

用用Hadoop进行分布式数据处理,第进行分布式数据处理,第3部分部分:应用程序开发应用程序开发
简介:简介:?通过已经获得的在单节点和多节点体系结构中 Hadoop 的配置、安装以及使用的经验,您现在可以转到在 Hadoop 基
础设施内开发应用程序的任务上。本文是 系列 文章的最后一篇,其通过简单的 mapper 和 reducer 应用程序探索了 Hadoop
API 和数据流并演示了它们的使用。
此系列的前两篇文章 专注于单节点和多节点集群的 Hadoop 安装及配置。最后这篇文章探索了 Hadoop 编程 — 特别是在
Ruby 语言中 map 和 reduce 应用程序开发。我之所以选择 Ruby,首先是因为,它是一个您应该知道的很棒的面向对象的脚
本语言,其次,您将在 参考资料 部分发现很多参考,其中包括解决 Java? 和 Python 语言的教程。通过这种 MapReduce 编
程的探索,将向您介绍流式应用程序编程接口(Application Programming Interface,API)。此 API 提供方法以便在 Java 语
言以外的多种语言中开发应用程序。
让我们开始简要介绍一下 map 和 reduce(从功能的角度考虑),然后再进一步钻研 Hadoop 编程模型及其体系结构和用来雕
刻、分配、管理工作的元素。
map 和 reduce 的起源
是什么功能性元素激发了 MapReduce 编程范例的创立?在 1958 年,John McCarthy 发明了名为 Lisp 的语言,其实现了数值
和符号计算,但在递归形式下此语言非常不同于现在所使用的大多数语言。(在维基百科全书上记述着 Lisp 那段迷人的历
史,同时包括一个有用的教程 — 值得您花费时间来阅读。)Lisp 最先是在 IBM? 704 中实现的,IBM? 704 是第一种大规模生
产的计算机,也支持其他旧的语言,如 FORTRAN。
map 函数,源于功能性语言(如 Lisp)但如今在其他语言中也很常见,其中包含了一系列元素的函数的应用程序。这意味着
什么? 清单 1 通过 Scheme Shell (SCSH) 提供解释会话,即一个 Lisp 衍生。第一行定义一个名为 square 的函数,该函数可
接受参数并发出其平方根。下一行说明 map 函数的使用。如图所示,通过 map,为已应用的函数提供您的函数和一系列元
素。结果是一个包含平方元素的新列表。
清单清单 1. SCSH 上的上的 map 函数演示函数演示
> (define square (lambda (x) (* x x)))
> (map square '(1 3 5 7))
'(1 9 25 49)
>
Reduce 也适用于列表但是通常将列表缩减为标量值。清单 2中提供的示例说明用于将列表缩减为标量的其他 SCSH 函数 —
在这种情况下,用 (1 + (2 + (3 + (4 + (5))))) 的格式汇总值的列表。请注意这是典型的功能性编程,取决于迭代上的递归。
清单清单 2. SCSH 上的上的 reduce 演示演示
> (define (list-sum lis) (if (null? lis) 0 (+ (car lis) (list-sum (cdr lis)))))
> (list-sum '(1 2 3 4 5))
15
>
有趣的是要注意递归与迭代在命令性语言中同样高效,因为递归在幕后被转化成迭代。
Hadoop 的编程模型
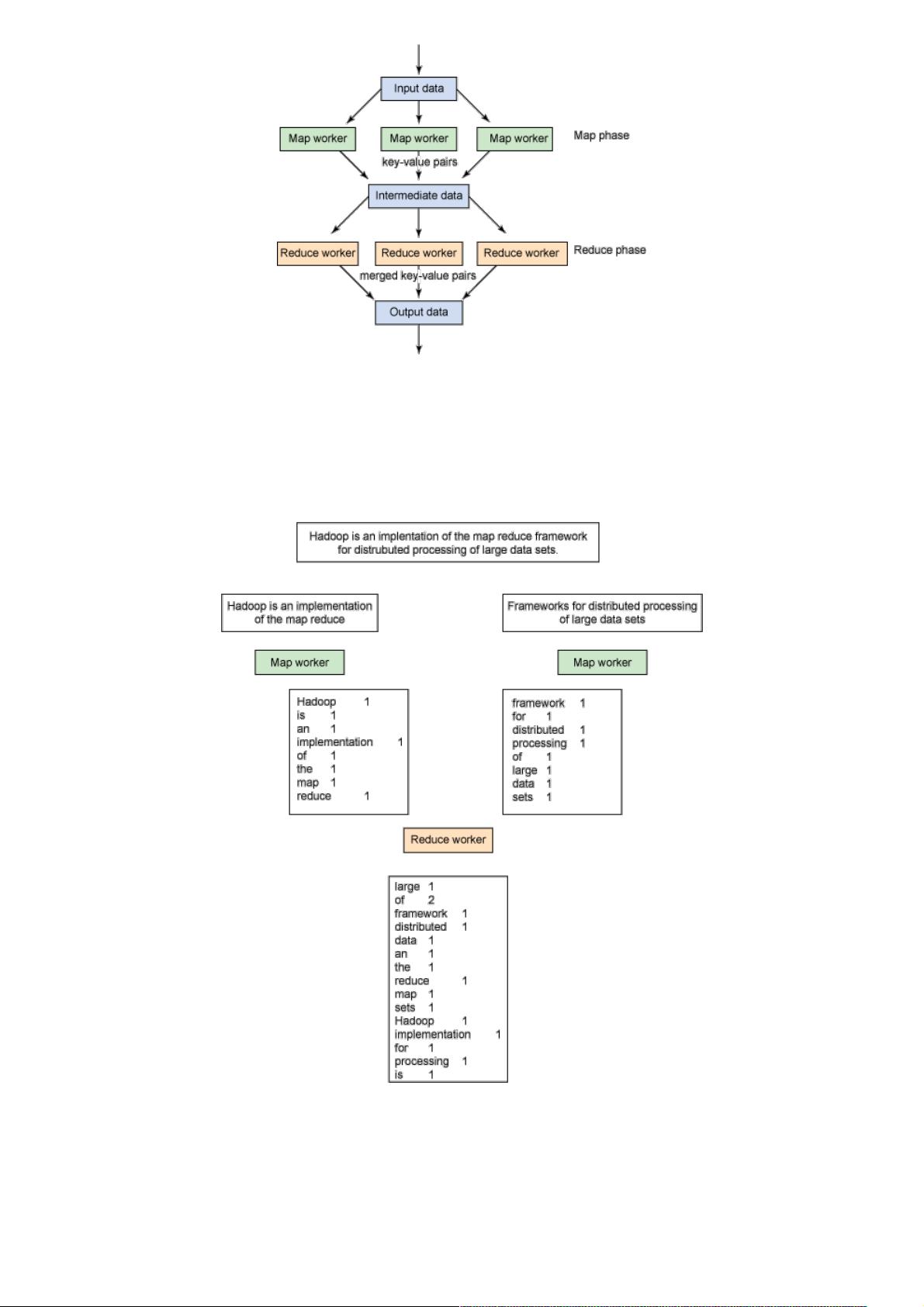
Google 引用 MapReduce 的概念作为处理或生成大型数据集的编程模型。在规范模型中,map 函数处理键值对,这将得出键
值对的中间集。然后 reduce 函数会处理这些中间键值对,并合并相关键的值(请参考图 1)。输入数据使用这样一种方法进
行分区,即在并行处理的计算机集群中分区的方法。使用相同的方法,已生成的中间数据将被并行处理,这是处理大量数据的
理想方法。
图 1. MapReduce 处理的简化视图
剩余6页未读,继续阅读
资源评论













