ChatGPT背后的大模型最新有哪些?最新最全《Transformer预训练模型分类》论文,pdf.pdf
需积分: 0 42 浏览量
2023-05-21
17:24:02
上传
评论
收藏 2.73MB PDF 举报


TRANSFORMER MODELS: AN INTRODUCTION AND CATALOG
Xavier Amatriain
Los Gatos, CA 95032
xavier@amatriain.net
February 17, 2023
ABSTRACT
In the past few years we have seen the meteoric appearance of dozens of models of the Transformer
family, all of which have funny, but not self-explanatory, names. The goal of this paper is to offer
a somewhat comprehensive but simple catalog and classification of the most popular Transformer
models. The paper also includes an introduction to the most important aspects and innovation in
Transformer models.
Contents
1 Introduction: What are Transformers 3
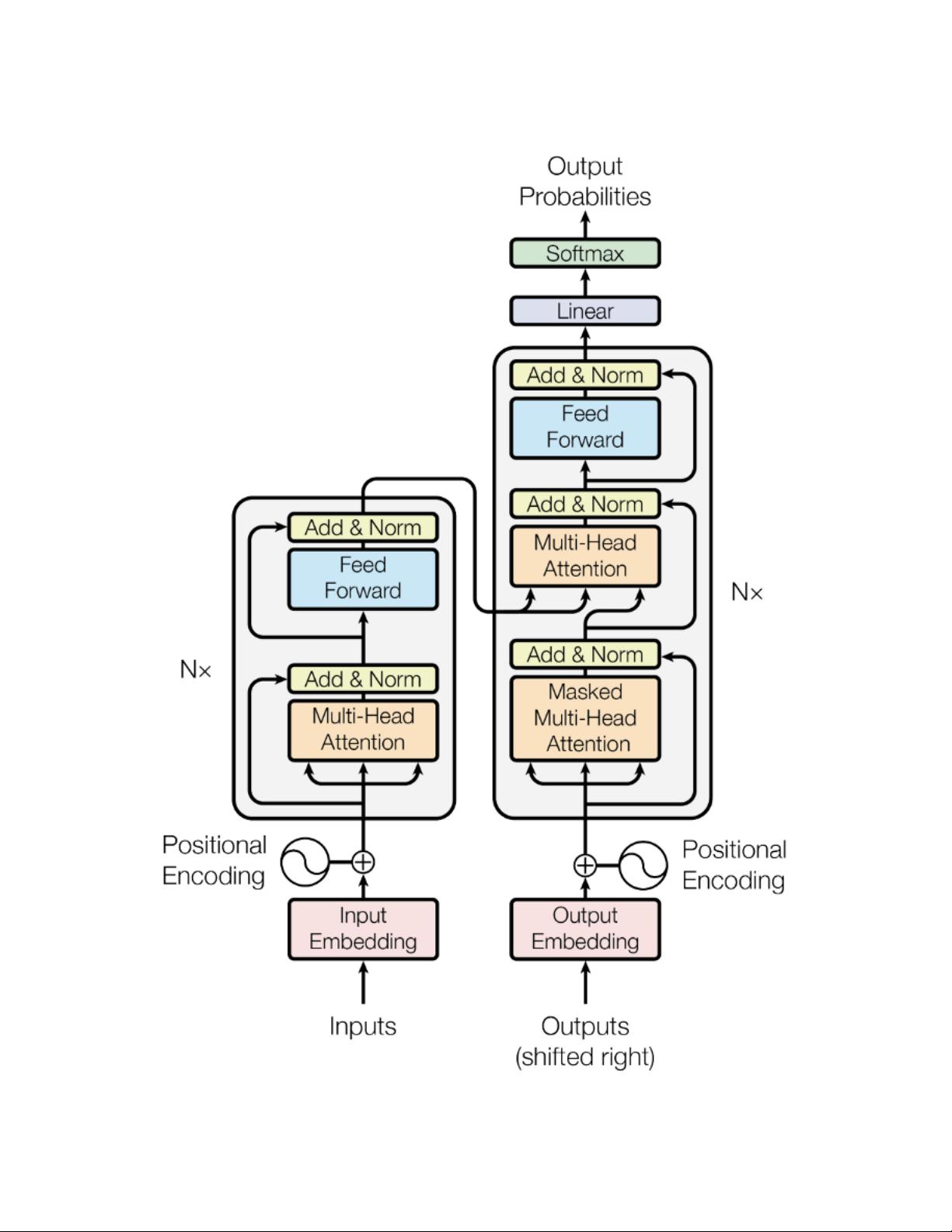
1.1 Encoder/Decoder architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
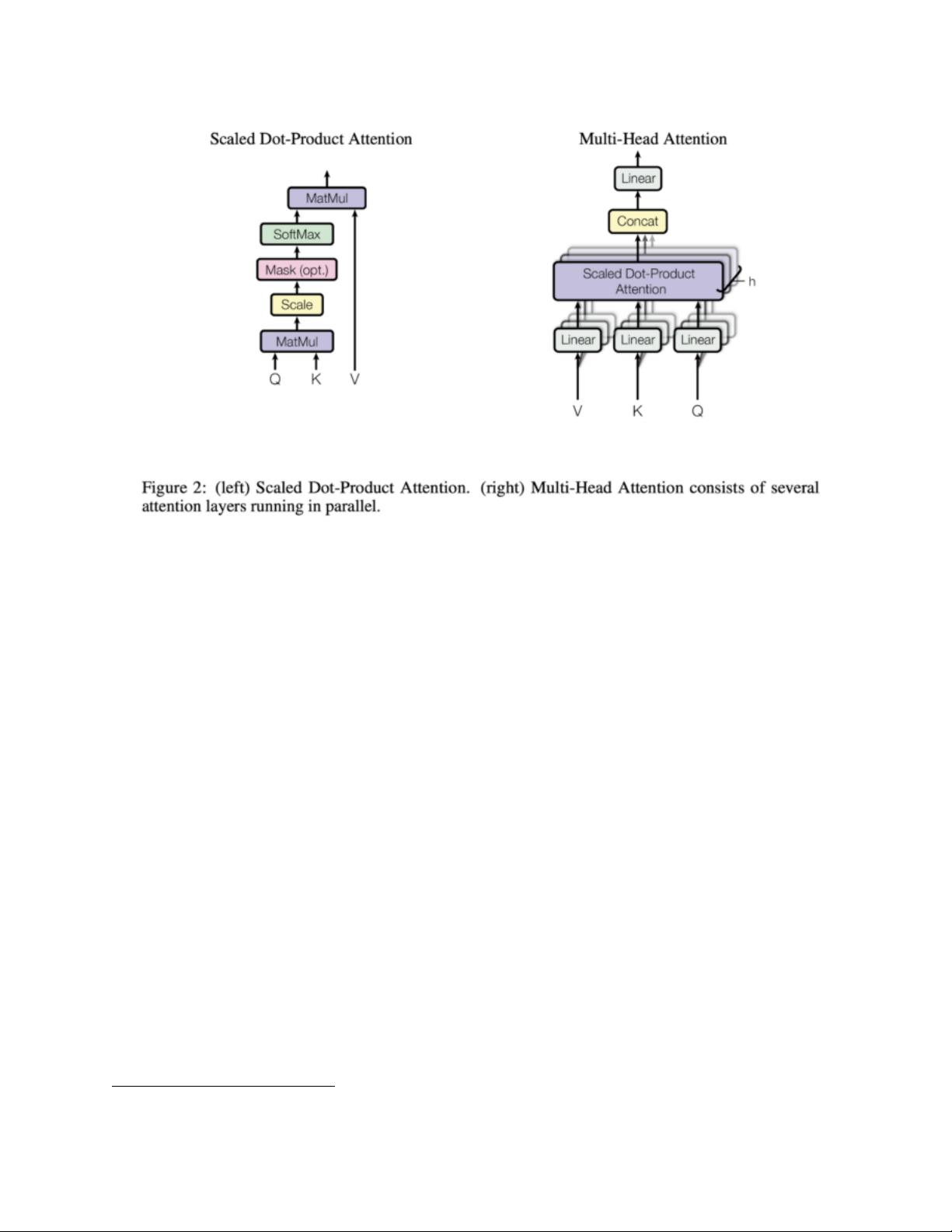
1.2 Attention . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3 What are Transformers used for and why are they so popular . . . . . . . . . . . . . . . . . . . . . . 5
1.4 RLHF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.5 Diffusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 The Transformers catalog 8
2.1 Features of a Transformer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.1 Pretraining Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.2 Pretraining Task . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.3 Application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 Catalog table . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Family Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 Chronological timeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.5 Catalog List . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.5.1 ALBERT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.5.2 AlphaFold . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.5.3 Anthropic Assistant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.5.4 BART . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.5.5 BERT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.5.6 Big Bird . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
arXiv:2302.07730v2 [cs.CL] 16 Feb 2023


剩余35页未读,继续阅读
资源评论













