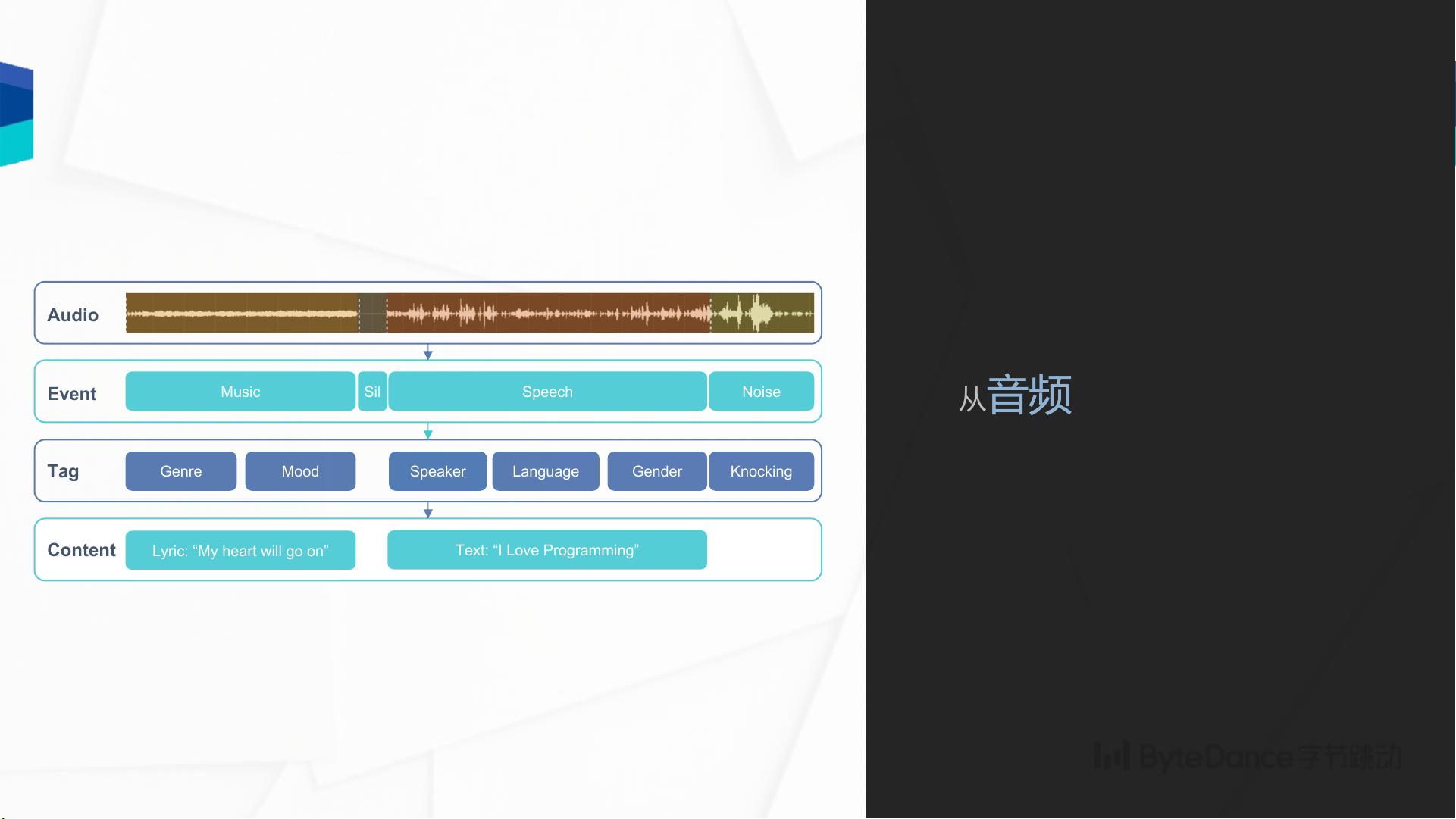
一、基于GPU的音频理解和合成技术概述 基于GPU的大规模音频理解和合成解决方案由字节跳动人工智能实验室语音团队提出。该方案利用GPU的高性能计算能力,实现对大规模音频数据的高效处理,涵盖音频合成和音频理解两大核心技术领域,并结合训练平台和推理框架,形成了完整的智能语音技术方案,旨在赋能全球内容创建和消费。 二、音频理解关键技术 音频理解关键技术包括事件检测、语音识别、语种识别、声纹识别、关键词检测等多个方面。通过这些技术,能够从音频信号中提取出有关音频事件、内容、说话人等多维度信息。 1. 事件检测(ED):从音频流中检测出特定的声音事件及其对应的时间范围。 2. 语种识别(LIDS):确定音频中语音的语种属性。 3. 声纹识别(IDKWS):识别音频中的说话人身份。 4. 关键词检测(KW):在音频中找出预设关键词及其对应位置。 5. 语音内容转写为文字(ASR):将语音信号转换为可读的文字。 音频理解的应用场景广泛,例如在视频字幕生成中,通过事件检测、语音识别和语义理解技术,为视频自动配上字幕,大大缩短了视频制作周期,提高了效率。 三、音频合成关键技术 音频合成技术则聚焦于如何根据文本、声音材料等信息生成具有不同声调、音色和风格的音频内容。 1. 文本到语音(TTS):根据文本内容生成语音。 2. 歌唱合成(Singing):基于乐谱和歌词合成歌唱音频。 3. 音色转换(Voice Conversion):将任意说话人的声音转为指定目标音色。 音频合成的应用场景同样多样,特别是在视频配音、有声新闻和有声小说生产中,音频合成技术通过一键配音、快速生产音频内容,显著提升了内容的制作效率和生态多样性。 四、训练平台和推理框架 训练平台负责对音频理解和音频合成技术进行大规模训练,以便提取和学习音频数据中的有效信息。推理框架则通过已经训练好的模型快速地对新的音频数据进行处理,转换为具体的音频输出。这一系列的解决方案不仅提高了效率,也保障了处理质量。 五、音频理解和合成在实际应用中的效益 1. 提升内容创建效率:通过自动化字幕添加和音频配音,创作者能更快捷地将作品呈现给观众,降低创作门槛。 2. 丰富内容生态:自动化技术能够快速生产大量的音频内容,丰富媒体内容种类,满足不同用户需求。 3. 提高用户观看体验:自动字幕让观看内容变得更友好,内容消费者可以享受到更优质、更个性化的内容体验。 六、技术展望和未来方向 字节跳动人工智能实验室语音团队的愿景是建设业界顶尖的智能语音技术方案,该方案的不断优化和发展将为智能语音技术带来新的突破和应用场景,不仅限于字幕生成和音频配音,更可向教育、客服、智能助手等多个领域拓展。 基于GPU的大规模音频理解和合成解决方案是智能语音技术发展的重要里程碑,它极大地提高了语音数据处理的效率和质量,为全球内容创作者和消费者提供了有力的技术支持和创新服务。随着技术的不断进步和应用领域的不断拓展,未来的智能语音技术将更加贴近人们的日常生活,为人们提供更加丰富和便捷的语音交互体验。
剩余38页未读,继续阅读
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~