大数据面试题目大全,面试总结
需积分: 5 40 浏览量
2023-08-19
01:32:37
上传
评论
收藏 6.5MB PDF 举报


大数据面试题汇总大全
第一梯度(6):
Spark,Hive,Flink,数据仓库 Kimball 建模,Java(Web),
Linux
命令,
SpringMvc
,
SpringBoot
,
Mybatis
第二梯度(
5
):
Hadoop(yarn+mapreduce+hdfs),Kafka,Hbase,Azkaban
(了解),Datax(了解)
第三梯度(3):
Zookeeper
,机器学习,联邦学习
1.Hadoop
离线计算
Hadoop 体系是我们学习大数据框架的基石,Hadoop 由三个模块组成:分
布式存储
HDFS
、分布式计算
MapReduce
、资源调度引擎
Yarn
。
MapReduce
、
HDFS
、
Yarn
三驾马车基本垫定了整个数据方向的发展道路。
1.1. HDFS
1.1.1. Hadoop 常用端口号
⚫ dfs.namenode.http-address:50070
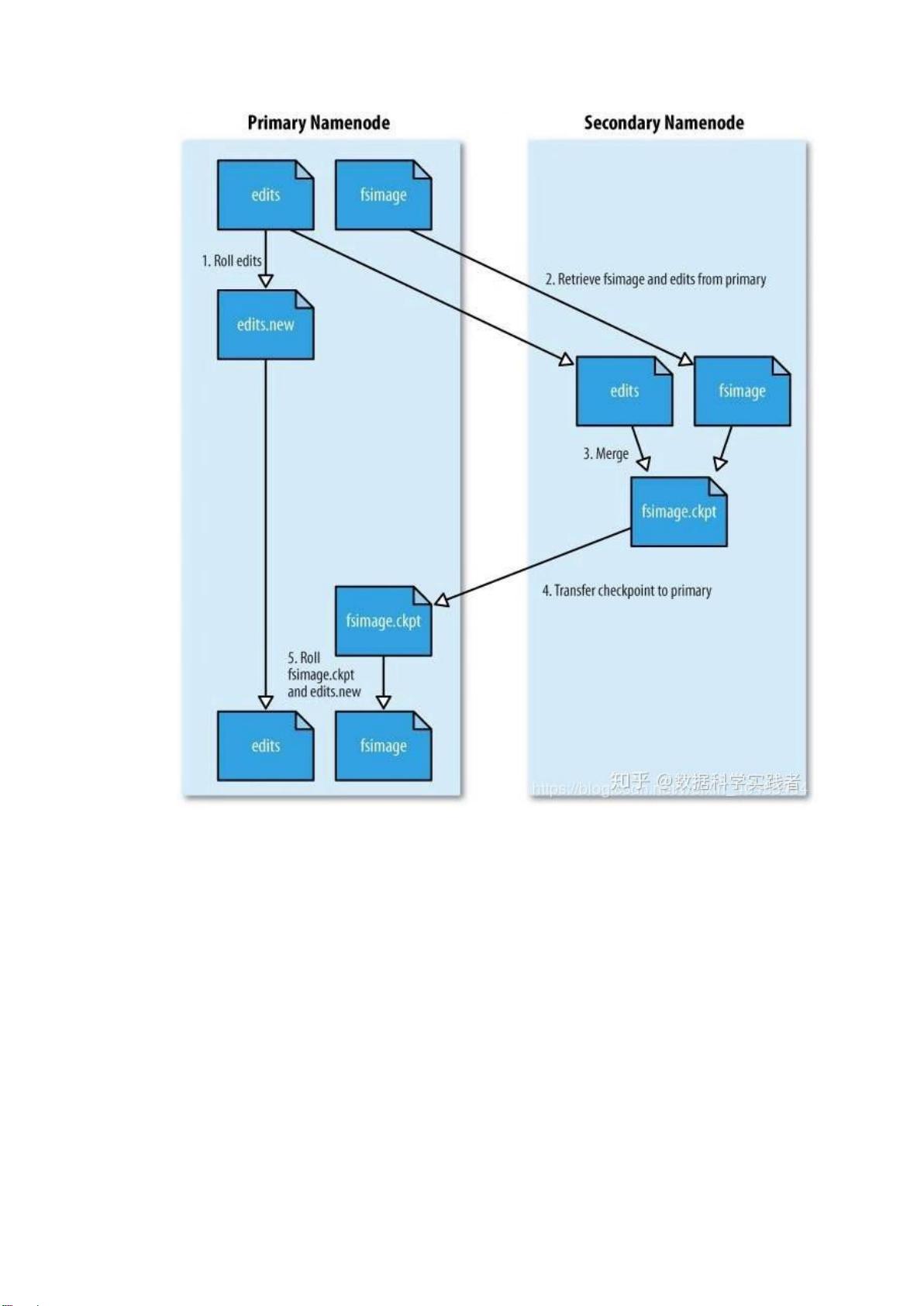
⚫ SecondaryNameNode 辅助名称节点端口号:50090
⚫ dfs.datanode.address:50010
⚫ fs.defaultFS:8020 或者 9000
⚫ yarn.resourcemanager.webapp.address:8088
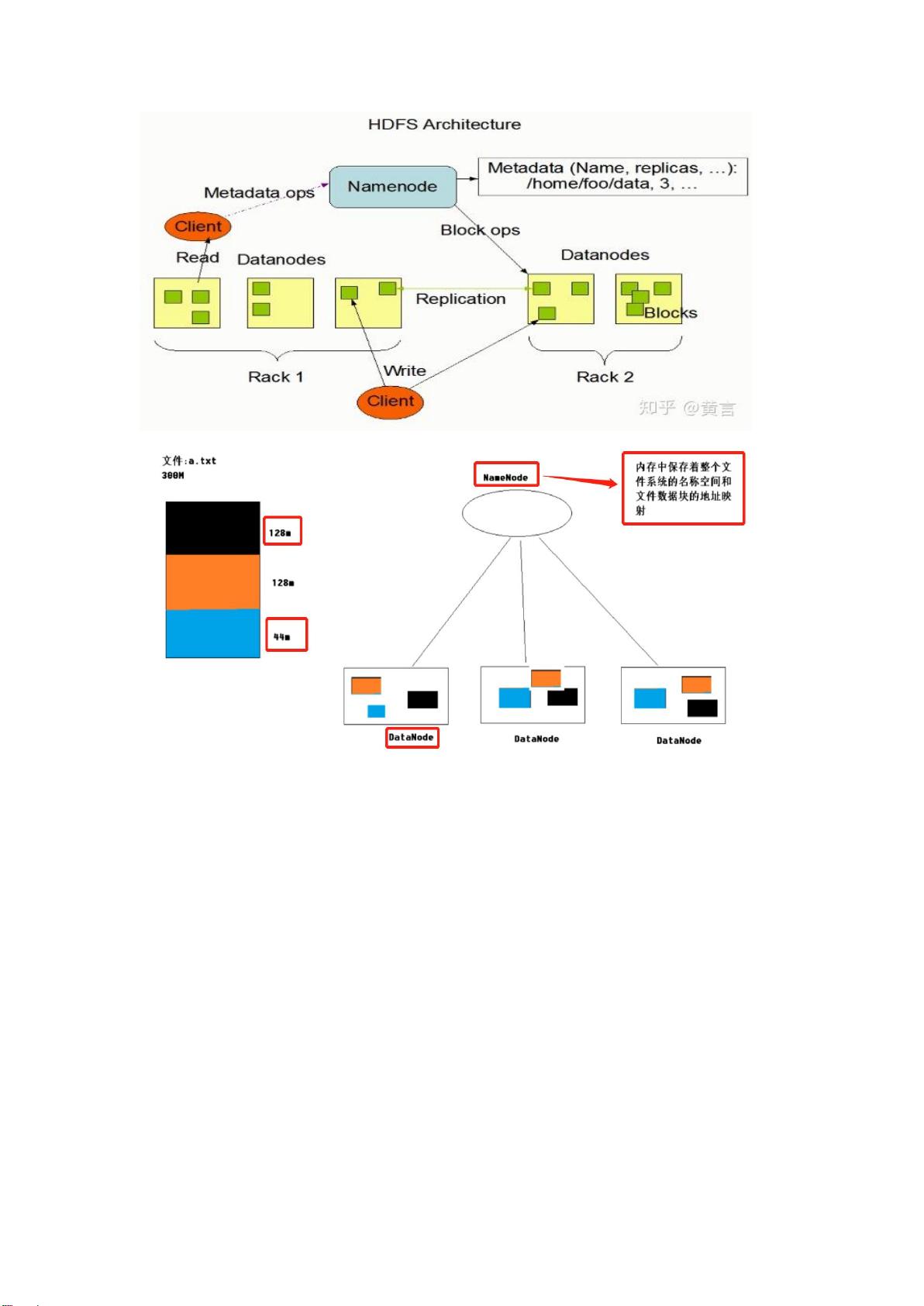
1.1.2. Hdfs 的架构以及组件功能
HDFS
的架构图如下所示:


剩余139页未读,继续阅读
资源评论


FlyWIHTSKY
- 粉丝: 58
- 资源: 12









最新资源
- 基于matlab实现串口发送接收数据 可配置端口,波特率等 发送可选择ASCII方式或HEX方式
- matlab基于BP神经网络手写字母识别(单一).zip代码9
- 基于matlab实现编写的串口调试工具,数据接收部分采用中断方式,保证了实时的数据显示
- 基于matlab实现39节点电力系统合闸角调控过程中的机组和负荷的灵敏度计算.rar
- HBase数据库性能调优
- 原生微信小程序源码 - -首字母排序选择
- 基于QT+C++开发的保卫萝卜塔防游戏+源码(毕业设计&课程设计&项目开发)
- newapp.apk
- 项目申报管理系统论文Java项目
- 8数码、α-β搜索的博弈树算法编写一字棋游戏、Fisher线性分类器、感知器算法、SVM 分类器、卷积神经网络 CNN 框架
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


