量

### 5)租赁自行车数量和一天的小时数
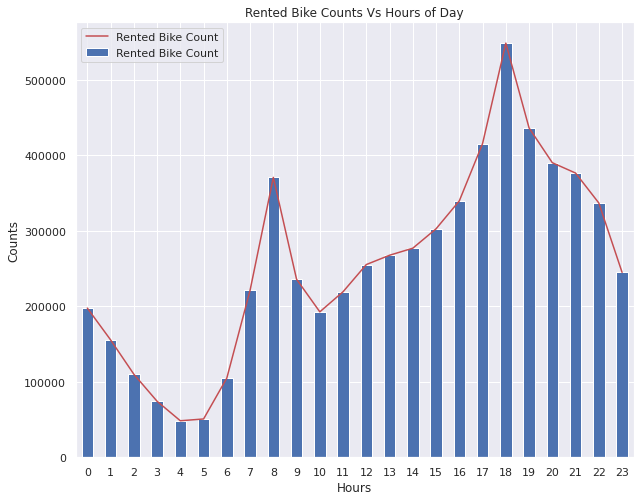
- 在下午4点到晚上10点之间,租赁自行车的使用量很大。这意味着人们在下班回家时会租用自行车,以避免交通拥堵。
- 早上8点,租赁自行车的使用量高于正常水平。这意味着人们会租用自行车去上班或送孩子上学。
## 6)特征重要性

##
 首尔自行车共享需求预测 .zip (3个子文件)
首尔自行车共享需求预测 .zip (3个子文件)  80724.ipynb 1.15MB SeoulBikeData.csv 590KB README.md 4KB
80724.ipynb 1.15MB SeoulBikeData.csv 590KB README.md 4KB资源评论


小刘要努力。
- 粉丝: 3w+
- 资源: 255









最新资源
- Python爬虫资源:全面掌握爬虫技术的综合指南
- 人工智能-智能助手-凤希AI伴侣:多功能整合,效率提升利器
- 新冠病毒密接者跟踪系统设计与实现(代码+数据库+LW)
- Xmind-for-Windows-x64bit-24.01.13311-畅享版
- XMind2023-v23.11.04336-x64-Repack-畅享版
- XMind2024-mac畅享版
- 基于Spring Boot的夕阳红公寓管理系统的设计与实现(代码+数据库+LW)
- 基于神经音频编解码器的高效语音分离技术研究-Codecformer模型
- 源感知神经音频编解码器SD-Codec的技术与应用
- 导师信息评价-导师评价(包含全国各大高校各个专业).xls
- 源码程序,前端vue,后端php,前后端全开源
- 手边酒店V25.0.22小程序前端+后端.zip
- 基于java的简易版营业厅宽带系统+jsp源码(java毕业设计完整源码+LW).zip
- 11基于java的旅游管理系统设计新版源码+数据库+说明
- mmexport1735574041820.jpg
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


