SparkApp自动化分析和故障诊断
15 浏览量
2021-01-27
16:42:48
上传
评论
收藏 2.32MB PDF 举报

SparkApp自动化分析和故障诊断自动化分析和故障诊断
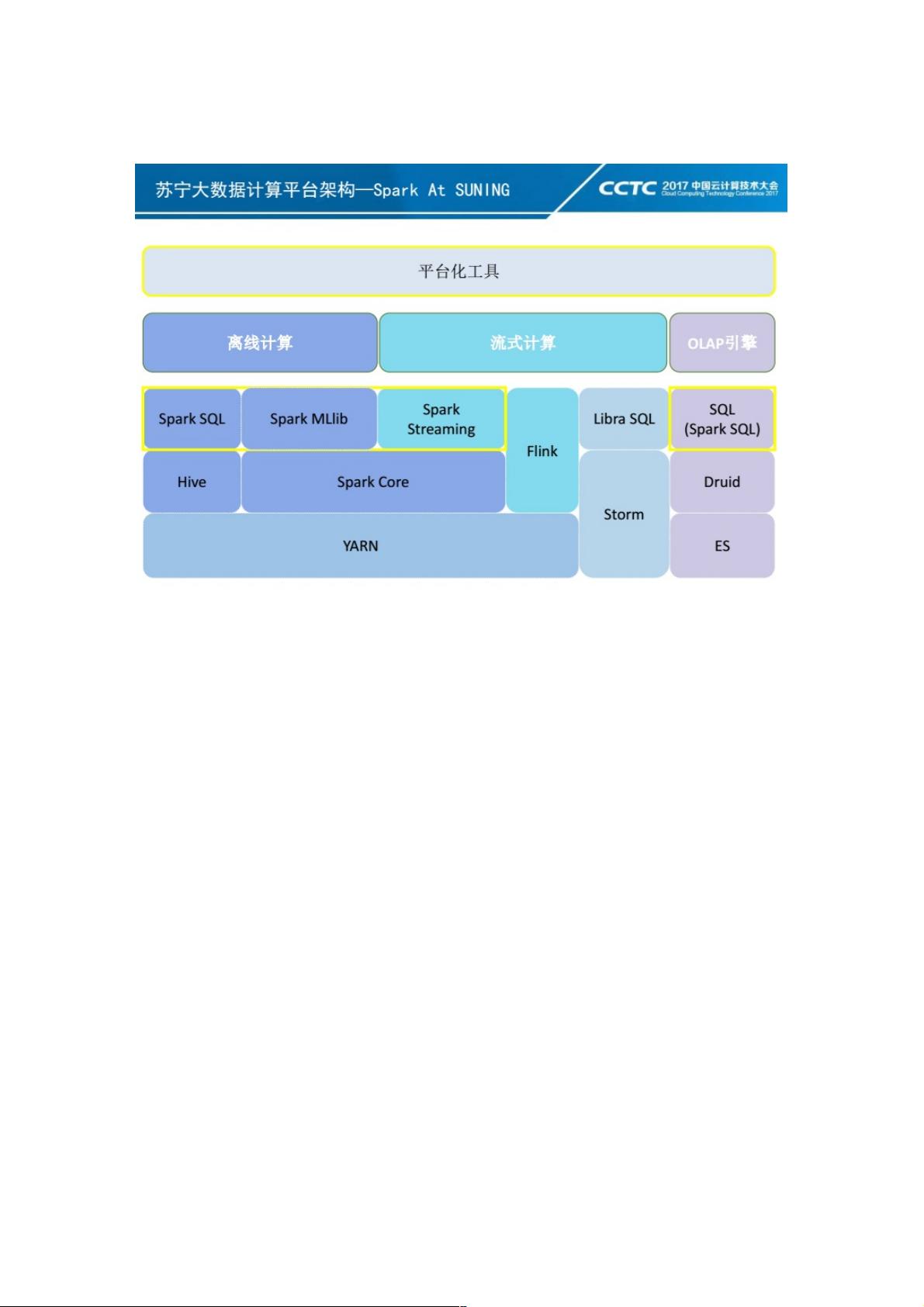
苏宁大数据计算平台架构
苏宁大数据平台的计算引擎主要包括三个组成部分:离线计算、流式计算、OLAP引擎。
离线这块目前主要是依赖Spark和Hive来提供离线数据的分析和挖掘能力。
流式计算这块分为准实时计算和实时流计算。准实时计算主要基于Spark Streaming来满足数秒至分钟级的业务需求,对于实
时流这块,目前我们苏宁大概有1200台Openstack虚拟机(400台实体机)组成的 39个Storm集群,并且在2014年就自研了
Storm SQL引擎Libra,为Storm业务提供SQL接口。从今年年初开始,我们开始逐步去强化Flink在我们架构中的位置,我们希
望利用Flink的强大窗口计算以及EventTime的处理能力来解决我们一些业务上的需求。
OLAP这块目前我们主推Druid和ES两款引擎。我们利用Druid的实时计算能力,来解决我们指标聚合计算上的一些需求;利用
ES快速数据索引定位能力来解决明细查询上的一些需求。
在我们整个架构中,Spark处于一个非常重要的位置。同时我们也为了Spark的平台化服务化,做了很多平台级工具。

剩余12页未读,继续阅读
资源评论













