

基于贝叶斯垃圾邮件判别模式识别系统的设计与实现
1.1 题目的主要研究内容
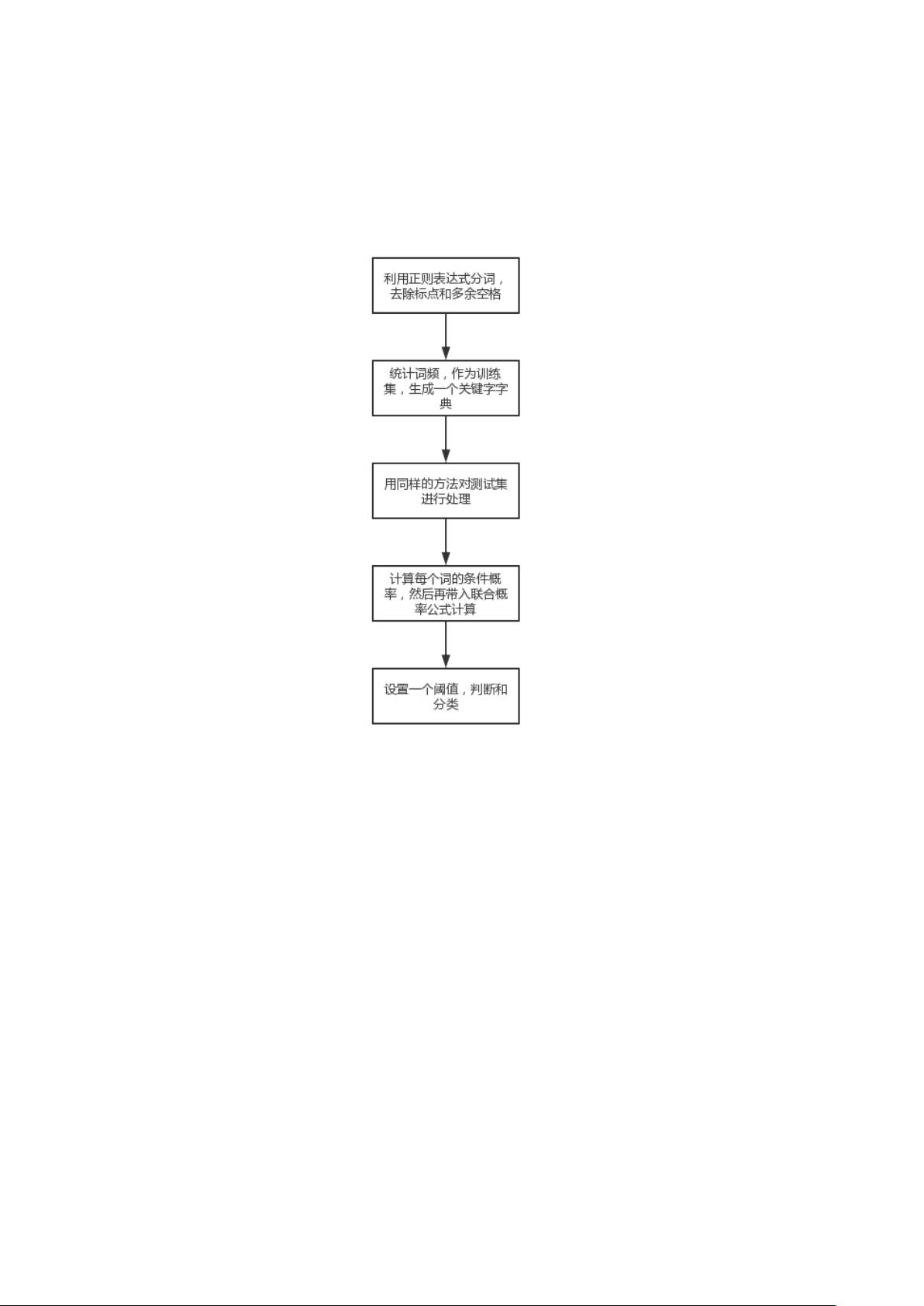
(1)工作的主要描述
假设邮件的内容中包含的词汇为 Wi,垃圾邮件 Spam,正常邮件 ham。判断
一份邮件,内容包含的词汇为 Wi,判断该邮件是否是垃圾邮件,即计算 P
(S|Wi)这个条件概率。
定义:
P(Y=S): 垃圾邮件在训练数据集中的概率,或者实际调查的垃圾邮件出现
的概率(即先验概率);
P(Y=H): 正常邮件在训练数据集中的概率,或者实际调查的正常邮件的分
布;
P ( Wi∣Y=S): 已知是垃圾邮件时,出现单词 Wi 的概率;包含单词的 Wi
的垃圾邮件个数/垃圾邮件总数。
P ( Wi∣Y=H): 正常邮件中,词汇 Wi 出现的概率;
P ( S∣W i ): 出现单词 Wi 的邮件被判定为垃圾邮件的概率;
当拿到一堆邮件并且已知哪些是垃圾邮件后,P(S)和 P(H)可以直接得出。
对于邮件中包含的所有单词,统计每个单词出现在垃圾邮件中的次数,出
现在正常邮件的次数,那么 P ( W i∣Y = S )和 P ( W i∣Y = H )也就有了,要求
的是 P ( S∣W i )
根据贝叶斯定理:
就得到了判断一个邮件是垃圾邮件的概率。
我们分别计算出 P(H|W)和 P(S|W),比较它们的大小,就能判断是垃圾邮件
还是正常邮件,由于 P(H|W)和 P(H|S)的分母是相同的,我们只需要计算和比较
分子即可。
)()()()(
)()(
)(
HPHWPSPSWP
SPSWP
WSP
丨丨
丨
丨
�
�
�
剩余6页未读,继续阅读
资源评论


李逍遥敲代码
- 粉丝: 2996
- 资源: 277









最新资源
- 自定义参照引用后保存显示主键或显示为空问题处理
- 我国1950-2023年外汇及黄金储备汇总+趋势变化图
- YOLOX,YOLOV5,YOLOV8,YOLOV9 针对 OpenVINO 的 C++ 推理,支持 float32、float16 和 int8 .zip
- 设置NCC单据参照字段多选(参照多选)
- 已安装xcb、X11库的交叉编译器(x86-64-aarch64-linux-gnu)
- 包含约100万条由BELLE项目生成的中文指令数据
- BIP集成NC65预算
- 包含约50万条由BELLE项目生成的中文指令数据
- 完整的交叉编译好支持xcb的qt库(qt5.15.2、arm64、xcb、no-opengl)
- 包含约40万条由BELLE项目生成的个性化角色对话数据,包含角色介绍
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


