1 Introduction
1.1 What is machine learning (ML)?
• Data is being produced and stored continuously ( “big data”):
– science: genomics, astronomy, materials science, particle accelerators. . .
– sensor networ ks: weather measurements, traffic. . .
– people: social netwo r ks, blogs, mobile phones, purcha ses, bank tra nsactions. . .
– etc.
• Data is not r andom; it contains structure that can be used to predict outcomes, or gain knowl-
edge in some way.
Ex: patterns of Amazon purchases can be used to recommend items.
• It is more difficult t o design algor it hms for such tasks (compared to, say, sort ing an array or
calculating a payro ll) . Such algorithms need data.
Ex: construct a spam filter, using a collection of email messages labelled as spam/not s pam.
• Data mining: the application of ML methods to large databases.
• Ex of ML applications: f raud detection, medical diagnosis, speech or fa ce recognition. . .
• ML is programming computers using data (past experience) to optimize a performance criterion.
• ML relies on:
– Stat istics: making inferences from sample data.
– Numerical algorithms (linear alg ebra, opt imizatio n) : optimize criteria, manipulate models.
– Computer science: data structures and programs that solve a ML problem efficiently.
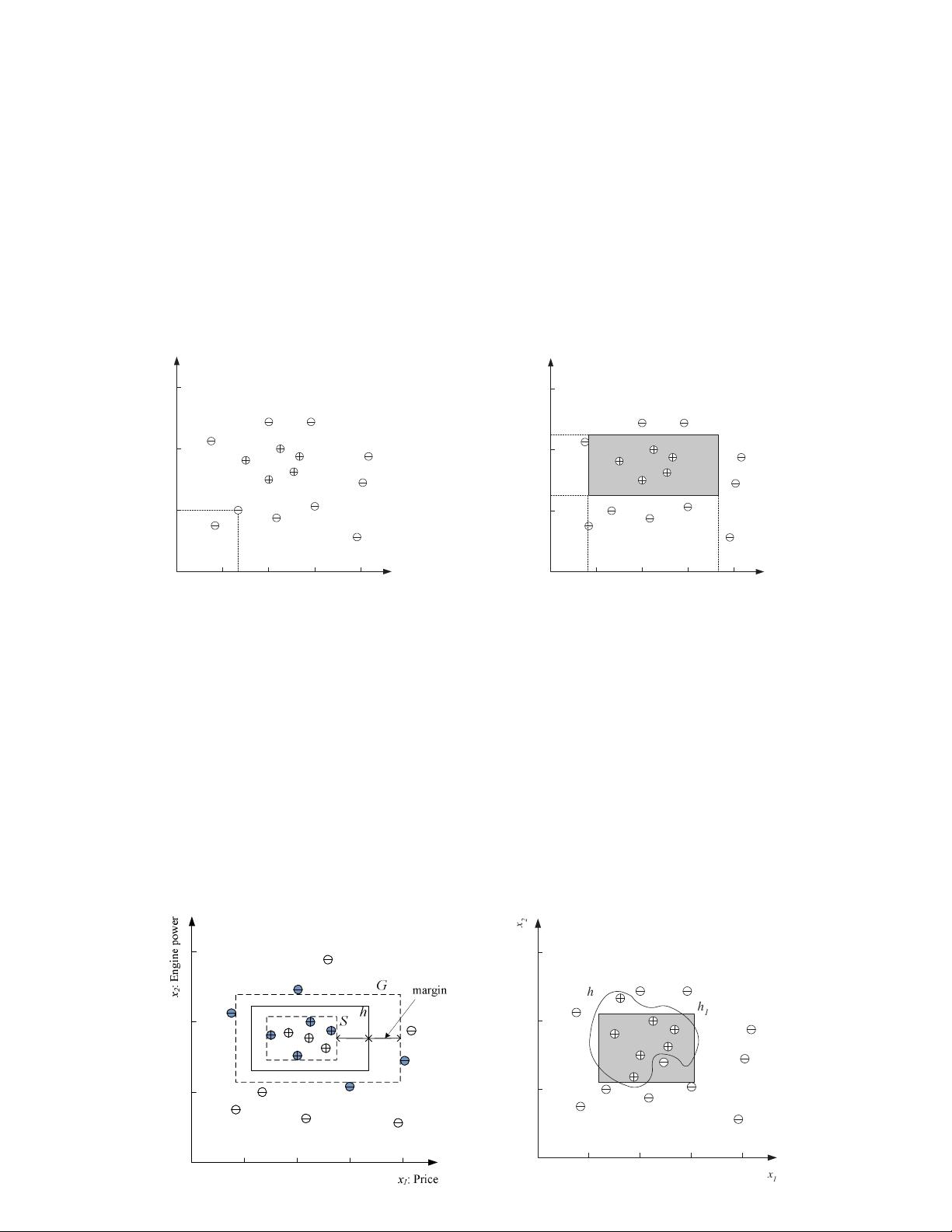
• A model:
– is a compressed version of a database;
– extracts knowledge from it;
– does not have perfect performance but is a useful approximation to the data.
1.2 Examples of ML problems
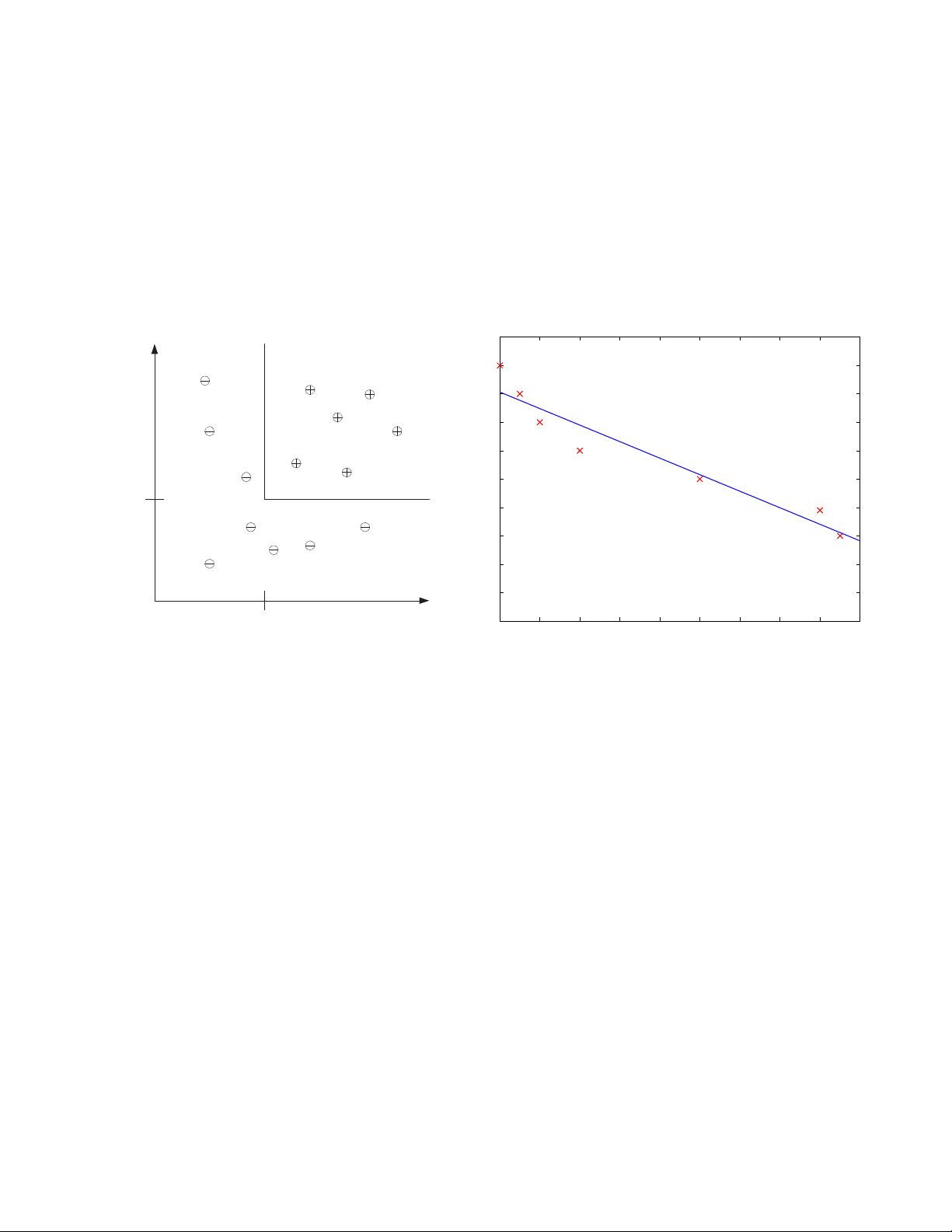
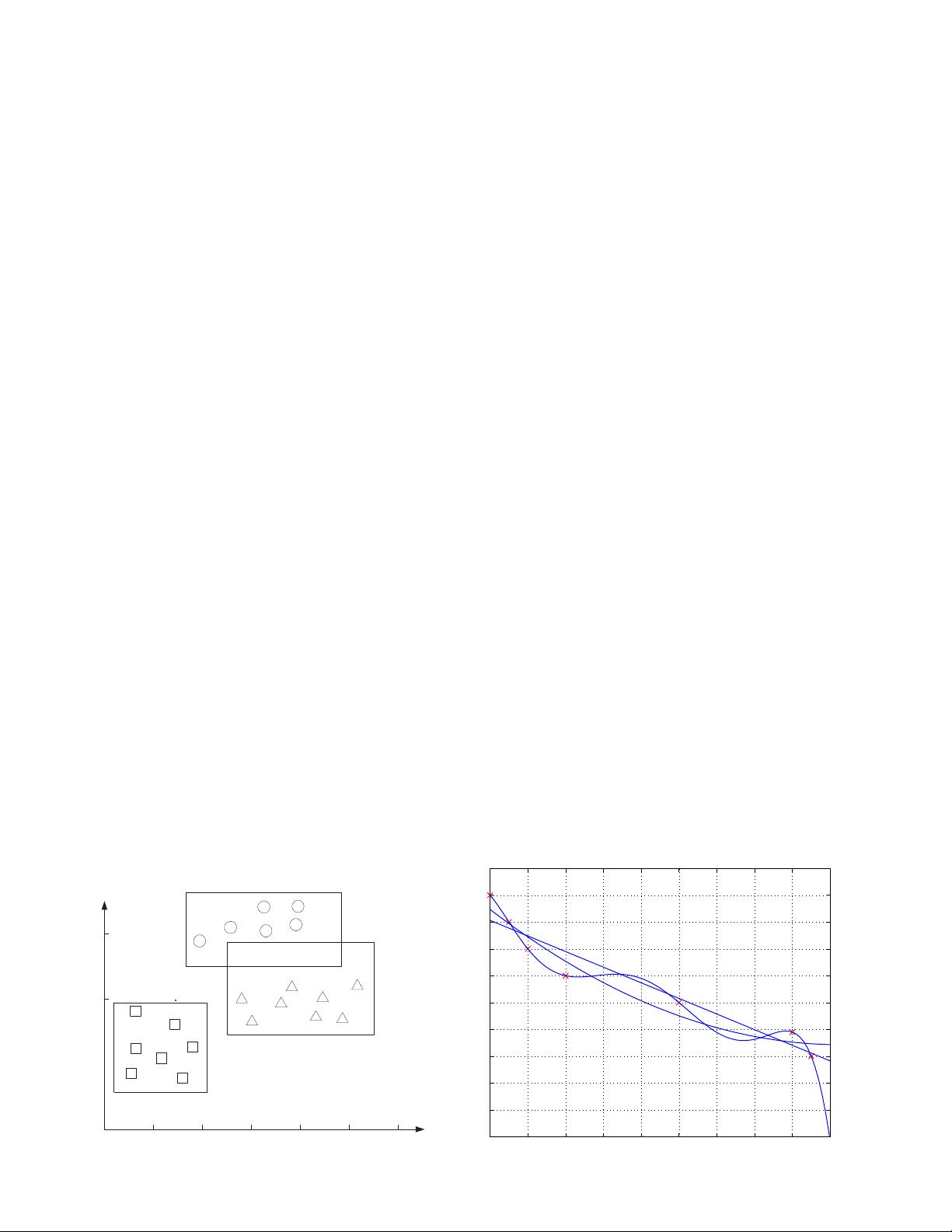
• Supervi s ed learning: labels provided.
– Classification (pattern recognition) :
∗ Face recognitio n. Difficult because of the complex variability in the data : pose and
illumination in a face ima ge, occlusions, glasses/beard/make-up/etc.
Training examples:
Test images:
∗ Optical character recognition: different styles, slant. . .
∗ Medical diagnosis: often, variables are missing (tests are costly).
1