



CS 229
机器学习
(个人笔记)

目录
(1)线性回归、logistic回归和一般回归 1
(2)判别模型、生成模型与朴素贝叶斯方法 10
(3)支持向量机SVM(上) 20
(4)支持向量机SVM(下) 32
(5)规则化和模型选择 45
(6)K-means聚类算法 50
(7)混合高斯模型和EM算法 53
(8)EM算法 55
(9)在线学习 62
(10)主成分分析 65
(11)独立成分分析 80
(12)线性判别分析 91
(13)因子分析 103
(14)增强学习 114

(15)典型关联分析 120
(16)偏最小二乘法回归 129
这里面的内容是我在2011年上半年学习斯坦福大学《机器学习》课
程的个人学习笔记,内容主要来自Andrew Ng教授的讲义和学习视
频。
另外也包含来自其他论文和其他学校讲义的一些内容。每章内容主
要按照个人学习时的思路总结得到。
由于是个人笔记,里面表述错误、公式错误、理解错误、笔误都会
存在。更重要的是我是初学者,千万不要认为里面的思路都正确。
如果有疑问的地方,请第一时间参考Andrew Ng教授的讲义原文和
视频,再有疑问的地方可以找一些大牛问问。
博客上很多网友提出的问题,我难以回答,因为我水平确实有限,
更深层次的内容最好找相关大牛咨询和相关论文研读。
如果有网友想在我这个版本基础上再添加自己的笔记,可以发送
Email给我,我提供原始的word docx版本。
另,本人目前在科苑软件所读研,马上三年了,方向是分布式计
算,主要偏大数据分布式处理,平时主要玩Hadoop、Pig、Hive、
Mahout、NoSQL啥的,
关注系统方面和数据库方面的会议。希望大家多多交流,以后会往
博客上放这些内容,机器学习会放的少了。
Anyway,祝大家学习进步、事业成功!
对回归方法的认识
JerryLead
csxulijie@gmail.com
2011 年 2 月 27 日
1 摘要
本报告是在学习斯坦福大学机器学习课程前四节加上配套的讲义后的总结与认识。前四
节主要讲述了回归问题,属于有监督学习中的一种方法。该方法的核心思想是从离散的统计
数据中得到数学模型,然后将该数学模型用于预测或者分类。该方法处理的数据可以是多维
的。
讲义最初介绍了一个基本问题,然后引出了线性回归的解决方法,然后针对误差问题做
了概率解释。
2 问题引入
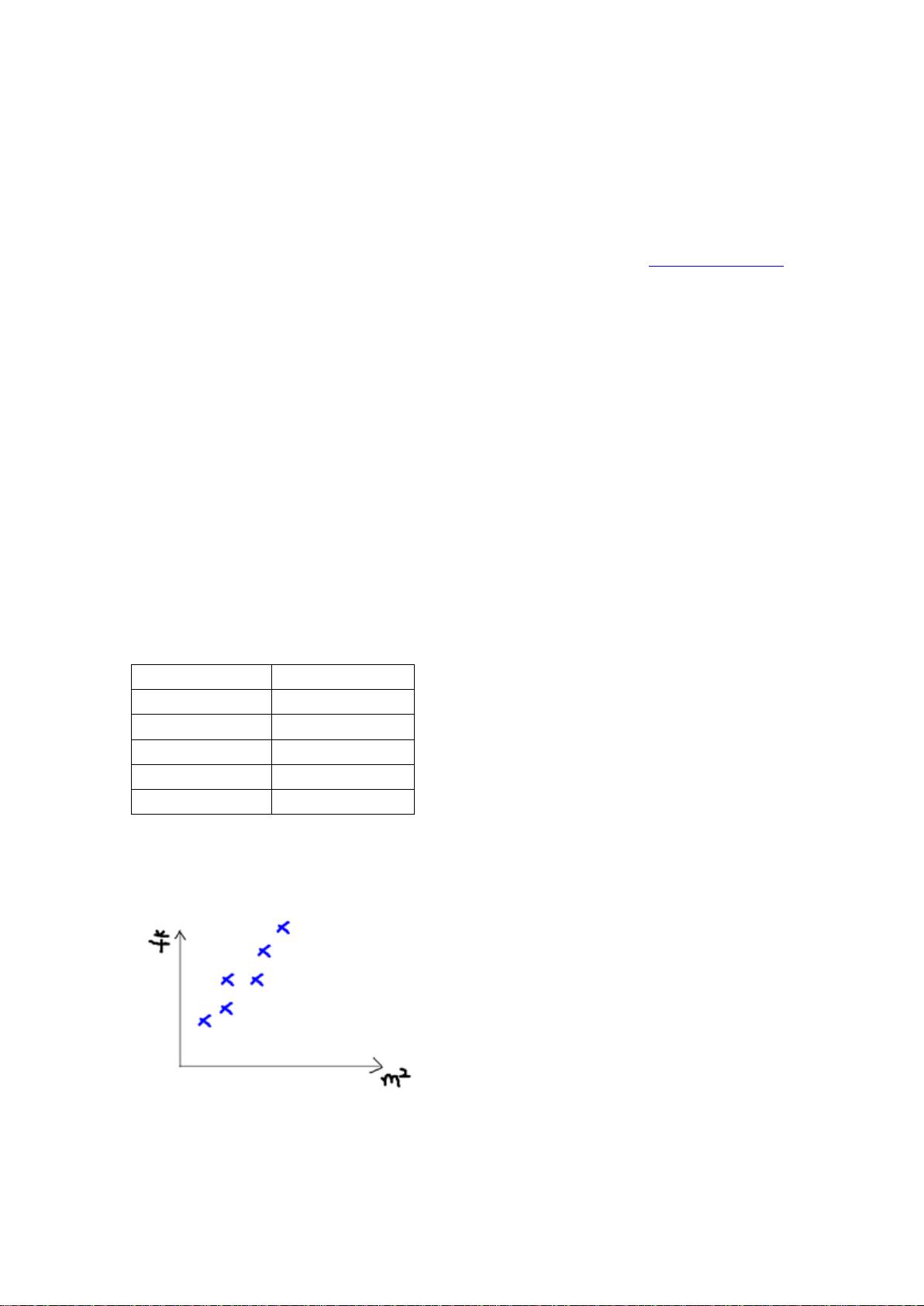
假设有一个房屋销售的数据如下:
面积(m^2)
销售价钱(万元)
123
250
150
320
87
160
102
220
…
…
这个表类似于北京 5 环左右的房屋价钱,我们可以做出一个图,x 轴是房屋的面积。y 轴是
房屋的售价,如下:
如果来了一个新的面积,假设在销售价钱的记录中没有的,我们怎么办呢?
我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入过来,我们可以在
将曲线上这个点对应的值返回。如果用一条直线去拟合,可能是下面的样子:
1
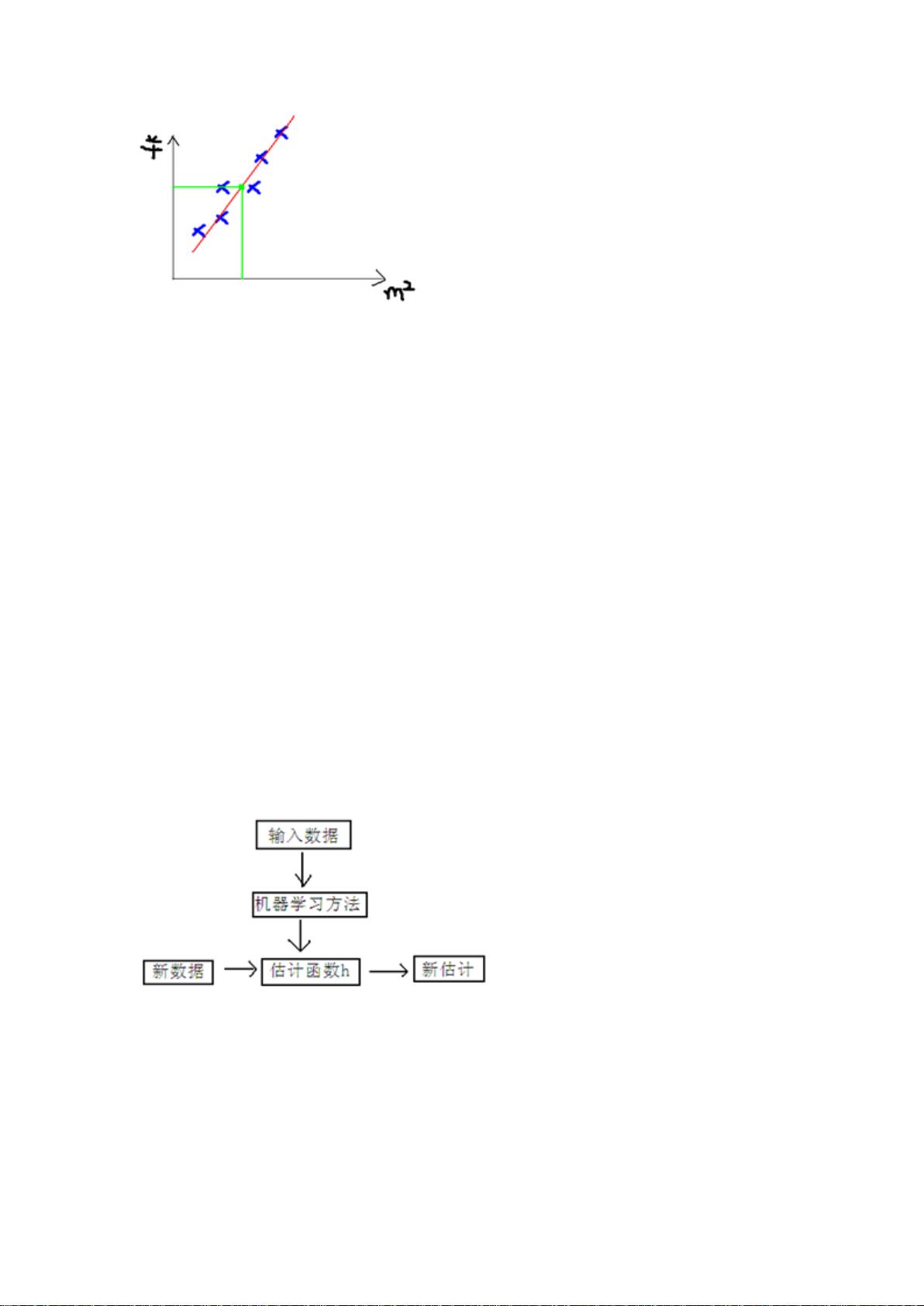
绿色的点就是我们想要预测的点。
首先给出一些概念和常用的符号。
房屋销售记录表:训练集(training set)或者训练数据(training data), 是我们流程中的输入数据,
一般称为 x
房屋销售价钱:输出数据,一般称为 y
拟合的函数(或者称为假设或者模型):一般写做 y = h(x)
训练数据的条目数(#training set),:一条训练数据是由一对输入数据和输出数据组成的输入
数据的维度 n (特征的个数,#features)
这个例子的特征是两维的,结果是一维的。然而回归方法能够解决特征多维,结果是一维多
离散值或一维连续值的问题。
3 学习过程
下面是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过
程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为
构建一个模型。就如同上面的线性回归函数。
4 线性回归
线性回归假设特征和结果满足线性关系。其实线性关系的表达能力非常强大,每个特征
对结果的影响强弱可以有前面的参数体现,而且每个特征变量可以首先映射到一个函数,然
后再参与线性计算。这样就可以表达特征与结果之间的非线性关系。
2













评论0