**云计算与大数据应用开发——网络爬虫**
网络爬虫,又称网页蜘蛛或网络机器人,是自动从互联网上抓取和提取网页数据的程序或脚本。它的存在是为了解决从海量网页中获取特定信息的需求,无论是搜索引擎用于索引网页,还是个人或企业对特定数据的搜集。网络爬虫遵循一定的规则,它在网络中遍历,遇到可访问的数据就进行抓取。这些数据主要指公开的网页信息,不包括网站后台或用户隐私信息。
**初识爬虫**
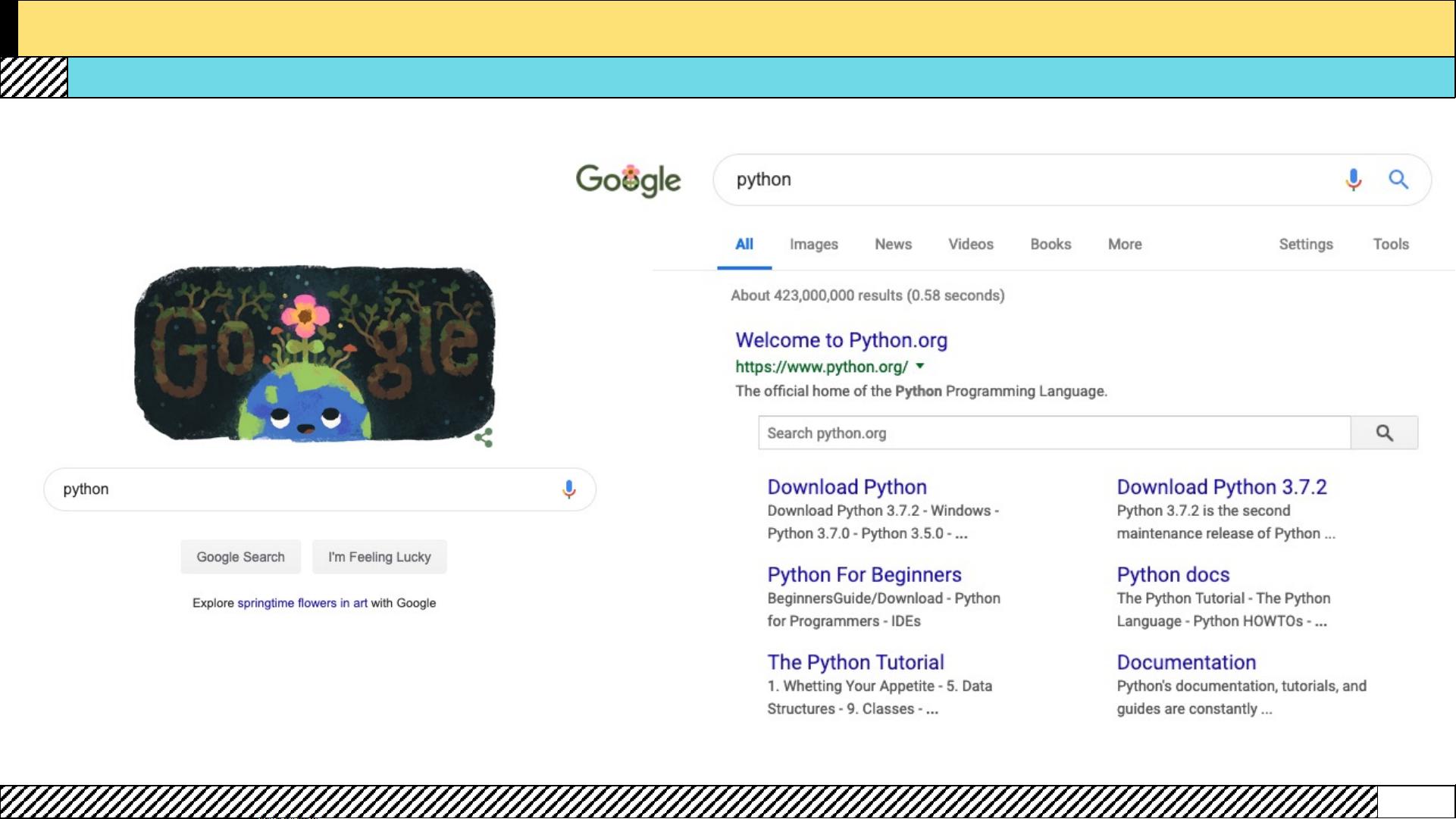
搜索引擎利用网络爬虫技术,不断抓取互联网上的网页,将其保存在本地并进行分析和索引,从而为用户提供信息检索服务。网络爬虫的产生背景主要是为了满足数据获取的需求,随着互联网的发展,爬虫技术逐渐成熟,成为了一门重要的技术领域。
**爬虫的分类**
根据使用场景,爬虫可分为两类:通用爬虫和聚焦爬虫。通用爬虫,也叫全网爬虫,旨在建立互联网内容的镜像备份;聚焦爬虫则是有选择地爬行与预定义主题相关的页面。按爬取形式,又分为累积式爬虫和增量式爬虫,前者从某一时间点开始抓取所有网页,后者则针对已有网页集合进行更新和抓取。此外,按数据存在方式,还区分了表层爬虫和深层爬虫,表层爬虫抓取的是可通过超链接到达的静态网页,而深层爬虫则针对隐藏在搜索表单后的动态页面。
**爬虫的实现**
实现一个简单的爬虫通常涉及以下几个步骤:使用HTTP库(如Python的requests或JavaScript的axios)向目标URL发送请求,获取HTML源代码;然后,使用正则表达式或其他解析库(如Python的BeautifulSoup或JavaScript的DOM解析)对HTML源代码进行分析,提取所需信息。例如,Python中可以使用requests库发送GET请求,获取HTML内容,并使用正则表达式进行匹配;JavaScript中可以使用axios库发送请求,再利用正则表达式解析响应数据。
**总结**
网络爬虫作为获取和处理互联网数据的重要工具,广泛应用于搜索引擎优化、市场分析、舆情监测等领域。理解爬虫的工作原理和实现方法,有助于我们有效地抓取和利用网络上的公开信息,同时也需注意遵守相关法律法规,尊重网站的Robots协议,避免对服务器造成过度负荷。在实际应用中,选择合适的爬虫类型和实现策略,结合数据分析技术,可以为云计算与大数据应用开发带来更大的价值。