

Grad-CAM: Visual Explanations from Deep Networks
via Gradient-based Localization
Ramprasaath R. Selvaraju · Michael Cogswell · Abhishek Das · Ramakrishna
Vedantam · Devi Parikh · Dhruv Batra
Abstract
We propose a technique for producing ‘visual ex-
planations’ for decisions from a large class of Convolutional
Neural Network (CNN)-based models, making them more
transparent and explainable.
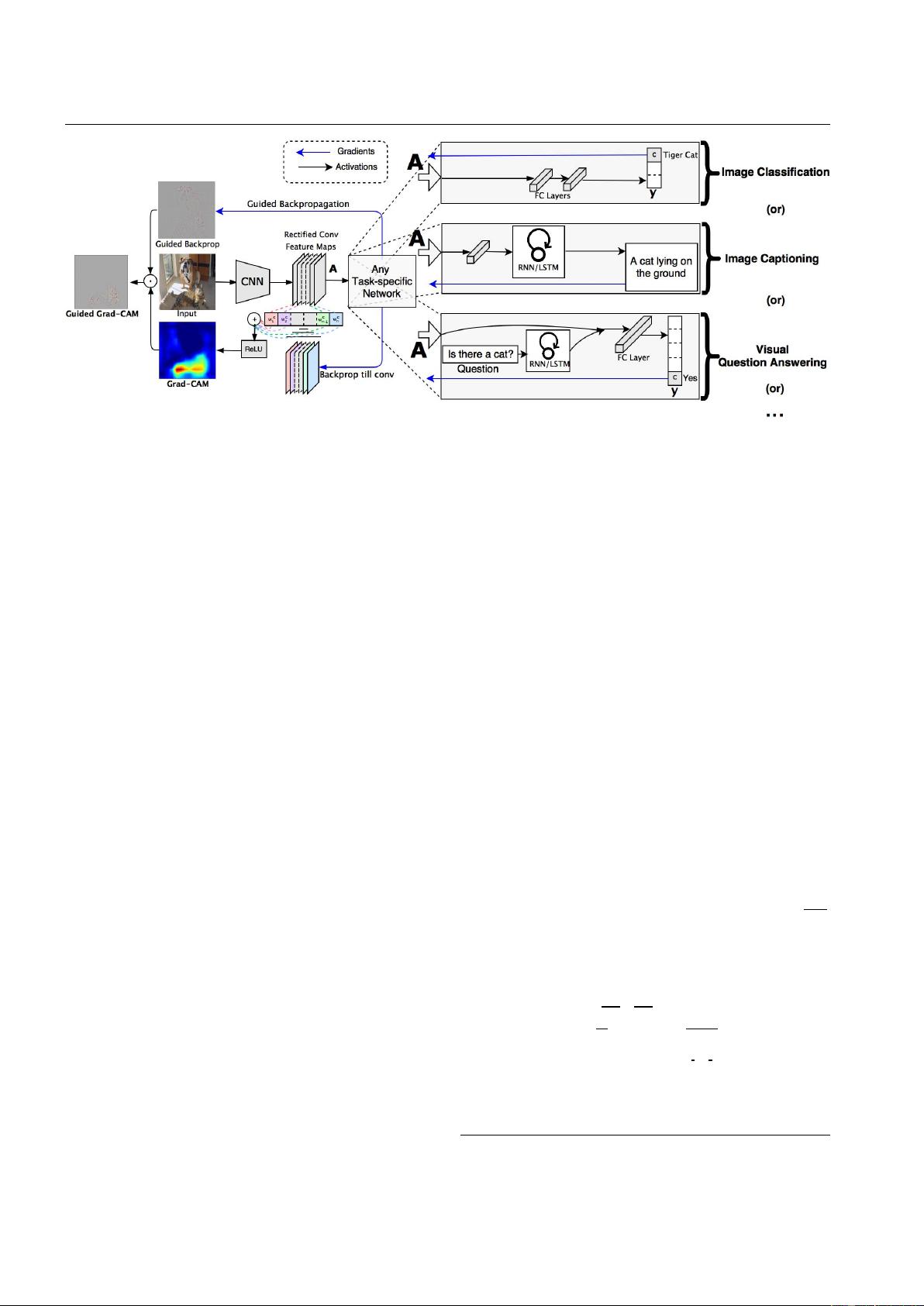
Our approach – Gradient-weighted Class Activation Mapping
(Grad-CAM), uses the gradients of any target concept (say
‘dog’ in a classification network or a sequence of words
in captioning network) flowing into the final convolutional
layer to produce a coarse localization map highlighting the
important regions in the image for predicting the concept.
Unlike previous approaches, Grad-CAM is applicable to a
wide variety of CNN model-families: (1) CNNs with fully-
connected layers (e.g. VGG), (2) CNNs used for structured
outputs (e.g. captioning), (3) CNNs used in tasks with multi-
modal inputs (e.g. visual question answering) or reinforce-
ment learning, all without architectural changes or re-training.
We combine Grad-CAM with existing fine-grained visual-
izations to create a high-resolution class-discriminative vi-
Ramprasaath R. Selvaraju
Georgia Institute of Technology, Atlanta, GA, USA
E-mail: ramprs@gatech.edu
Michael Cogswell
Georgia Institute of Technology, Atlanta, GA, USA
E-mail: cogswell@gatech.edu
Abhishek Das
Georgia Institute of Technology, Atlanta, GA, USA
E-mail: abhshkdz@gatech.edu
Ramakrishna Vedantam
Georgia Institute of Technology, Atlanta, GA, USA
E-mail: vrama@gatech.edu
Devi Parikh
Georgia Institute of Technology, Atlanta, GA, USA
Facebook AI Research, Menlo Park, CA, USA
E-mail: parikh@gatech.edu
Dhruv Batra
Georgia Institute of Technology, Atlanta, GA, USA
Facebook AI Research, Menlo Park, CA, USA
E-mail: dbatra@gatech.edu
sualization, Guided Grad-CAM, and apply it to image clas-
sification, image captioning, and visual question answering
(VQA) models, including ResNet-based architectures.
In the context of image classification models, our visualiza-
tions (a) lend insights into failure modes of these models
(showing that seemingly unreasonable predictions have rea-
sonable explanations), (b) outperform previous methods on
the ILSVRC-15 weakly-supervised localization task, (c) are
robust to adversarial perturbations, (d) are more faithful to the
underlying model, and (e) help achieve model generalization
by identifying dataset bias.
For image captioning and VQA, our visualizations show that
even non-attention based models learn to localize discrimina-
tive regions of input image.
We devise a way to identify important neurons through Grad-
CAM and combine it with neuron names [
4
] to provide tex-
tual explanations for model decisions. Finally, we design
and conduct human studies to measure if Grad-CAM ex-
planations help users establish appropriate trust in predic-
tions from deep networks and show that Grad-CAM helps
untrained users successfully discern a ‘stronger’ deep net-
work from a ‘weaker’ one even when both make identical
predictions. Our code is available at
https://github.com/
ramprs/grad-cam/
, along with a demo on CloudCV [
2
]
1
,
and a video at youtu.be/COjUB9Izk6E.
1 Introduction
Deep neural models based on Convolutional Neural Net-
works (CNNs) have enabled unprecedented breakthroughs
in a variety of computer vision tasks, from image classi-
fication [
33
,
24
], object detection [
21
], semantic segmenta-
tion [
37
] to image captioning [
55
,
7
,
18
,
29
], visual question
answering [
3
,
20
,
42
,
46
] and more recently, visual dialog [
11
,
13
,
12
] and embodied question answering [
10
,
23
]. While
1
http://gradcam.cloudcv.org
arXiv:1610.02391v4 [cs.CV] 3 Dec 2019


剩余22页未读,继续阅读
资源评论













