
1/2
HBase 数据读取流程解析——Client-Server 交互逻辑
HBase 数据读取流程解析-1——Client-Server 交互逻辑
朱立
(北京信息职业技术学院)
摘要:和写流程相比,HBase读数据是一个更加复杂的操作流程,删除操作也并没有真正删
除原有数据,只是插入了一条打上“deleted”标签的数据,而真正的数据删除发生在系统异
步执行Major_Compact的时候。这种实现套路大大简化了数据更新、删除流程,但是对于数据
读取来说却意味着套上了层层枷锁,读取过程需要根据版本进行过滤,同时对已经标记删除的
数据也要进行过滤。
关键词:HBase;数据读取流程;Client-Server交互逻辑
和写流程相比,HBase 读数据是一个更加复杂的操作流程,这主要基于两个方面的原因:其一是因
为整个HBase 存储引擎基于LSM-Like 树实现,因此一次范围查询可能会涉及多个分片、多块缓存甚至多
个数据存储文件;其二是因为HBase 中更新操作以及删除操作实现都很简单,更新操作并没有更新原有数
据,而是使用时间戳属性实现了多版本。删除操作也并没有真正删除原有数据,只是插入了一条打上
“deleted”标签的数据,而真正的数据删除发生在系统异步执行Major_Compact 的时候。很显然,这种
实现套路大大简化了数据更新、删除流程,但是对于数据读取来说却意味着套上了层层枷锁,读取过程
需要根据版本进行过滤,同时对已经标记删除的数据也要进行过滤。
Client-Server交互逻辑
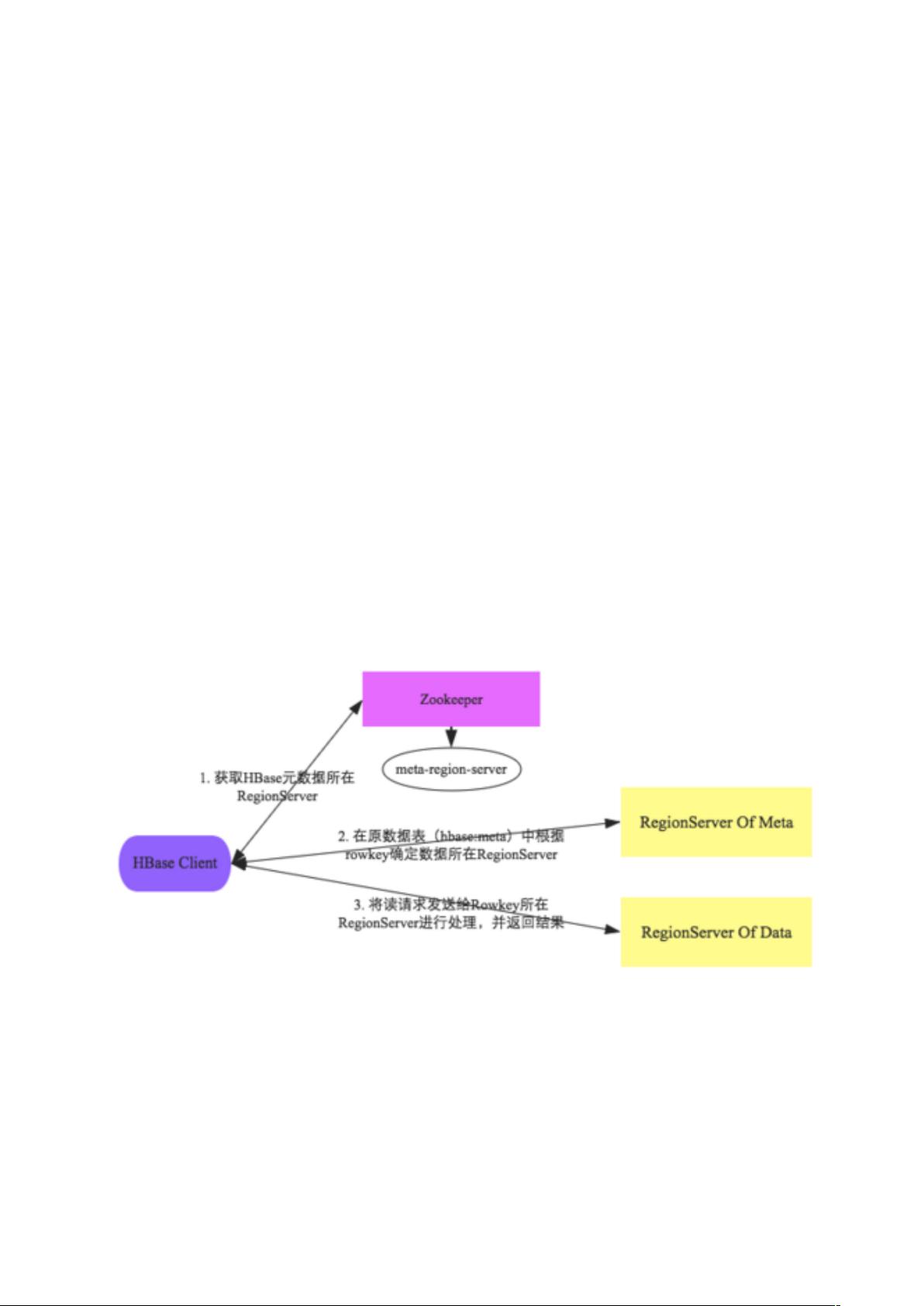
客户端与HBase 系统的交互阶段主要有如下几个步骤:
客户端首先会根据配置文件中zookeeper 地址连接zookeeper,并读取//meta-region-server 节点信
息,该节点信息存储HBase 元数据(HBase:meta)表所在的RegionServer 地址以及访问端口等信息。
用户可以通过zookeeper 命令(get//meta-region-server)查看该节点信息。
根据HBase:meta 所在RegionServer 的访问信息,客户端会将该元数据表加载到本地并进行缓存。
然后在表中确定待检索rowkey 所在的RegionServer 信息。
根据数据所在RegionServer 的访问信息,客户端会向该RegionServer 发送真正的数据读取请求。服
务器端接收到该请求之后需要进行复杂的处理,具体的处理流程将会是这个专题的重点。
通过上述对客户端以及HBase 系统的交互分析,可以基本明确两点:
客户端只需要配置zookeeper 的访问地址以及根目录,就可以进行正常的读写请求。不需要配置集
资源评论


努力搬砖的小王
- 粉丝: 48
- 资源: 7704









最新资源
- 基于ssm的学生综合测评管理系统源码(java毕业设计完整源码+LW).zip
- 基于ssm的理发店管理系统源码(java毕业设计完整源码+LW).zip
- 不同颜色字母标记检测15-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- 永磁同步电机PMSM负载状态估计(龙伯格观测器,各种卡尔曼滤波器)矢量控制,坐标变,永磁同步电机负载转矩估计、PMSM负载转矩测量、负载预测、转矩预测的MATLAB simulink仿真模型,模型包可
- 基于ssm的美容院管理系统源码(java毕业设计完整源码+LW).zip
- 一种萃盘叠放上料设备sw18可编辑全套技术资料100%好用.zip
- 一种包胶前后整平设备sw18可编辑全套技术资料100%好用.zip
- PLC随机密码 动态验证码 动态分期付款 锁机例程 这次是信捷Plc例程 只供参考算法学习,详细功能看下图介绍 学会信捷基本也能自己改为日系PLC(三菱台达等等)本次配送对应信捷触摸屏简单界面,如
- 基于ssm的面向学生成绩分析系统源码(java毕业设计完整源码+LW).zip
- 一种产线开治具下料设备sw18可编辑全套技术资料100%好用.zip
- 基于ssm的网上电子书店源码(java毕业设计完整源码+LW).zip
- LIV-handhold
- PLC 西门子smart200 锁机 最新原创有图片证明配对应西门子smart700IE V3程序,分期期付款 动态验证码,无限次加密 程序例程
- 基于ssm的物业管理系统源码(java毕业设计完整源码+LW).zip
- QT,mingw集成IntelRealSense双目摄像头,完整项目代码
- 基于python的充电桩协议解析工具-根据充电桩与电动汽车通信协议(国标)+用支持其中常用的二十来种协议解析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


