




Deep Learning for Natural Language
Processing
The Transformer model
Richard Johansson
richard.johansson@gu.se
-20pt
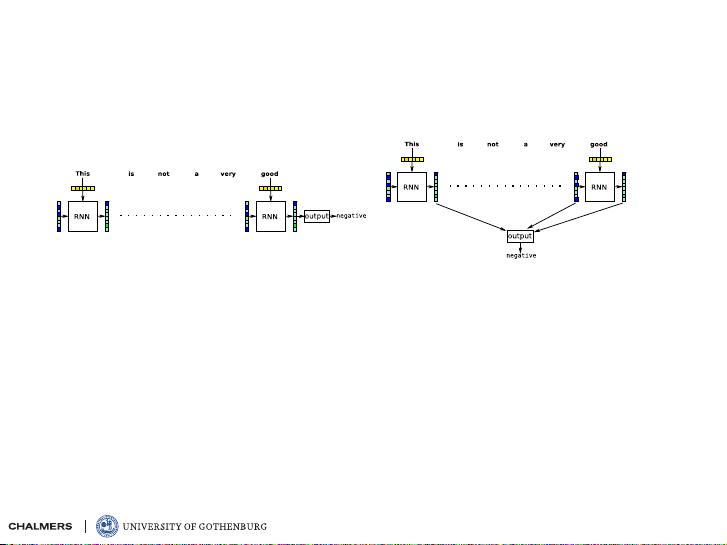
drawbacks of recurrent models
I
even with GRUs and LSTMs, it is difficult for RNNs to
preserve information over long distances
I
we introduced attention as a way to deal with this problem
I
can we skip the RNN and just use attention?
-20pt
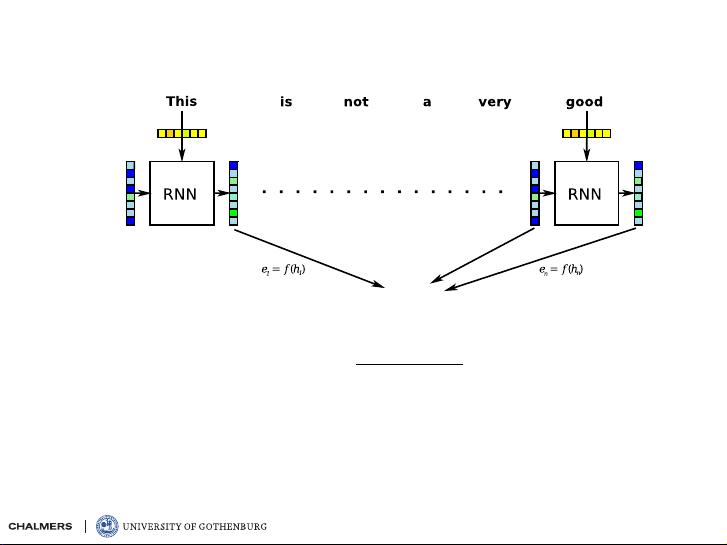
attention models: recap
I
first, compute an “energy” e
i
for each state h
i
I
for the attention weights, we apply the softmax:
α
i
=
exp e
i
P
n
j=1
exp e
j
I
finally, the “summary” is computed as a weighted sum
s =
n
X
i=1
α
i
h
i

-20pt
the Transformer
I
the Transformer (Vaswani et al., 2017) is an
architecture that uses attention for information flow:
“Attention is all you need”
I
it was originally designed for machine translation
and has two parts:
I
an encoder that “summarizes” an input sentence
I
a decoder (a conditional LM) that generates an
output, based on the input
I
let’s consider the encoder

-20pt
illustration of a Transformer block













