基于pseudo label的语义分割
150 浏览量
2021-01-20
12:02:08
上传
评论
收藏 191KB PDF 举报

基于基于pseudo label的语义分割的语义分割
1.引言引言
在监督学习领域,人类已经取得了很大的进步,但这也意味着我们需要大量带标签的数据来训练模型,这些算法需要把这些数
据扫描一遍又一遍来寻找最优模型参数。然而现实生产活动中,带标签的数据相对缺乏,海量的无标签数据没有得到充分利
用,本篇博文将浅显的介绍下一种半监督方法——伪标签。
2.什么是伪标签什么是伪标签
伪标签是将可靠的测试数据的预测结果添加到训练数据。伪标签的建立过程大概有五步:(1)利用训练数据建立模型;
(2)预测未知测试数据集的标签;(3)在训练数据中加入可靠的测试数据预测值;(4)利用组合数据训练新模型或微调第
一步中的模型;(5)使用新模型预测测试集数据。
3. 训练过程训练过程
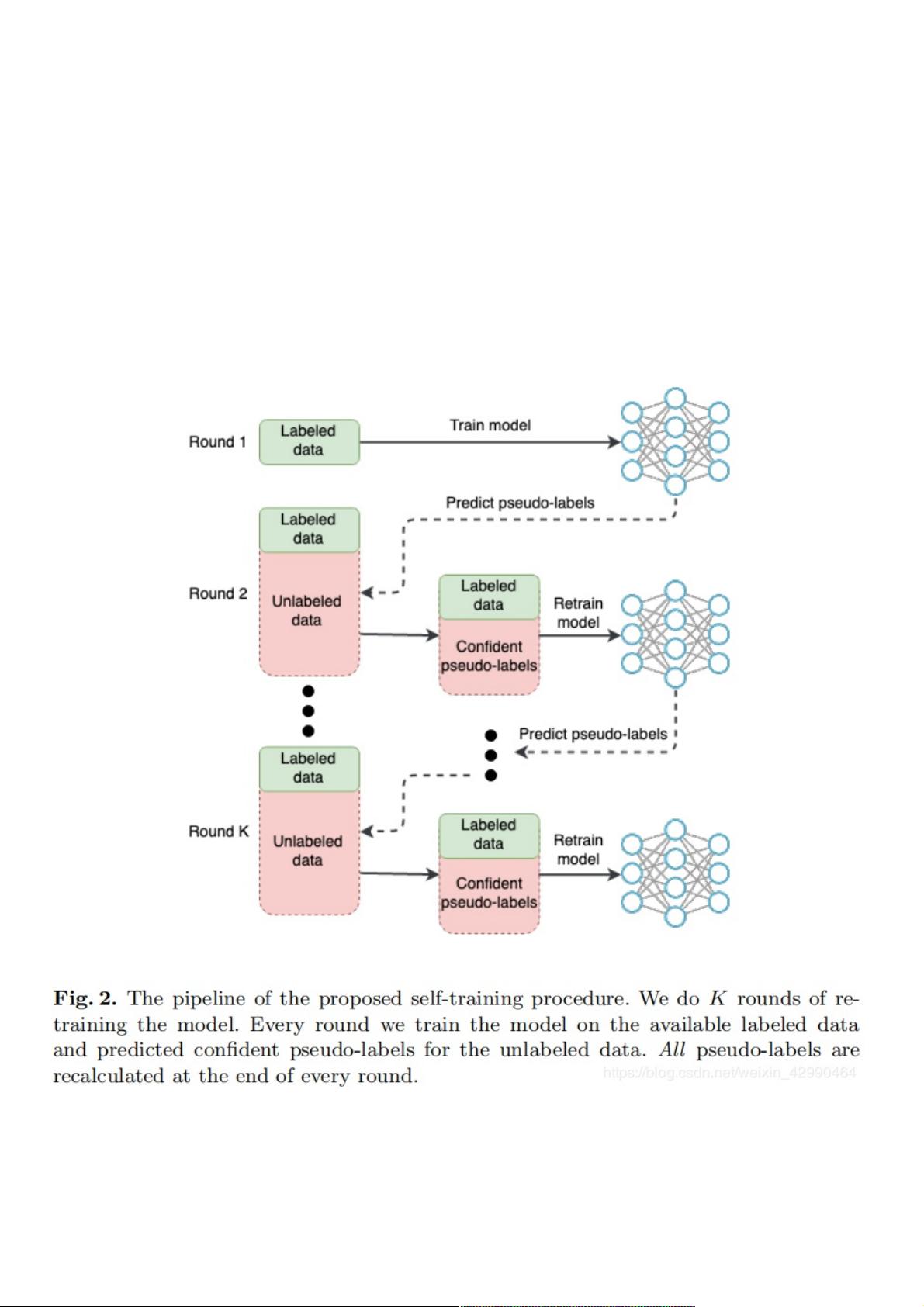
本篇博文参考的是 TGS Salt Identification Challenge上的冠军方案。此方案针对地震图像中标记数据的不足,提出了一种利用
大量未标记数据的半监督方法。利用未标记图像进行自训练,所提出的自训练过程是一个迭代过程,通过交替训练模型和伪标
签来扩展带标签的数据集,对模型进行K轮训练。详细过程如下图所示:
自训练过程时一个K轮迭代过程,每轮有两个步骤:(a)使用伪标签扩展的标记数据集训练模型;(b)更新未标记数据的伪
标签。
在第一轮中,我们只使用GT(Ground Truth)标签来训练模型。然后,我们通过给测试集图像中的每个像素分配最可能的类来预
测所有未标记数据的伪标签。不可靠的预测可以通过删除带有低可信度伪标签来过滤掉。
在下一轮中,我们首先联合使用GT标签和伪标签对模型进行再训练;然后使用新模型更新所有未标记数据的伪标签。在每一
轮的自我训练之前重置模型的权重是至关重要的,而不是在多轮训练的过程中在伪标签积累错误。
为了进一步提高生成的伪标签的鲁棒性,防止对单一模型的误差过度拟合,我们联合训练了一个具有不同主干结构的CNNs集
合。在这种情况下,伪标签是通过对集成中所有模型的预测进行平均而产生的,集成中的每个模型都利用了前一轮集成的可靠
知识,并在伪标签中表示和聚合。
资源评论













