

Published as a conference paper at ICLR 2020
ONCE-FOR-ALL: TRAIN ONE NETWORK AND SPE-
CIALIZE IT FOR EFFICIENT DEPLOYMENT
Han Cai
1
, Chuang Gan
2
, Tianzhe Wang
1
, Zhekai Zhang
1
, Song Han
1
1
Massachusetts Institute of Technology,
2
MIT-IBM Watson AI Lab
{hancai, chuangg, songhan}@mit.edu
ABSTRACT
We address the challenging problem of efficient inference across many devices
and resource constraints, especially on edge devices. Conventional approaches
either manually design or use neural architecture search (NAS) to find a specialized
neural network and train it from scratch for each case, which is computationally
prohibitive (causing
CO
2
emission as much as 5 cars’ lifetime Strubell et al. (2019))
thus unscalable. In this work, we propose to train a once-for-all (OFA) network that
supports diverse architectural settings by decoupling training and search, to reduce
the cost. We can quickly get a specialized sub-network by selecting from the OFA
network without additional training. To efficiently train OFA networks, we also
propose a novel progressive shrinking algorithm, a generalized pruning method
that reduces the model size across many more dimensions than pruning (depth,
width, kernel size, and resolution). It can obtain a surprisingly large number of sub-
networks (
> 10
19
) that can fit different hardware platforms and latency constraints
while maintaining the same level of accuracy as training independently. On diverse
edge devices, OFA consistently outperforms state-of-the-art (SOTA) NAS methods
(up to 4.0% ImageNet top1 accuracy improvement over MobileNetV3, or same
accuracy but 1.5
×
faster than MobileNetV3, 2.6
×
faster than EfficientNet w.r.t
measured latency) while reducing many orders of magnitude GPU hours and
CO
2
emission. In particular, OFA achieves a new SOTA 80.0% ImageNet top-1 accuracy
under the mobile setting (
<
600M MACs). OFA is the winning solution for the
3rd Low Power Computer Vision Challenge (LPCVC), DSP classification track
and the 4th LPCVC, both classification track and detection track. Code and 50
pre-trained models (for many devices & many latency constraints) are released at
https://github.com/mit-han-lab/once-for-all.
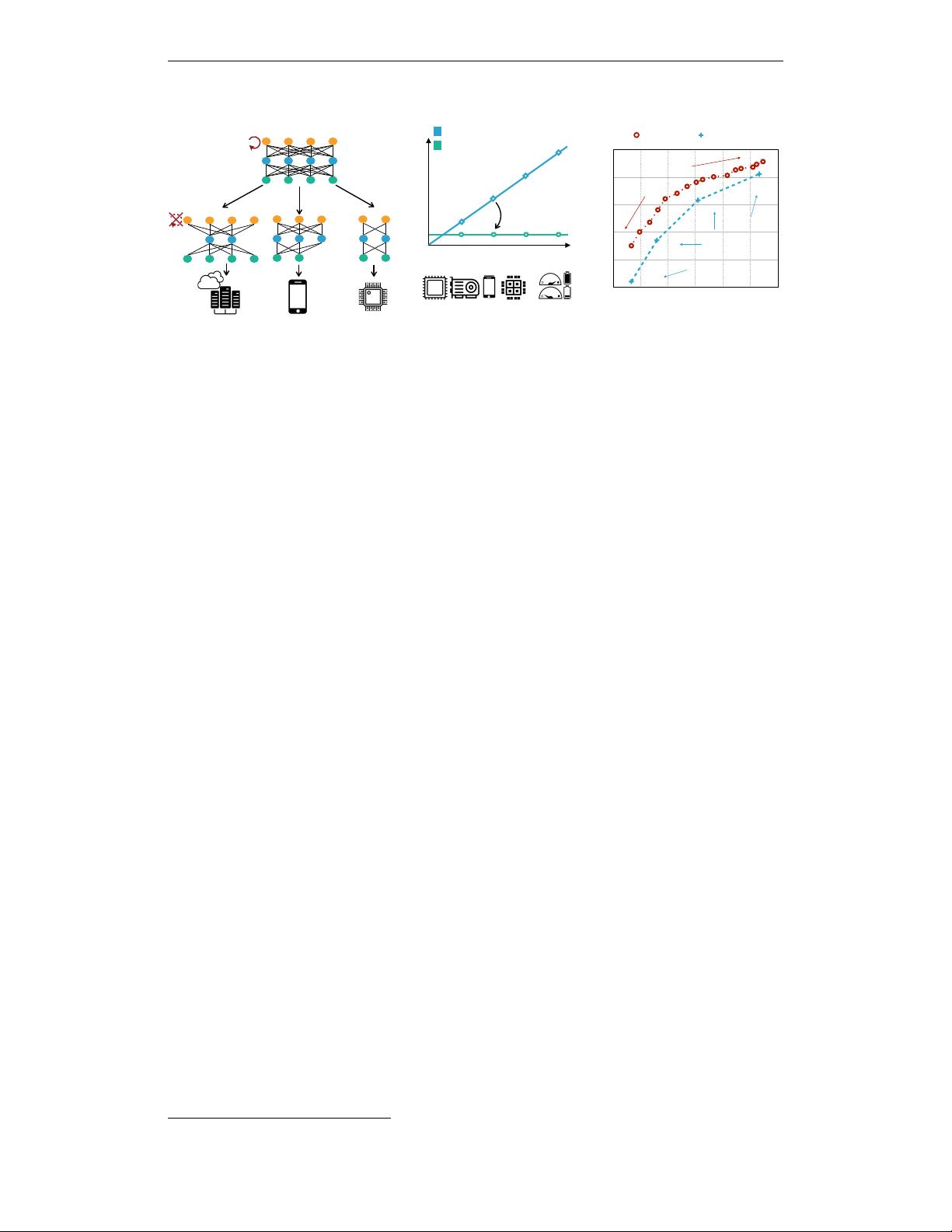
1 INTRODUCTION
Deep Neural Networks (DNNs) deliver state-of-the-art accuracy in many machine learning applica-
tions. However, the explosive growth in model size and computation cost gives rise to new challenges
on how to efficiently deploy these deep learning models on diverse hardware platforms, since they
have to meet different hardware efficiency constraints (e.g., latency, energy). For instance, one mobile
application on App Store has to support a diverse range of hardware devices, from a high-end Sam-
sung Note10 with a dedicated neural network accelerator to a 5-year-old Samsung S6 with a much
slower processor. With different hardware resources (e.g., on-chip memory size, #arithmetic units),
the optimal neural network architecture varies significantly. Even running on the same hardware,
under different battery conditions or workloads, the best model architecture also differs a lot.
Given different hardware platforms and efficiency constraints (defined as deployment scenarios),
researchers either design compact models specialized for mobile (Howard et al., 2017; Sandler et al.,
2018; Zhang et al., 2018) or accelerate the existing models by compression (Han et al., 2016; He
et al., 2018) for efficient deployment. However, designing specialized DNNs for every scenario
is engineer-expensive and computationally expensive, either with human-based methods or NAS.
Since such methods need to repeat the network design process and retrain the designed network
from scratch for each case. Their total cost grows linearly as the number of deployment scenarios
increases, which will result in excessive energy consumption and
CO
2
emission (Strubell et al., 2019).
It makes them unable to handle the vast amount of hardware devices (23.14 billion IoT devices till
1

剩余14页未读,继续阅读
资源评论


潜夙
- 粉丝: 0
- 资源: 40









最新资源
- 基于mosquitto的android mqtt客户端详细文档+全部资料.zip
- 基于mqtt的消息推送系统,单点推送,分组推送详细文档+全部资料.zip
- 基于MQTT的聊天系统演示详细文档+全部资料.zip
- 基于mqtt的遥控器,在app上点击按钮,将码(空调码,电视码,风扇码)发送到mqqt,mqtt通过WiFi发给esp8266,esp8266解析转为红外,发出
- 基于Mqtt实现的简单推送服务的服务端详细文档+全部资料.zip
- 基于mqtt实现的即时通讯IM服务详细文档+全部资料.zip
- 基于mqtt开发sdk源码详细文档+全部资料.zip
- 基于MQTT实现的局域网通讯,模仿微信详细文档+全部资料.zip
- 最简单优雅的SQL操作类库
- 基于MQTT物联网用户终端程序详细文档+全部资料.zip
- 基于MQTT协议,物联网云平台的智慧路灯管理系统,在PC机上进行项目软件的Web开发,采集端的数据采用MQTT.fx进行模拟,数据通过MQTT协议进行传输到服务
- 基于MQTT协议的一个即时通讯安卓APP详细文档+全部资料.zip
- 基于MQTT协议的底层通讯SDK详细文档+全部资料.zip
- 基于MQTT协议的物联网健康监测系统详细文档+全部资料.zip
- 基于netty, spring boot, redis等开源项目实现的物联网框架, 支持tcp, udp底层协议和http, mqtt, modbus等上层协议
- 基于MQTT协议实现消息的即时推送Android开发详细文档+全部资料.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


