

626
IEEE
TRANSACTIONS ON
COMPONENTS,
HYBRIDS,
AND
MANUFACTURING
TECHNOLOGY,
VOL.
16,
NO.
7,
NOVEMBER
1993
The
ELSA
Wafer Scale Integration Project
Peter
Ivey
Abstract-In this paper we outline some of the technology,
successful and unsuccessful, of part of a large European project in
wafer scale integration
(WSI).
The work described is an attempt
to build a 64 by 64 array processor on a 4-in wafer. Such a
processor would have a computing power in excess of
10
billion
operations per second.
A
test chip and a demonstration system,
which achieves such a processing power, is also outlined.
I.
INTRODUCTION
HE intention of this paper is to provide an overview
of
T
the ELSA project (ELSA-the European Large SIMD
Array) which was part of the European Community funded
Esprit Project
824,
Wafer Scale Integration. The aim is to
show the successes and failures of the project, which was
a major undertaking involving
8
companies, subcontractors,
and research institutes in 4 European Community countries
and to allow readers to glimpse the breadth and depth of the
investigation. Many of the results have applications in other
packaging and large area device projects and are, therefore,
of
wider interest than to just the wafer scale integration (WSI)
community.
Our work can be seen, in some sense, as steps on the
road to ultra-large chips and wafer-sized circuits. Whatever
the geometry
of
the underlying silicon, there is no doubt that
more can be put onto a “large” chip or wafer than can be put on
a
conventional device.
To
achieve large chips, economically,
requires reconfiguration and defect tolerance and our work has
been predominately a study of techniques and architectures for
achieving these goals.
The main objective of the ELSA project was to provide
the opportunity to develop and evaluate WSI technology.
‘The final outcome of the project was to be a wafer level
SIMD
processor, together with the necessary software support
tools and an evaluation board. WSI was considered relevant
to
a number of applications. The wafer has many potential
itpplications, such as in telecommunications, image processing,
pattern matching, artificial intelligence, robotics, military, and
aerospace, etc.
The range of hardware technologies that was developed
and evaluated as part of the whole program was very wide
1
I],
[2] including wafer packaging, defect tolerance, over-
wafer copper tracking, e-beam programmable transistors, soft
reconfiguration, etc. The aim
of
this paper is to show how some
of these technologies were exploited in the ELSA project.
Manuscript received March
27,
1993; revised July 22, 1993. This work was
,upported by SGS-Thomson, BT Laboratories, and the European Community.
This paper was presented at the International Conference on Wafer Scale
Integration. San Francisco,
CA,
January 2Ck22, 1993.
The author is with the Department
of
Electronic and Electrical Engineering,
IJniversity
of
Sheffield, Sheffield
S1
3JD,
U.
K.
IEEE
Log
Number 9212045.
The project consisted of many components. In the first
phase we analyzed the architectures that were suitable for
WSI [3] and concluded that generality and regularity were
essential if a successful “product” was to be produced. In
parallel with this, the basic technologies were developed and
demonstrated on silicon [4],
[5].
The design
of
the processor
was commenced and a prototype chip was developed to allow
the basic architecture to be tested
[3], [6]. In the second phase
of the project the wafer scale device (ELSA) was designed,
building on the successful outcome of the demonstrator chip.
A second task involved the development
of
the software
tools necessary to allow applications to be programmed on
the array. These tools were designed to be
of
sufficiently high
performance to enable practical use of the final system. This
task involved very little risk since the technology of compiler
design is well understood and the type
of
system required is
relatively simple compared to a compiler for a general purpose
computer or microprocessor.
In a third task, a prototype system was fabricated in order
that development
of
the compiler and simulator could take
place. This prototype was then developed further to incorporate
the reconfigured wafer. It was intended that at the final stage
of the project a number of highly parallel algorithms would
be demonstrated on the wafer system.
In this paper we will concentrate on the hardware aspects
of the ELSA project, leaving the reconfiguration and software
to be covered in
[7].
Firstly, in Section 11, we will outline the
architecture of the wafer, concentrating on the basic processing
element and the reconfiguration hardware, while in Section
111
we will describe the ELSA hardware implementation and
packaging. In Section
IV
we will outline the main results of the
project and the lessons learned. In addition we will discuss the
ELSA demonstrator and its expected performance by reference
to an emulator system which was designed using demonstrator
chips. In Section
V
we will conclude the paper and summarize
the overall achievements of the project.
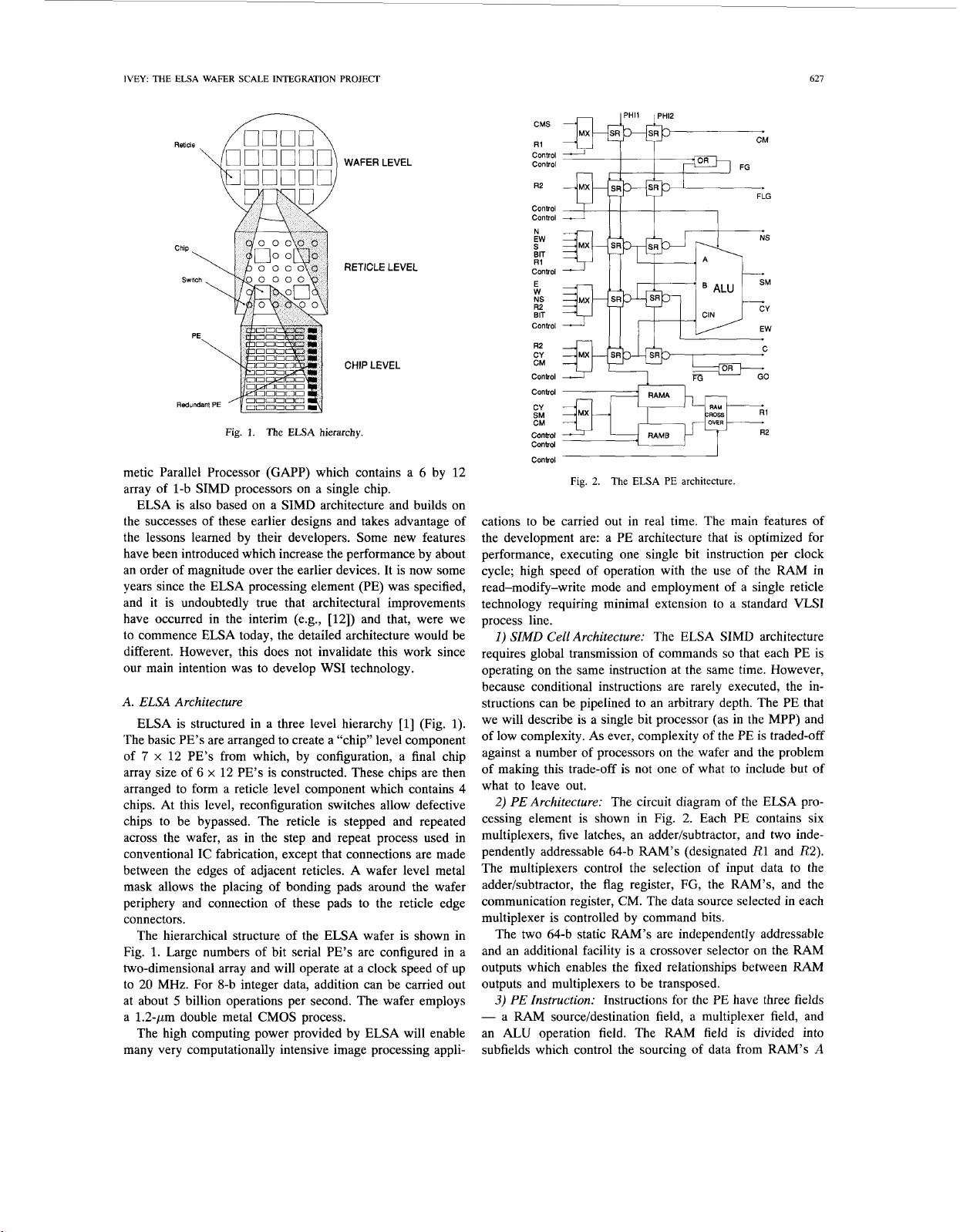
11.
ELSA
Large arrays of simple processors have a long history.
As
early as 1962, an array of
32
by 32 SIMD processors was
proposed (but never built) by Slotnick
et
al.
[8].
Later, in
1966, Illiac
IV
was developed at the University of Illinois [9]
and a small (8 by 8) version was built. In 1975, International
Computers Ltd. developed the
DAP
[lo],
which is a 64
by 64 array of simple SIMD processors, and this was one
of the first commercial applications
of
array computers. In
1983, Goodyear Aerospace produced the Massively Parallel
Processor (MPP) for NASA [ll] and most recently (in 1984)
Martin Marietta and NCR introduced the Geometric Arith-
0148-6411/93$03.00
0
1993 IEEE
剩余10页未读,继续阅读
资源评论


crawlsnailx
- 粉丝: 0
- 资源: 1









最新资源
- 基于java+ssm+mysql的网络类课程思政学习系统开题报告.doc
- 基于java+ssm+mysql的网上茶叶销售平台开题报告.docx
- 基于java+ssm+mysql的网上茶叶销售平台任务书.doc
- MATLAB代码:含风光柴储微网多目标优化调度 关键词:微网调度 风光柴储 粒子群算法 多目标优化 参考文档:《基于多目标粒子群算法的微电网优化调度》 仿真平台:MATLAB 平台采用粒子群实现求解
- 西门子伺服液压PID模板 程序包括 1整套西门子smart200 PLC程序, 2昆仑通态MCGS程序, 3东元伺服 4电气图纸. 5液压机械图 6功能说明书 7注释详细,完整项目资料 8外挂编码器
- 基于低通滤波器的语音降噪matlab模型, 相关fir,iir滤波器设计
- ad9361,AD9361vivado2019.2 vitis 下verilog工程代码及工程说明文档
- 永磁直驱风力发电系统,MATLAB simiulink,滑模控制,永磁同步电机,直驱式风力发电 风力机才用MPPT算法,机侧变流器采用滑模控制转速外环,PI控制电流内环,网侧逆变器均采用PI控制
- 微电网中的最优调度matlab例程,用yalmip+cplex求解器求解,以一天的运行费用最小为目标函数
- 基于matlab的yalmip+cplex的两阶段鲁棒微电网two-stage robust optimization 微电网双层场景两阶段鲁棒规划方法,目标函数包含投资成本和运行成本,其中,投资成本
- ESP32学习笔记 - 创建两个GATT服务(BLE-UART+OTA)
- 综合能源优化调度,注释清晰,修改简单,完全可以修改成自己需要的程序,注释清晰,算法思想简单,便于修改,自己用过的,物有所值
- 基于OpenGL和Qt的3D地形显示demo软件源代码,2019年编写的,当时可分别在ubuntu和Windows系统下编译成功,两个平台下的版本头文件和工程文件略有不一样,均可提供源代码,详见图片
- 关键词:主从博弈;共享储能;优化运行;电热综合需求响应;电网技术复现; 主题:基于主从博弈理论的共享储能与综合能源微网优化运行研究 提出共享储能背景下微网运营商与用户聚合商间的主从博弈模型,并证明S
- 自动驾驶道决策与控制实车测试算法 基于视觉传感器获得场景信息,构建两车道驾驶态势图 红绿灯检测停车,及动态目标车速跟随算法 together future~
- 微网优化调度 灰狼算法 多目标 低碳调度 MATLAB代码:基于多目标灰狼算法的冷热电综合三联供微网低碳经济调度 参考文档:《基于改进多目标灰狼算法的冷热电联供型微电网运行优化-戚艳》灰狼算法以及微
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


