



SVM
分类算法
一、数据源说明
1、 数据源说远和理解:
采用的实验数据源为第 6 组:The Insurance Company Benchmark (COIL 2000)
TICDATA2000.txt: 这个数据集用来训练和检验预测模型,并且建立了一个 5822 个客
户的记录的描述。每个记录由 86 个属性组成,包含社会人口数据(属性 1-43)和产品
的所有关系(属性 44-86 )。社会人口数据是由派生邮政编码派生而来的,生活在具有
相同邮政编码地区的所有客户都具有相同的社会人口属性。第 86 个属性:“大篷车:
家庭移动政策” ,是我们的目标变量。共有 5822 条记录,根据要求,全部用来训练。
TICEVAL2000.txt: 这个数据集是需要预测( 4000 个客户记录)的数据集。它和
TICDATA2000.txt 它具有相同的格式,只是没有最后一列的目标记录。我们只希望返回
预测目标的列表集,所有数据集都用制表符进行分隔。共有 4003(自己加了三条数据),
根据要求,用来做预测。
TICTGTS2000.txt:最终的目标评估数据。这是一个实际情况下的目标数据,将与我们
预测的结果进行校验。我们的预测结果将放在 result.txt 文件中。
数据集理解:本实验任务可以理解为分类问题,即分为 2 类,也就是数据源的第 86 列,
可以分为 0、1 两类。我们首先需要对 TICDATA2000.txt 进行训练,生成 model,再根
据 model 进行预测。
2、 数据清理
代码中需要对数据集进行缩放的目的在于:
A、避免一些特征值范围过大而另一些特征值范围过小;
B、避免在训练时为了计算核函数而计算内积的时候引起数值计算的困难。因此,
通常将数据缩放到 [ -1,1] 或者是 [0,1] 之间。
二、数据挖掘的算法说明
1、svm 算法说明
LIBSVM 软件包是台湾大学林智仁(Chih-Jen Lin)博士等用 C++实现的
SVM 库,并且拥有 matlab,perl 等工具箱或者代码,移植和使用都比较方
便.它可以解决分类问题(包括 C-SVC、n-SVC)、回归问题(包括 e-SVR、
n-SVR)以及分布估计(one-class-SVM )等问题,提供了线性、多项式、
径向基和 S 形函数四种常用的核函数供选择,可以有效地解决多类问题、
交叉验证选择参数、对不平衡样本加权、多类问题的概率估计等。
2、实现过程
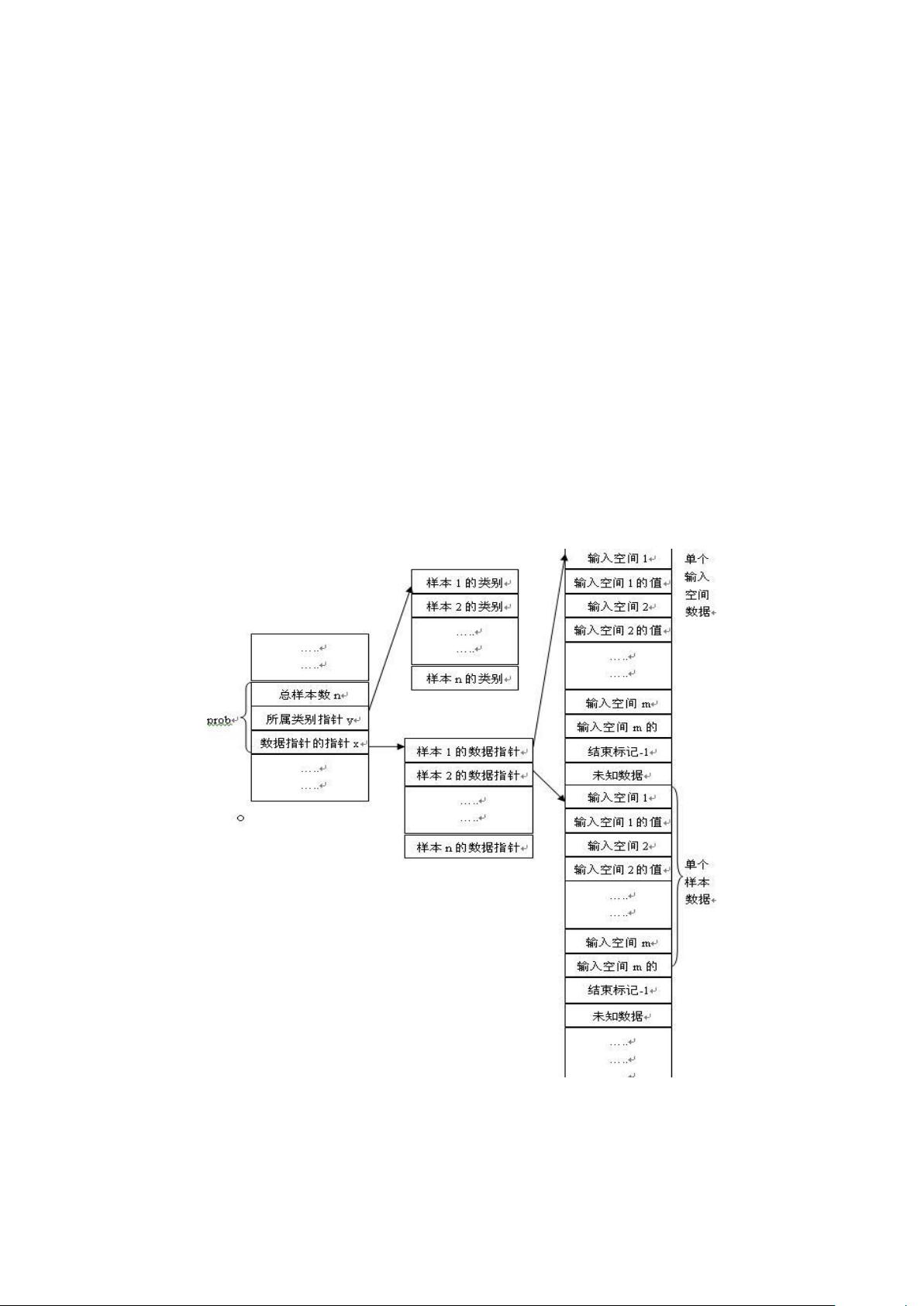














评论0