
版本分布式集群搭建
要求 版本必须为 请先下载好 并解压
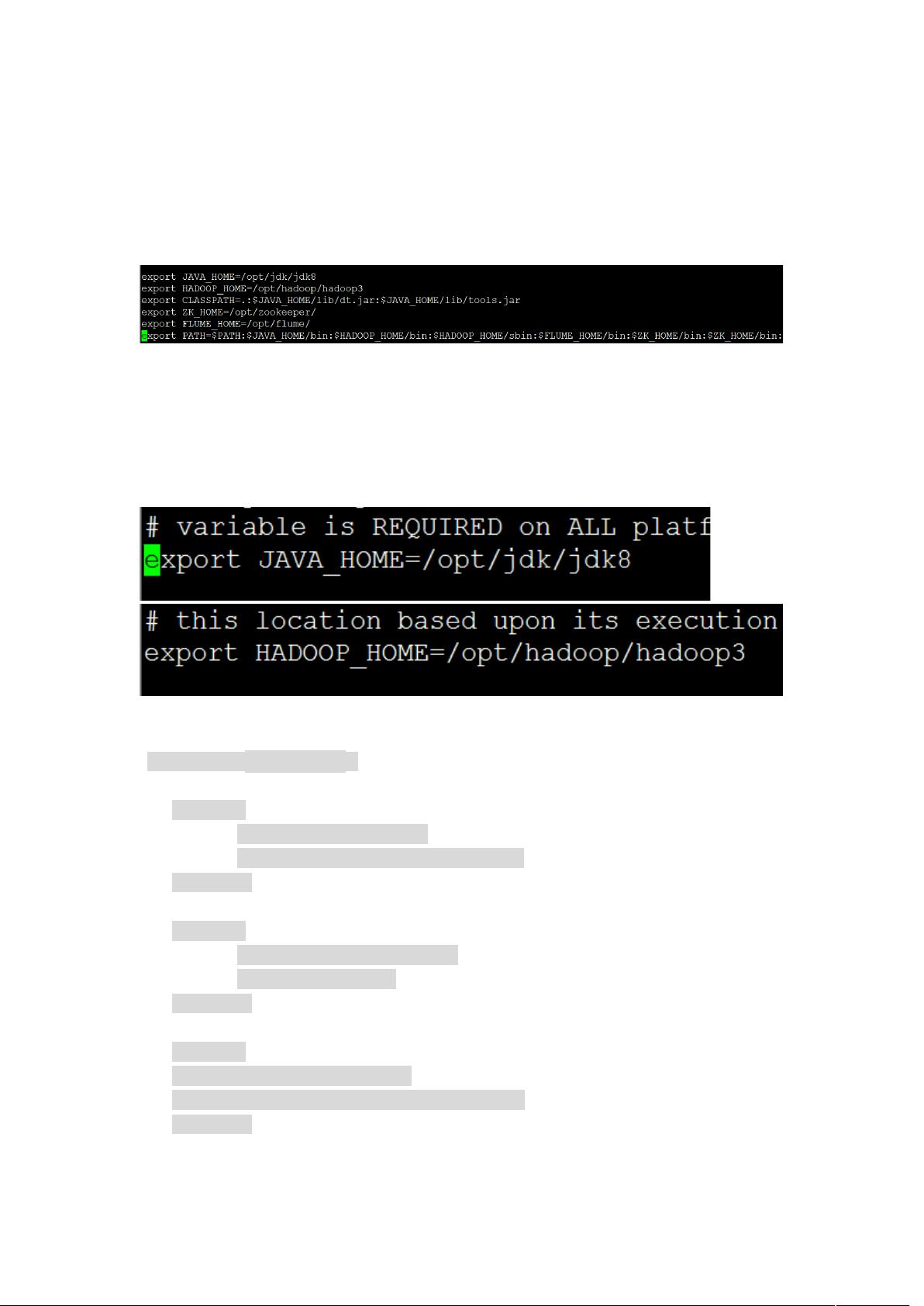
配置 文件信息添加 路径以及 路径配置完请刷新
解压
进入 目录
首先配置 文件配置好 !"#$ 路径以及 ""%!"#$ 路径
&配置 '(在)*+,-)*+,-中间加入一下信息
./ 为第一台节点 0%
)1-
)(-22+34)(-
)+-25./5)+-
)1-
)1-
)(-6+78)(-
)+-9)+-
)1-
)1-
)(-()(-
)+-5()+-
)1-
/配置 2'(在)*+,-)*+,-中间加入一下信息
资源评论


qq_34678029
- 粉丝: 3
- 资源: 5









最新资源
- 【全年行事历】团建活动计划表.xlsx
- 【全年行事历】团建行程安排表-xx山.xlsx
- 【全年行事历】团建活动策划方案.docx
- 【全年行事历】团建开销费用分析.xlsx
- 【全年行事历】团建活动物料清单.xlsx
- 【全年行事历】团建文化衫尺码统计表.xlsx
- 【全年行事历】团建医药箱常备药清单.docx
- 【全年行事历】小型公司活动全年活动行事历.xlsx
- 【全年行事历】员工野外拓展活动方案.docx
- 四足机器人机械结构设计PDF
- 06-公司团建活动申请表.docx
- 03-团建活动策划方案.docx
- 07-团建活动采购预算清单.xlsx
- 08-团建日程计划表.xlsx
- 09-财务公司月度团建支出表.xlsx
- T-SQL查询高级SQLServer索引中的碎片和填充因子word文档doc格式最新版本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


