

书书书
收稿日期:20181110;修回日期:20190117 基金项目:国家自然科学基金资助项目(51579204,51679180);武汉理工大学自主创新
研究基金资助项目(2016IVA064,2016YB029)
作者简介:邹雄(1982),男,博士研究生,主要研究方向为机器视觉(zx2000@whut.edu.cn);肖长诗(1974),教授,博士,主要研究方向为宽动
态成像;文元桥(1974),教授,博士,主要研究方向为大数据;元海文(1988),博士,主要研究方向为机器视觉.
基于特征点法和直接法 VSLAM 的研究
邹 雄
1
,肖长诗
1,2
,文元桥
1,2,3
,元海文
1
(1.武汉理工大学 航运学院,武汉 430063;2.内河航运技术湖北省重点实验室,武汉 430063;3.国家水运安全
工程技术研究中心,武汉 430063)
摘 要:基于视觉的同时定位和建图(VSLAM)分为前端和后端,前端包括视觉里程计和回环检测,后端包括后端
优化和建图。按照估计相机运动的不同方式,将
VSLAM分为特征点法和直接法,首先从这两个方面对前端进行综
述,阐述其中的关键技术和最新的研究进展,对比分析不同方法的优缺点;然后详细分析优化后端与滤波器后端的
区别,进一步对多个开源代码进行比较研究,分析它们的优劣势和适用场合;再讨论深度学习、语义地图和多机器
人在 VSLAM领域的研究进展,以及相关技术与 VSLAM的结合方式及前景;最后对 VSLAM的未来进行展望。
关键词:VSLAM;视觉里程计;特征点法;直接法;非线性优化
中图分类号:TP391.41 文献标志码:A 文章编号:10013695(2020)05001128111
doi:10.19734/j.issn.10013695.2018.11.0789
ResearchoffeaturebasedanddirectmethodsVSLAM
ZouXiong
1
,XiaoChangshi
1,2
,WenYuanqiao
1,2,3
,YuanHaiwen
1
(1.SchoolofNavigation,WuhanUniversityofTechnology,Wuhan430063,China;2.HubeiKeyLaboratoryofInlandShippingTechnology,
Wuhan430063,China;3.NationalEngineeringResearchCenterforWaterTransportSafety,Wuhan430063,China)
Abstract:VSLAMisdividedintofrontendandbackend.Thefrontendincludesvisualodometryandloopdetection,and
thebackendincludesbackendoptimizationandmapping.ThispaperdividedVSLAM intofeaturebasedmethodanddirect
methodaccordingtodifferentwaysofestimatingcameramotion.Firstly
,itsummarizedthefrontendfromthesetwoaspects,
elaboratedthekeytechnologiesandthelatestresearchprogress,comparedandanalyzedthedifferentmethods.Then,itana
lyzedthedifferencesbetweentheoptimizebackendandthefilterbackendindetail
,andcomparedtheadvantagesanddisad
vantagesofseveralopensourcecodesandtheirapplicableoccasions.Further
,itintroducedtheresearchprogressofdeep
learning,semanticmappingandmultirobotsinVSLAM,anddiscussedthecombinationofrelatedtechnologieswithVSLAM
anditsprospects.Finally
,itprospectedthefutureofVSLAM.
Keywords:VSLAM;VO;featurebasedmethod;directmethod;nonlinearoptimization
同时定 位 与 地 图 构 建 (simultaneouslocalizationandmap
ping,SLAM)
[1,2]
是机器人进入未知环境遇到的第一个问题,它
是指机器人搭载特定传感器,在没有环境先验信息的情况下,
在运动过程中对周围环境建模并同时估计自身的位姿
[3]
。如
果传感 器 主 要 为 相 机,那么 就 称 为 视 觉 SLAM(VSLAM)
[4]
。
SLAM技术已经研究和发展了三十多年,研究人员已经做了大
量工作,近十年来,随着计算机视觉的发展,VSLAM以其硬件
成本低廉、轻便、高精度等优势获得了学术界和工业界的青睐。
VSLAM是利用多视图几何理论
[5]
,根据相机拍摄的图像
信息对相机进行定位并同时构建周围环境地图。按照相机的
分类,有单目、双目、RGBD、鱼眼、全景等。为了方便,本文只考
虑普通相机。从 VSLAM的提出到目前为止,经过研究人员十
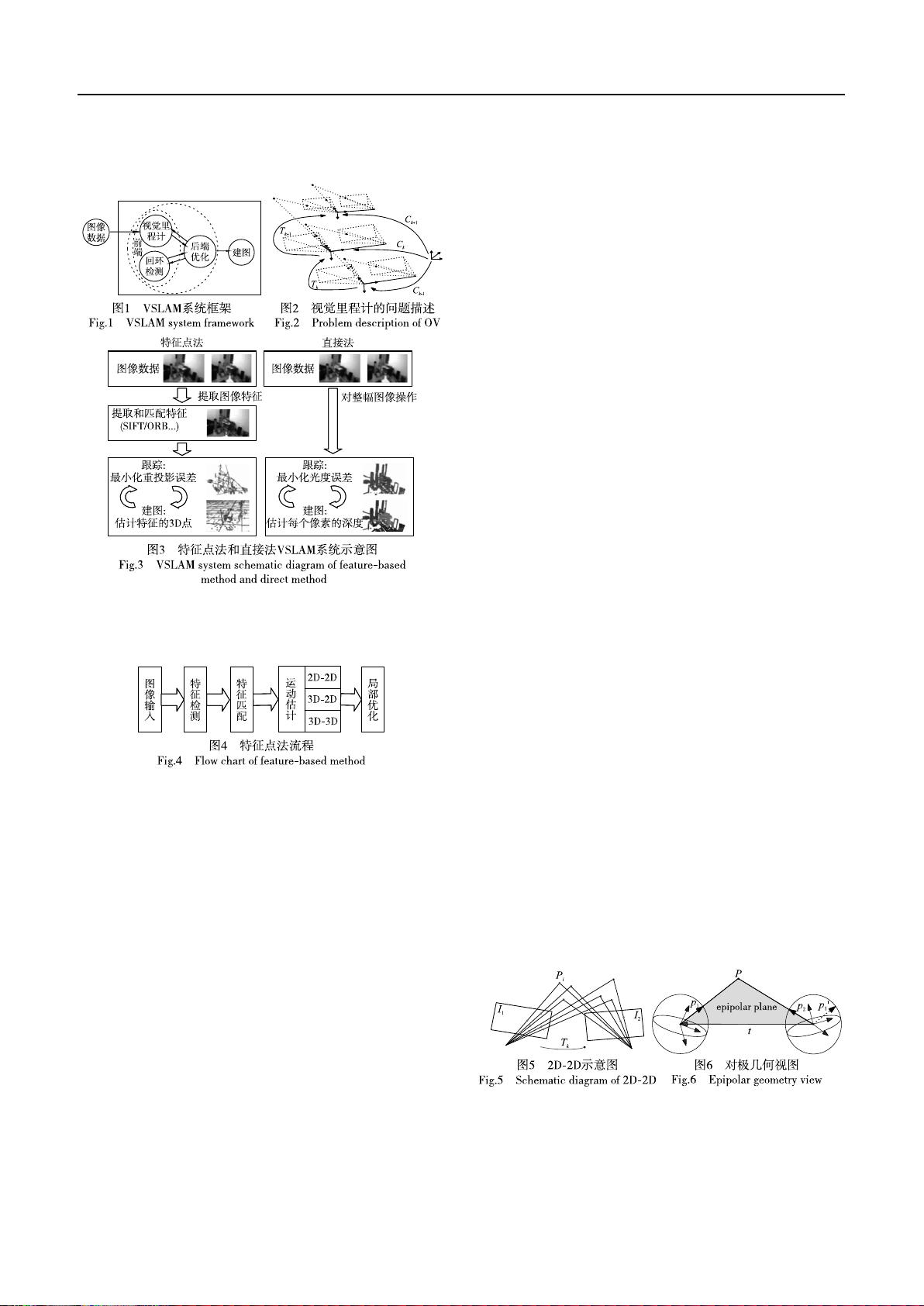
多年不懈努力,VSLAM框架已基本形成。如图 1所示,VSLAM
主要包括视觉里程计(visualodometry,VO)、后端优化、回环检
测、建图。其中 VO研究图像帧间变换关系完成实时的位姿跟
踪,对输入的图像进行处理,计算姿态变化,得到相机间的运动
关系。但是随着时间的累计,误差会累积,这是由于仅仅估计
两个图像间的运动造成的。后端主要是使用优化方法,减小整
个框架误差(包括相机位姿和空间地图点)。回环检测又称为
闭环检测,主要是利用图像间的相似性来判断是否到达过先前
的位置,以此来消除累计误差,得到全局一致性轨迹和地图。
建图是根据估计的轨迹建立与任务要求对应的地图。
现在比较通常的惯例是把
VSLAM分为前端和后端,前端
为视觉里程计和回环检测,相当于是对图像数据进行关联;后
端是对前端输出的结果进行优化,利用滤波或非线性优化理论
得到最优的位姿估计和全局一致性地图。
1 前端
11 视觉里程计
前端中的视觉里程计是通过采集的图像得到相机间的运
动估计,视觉里程计问题可由图 2进行描述(双目立体视觉里
程计)。视觉系统在运动过程中,在不同时刻获取了环境的图
像,而且相邻时刻的图像必须有足够的重叠区域,则视觉系统
的相对旋转和平移运动可被估算出来;然后将每两个相邻时刻
之间视觉系统的运动串联起来,可以得到累计的视觉系统相对
于参考坐标系的旋转和平移。如图
2所示,视觉里程计的任务
就是已知 k=0的初始位置 C
0
(可以根据情况自己定义),求相
机的运动轨迹
C
0:n
={C
0
,…,C
n
},即当前的位置 C
k
通过 T
k
和
上一时刻的位置 C
k-1
来计算,公式为 C
k
=C
k-1
×T
k
。其中:T
k
为 K和 K+1时刻的相机相对位置变化,可根据相应时刻采集
的图像计算出来,从而恢复相机的运动轨迹。
视觉里程计可分为特征点法和直接法,如图
3所示。特征
点法主要是根据图像上的特征匹配关系得到相邻帧间的相机
第 37卷第 5期
2020年 5月
计 算 机 应 用 研 究
ApplicationResearchofComputers
Vol.37No.5
May2020
剩余10页未读,继续阅读
资源评论


weixin_38737213
- 粉丝: 1
- 资源: 977









最新资源
- 永磁同步电机传统直接转矩控制仿真,功况波形很好
- Python Flask搭建基于TiDB的RESTful库存管理系统实现
- 面向计算机科学专业学生的作业五任务解析与指引
- 医学图像处理与评估:色调映射及去噪技术的应用
- 有限元方法中Sobolev范数误差估计与Matlab程序改进及应用作业解析
- MATLAB分步傅里叶法仿真光纤激光器锁模脉冲产生 解决了可饱和吸收镜导致的脉冲漂移问题
- 基于java的产业园区智慧公寓管理系统设计与实现.docx
- 基于java的大学生考勤系统设计与实现.docx
- 基于java的本科生交流培养管理平台设计与实现.docx
- 基于java的大学校园生活信息平台设计与实现.docx
- 基于java的党员学习交流平台设计与实现.docx
- 光伏发电三相并网模型 光伏加+Boost+三相并网逆变器 PLL锁相环 MPPT最大功率点跟踪控制(扰动观察法) dq解耦控制, 电流内环电压外环的并网控制策略 电压外环控制直流母线电压稳住750V
- 基于java的多媒体信息共享平台设计与实现.docx
- 基于java的公司资产网站设计与实现.docx
- 基于java的二手物品交易设计与实现.docx
- 基于java的供应商管理系统设计与实现.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


