
基于决策树
ID3
算法模式识别系统的设计与实现
1
.
1
研究内容
(1)工作的主要描述
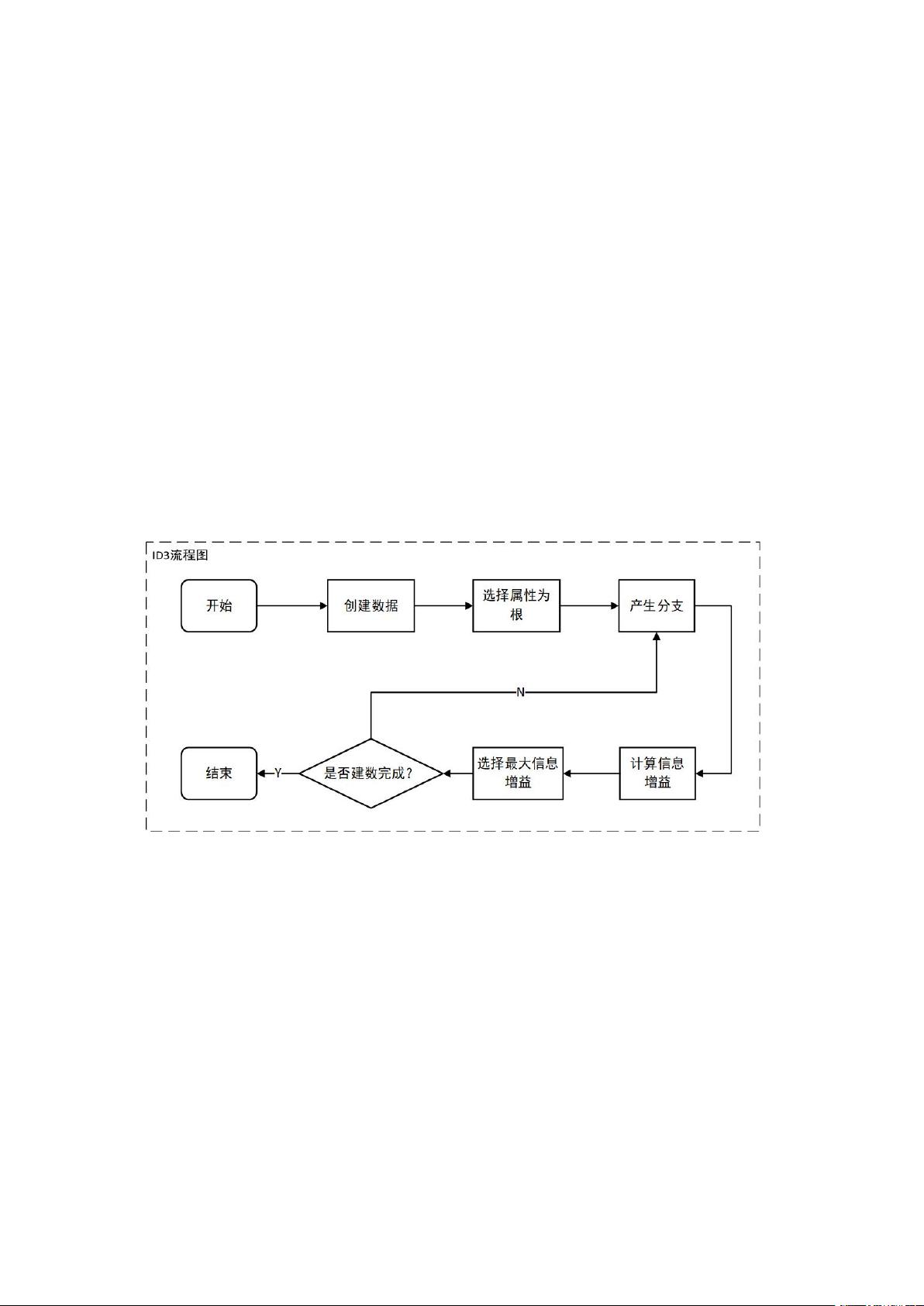
本实验采用决策树中 ID3 算法对数据进行分类,ID3 算法的核心实在决策
树各个节点上应用信息增益准则选择特征,递归地构建决策树。从根结点开始,
对节点计算所有可能特征的信息增益,选择信息增益最大的特征作为结点的特
征,由该特征的不同取值构建子结点;再对子结点递归调用上述方法,构建决策
树;知道所有特征的信息增益均很小或没有特征可以选择为止。最后得到一个决
策树。
(2)系统流程图
1.2 题目研究的工作基础或实验条件
(1)硬件环境
HP 笔记本电脑
运行内存:8GB
CPU:Intel Core i5 8th Gen
(2)软件环境
语言:python
软件:pycharm 3.9


剩余13页未读,继续阅读
资源评论













