第2章 文本的歧义及其清理(包括,分词,去除停用词,词干提取,词形还原等)
57 浏览量
2020-12-21
06:58:04
上传
评论
收藏 106KB PDF 举报

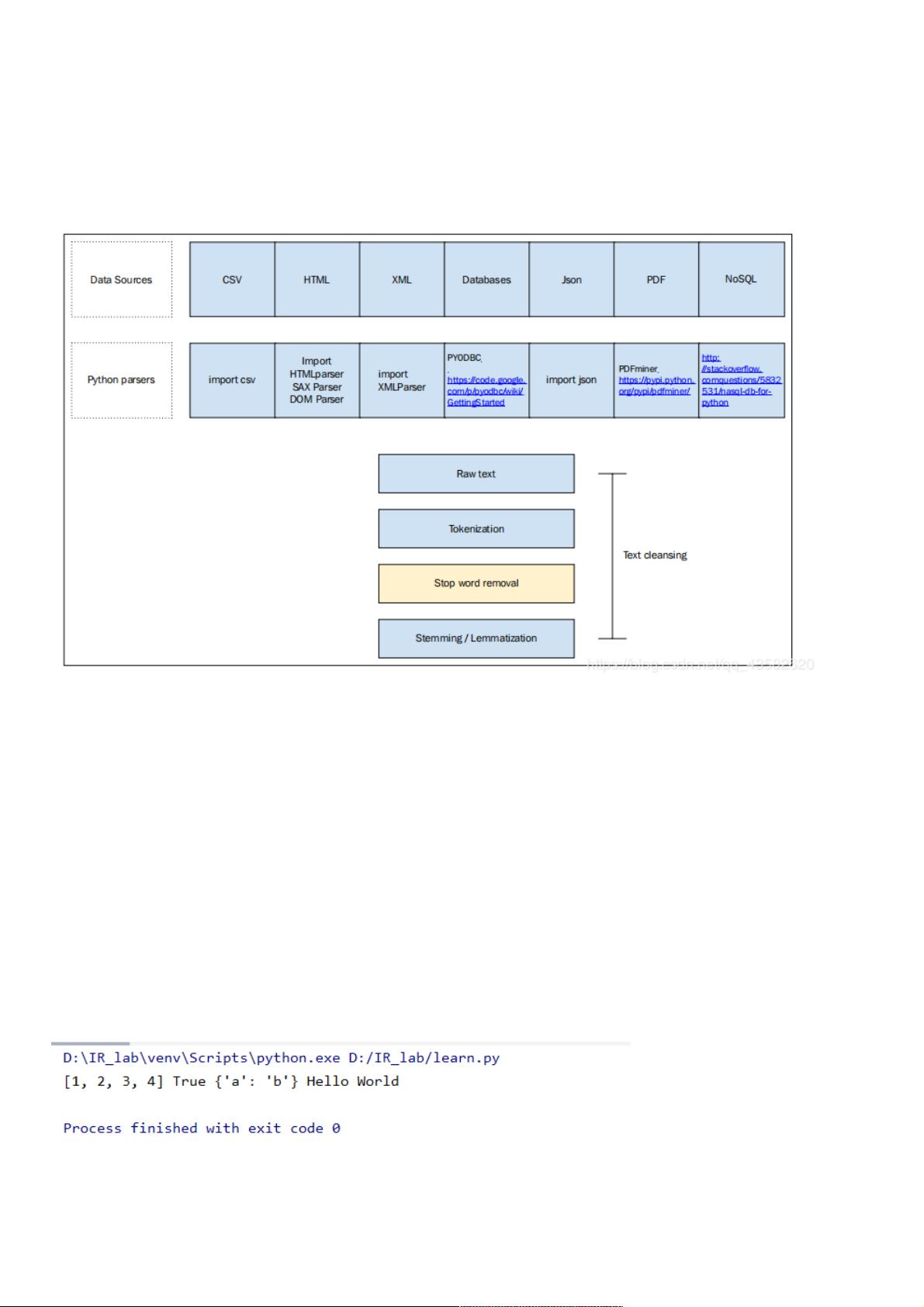
第第2章章 文本的歧义及其清理(包括,分词,去除停用词,词干文本的歧义及其清理(包括,分词,去除停用词,词干
提取,词形还原等)提取,词形还原等)
第第2章章 文本的歧义及其清理文本的歧义及其清理
文本处理的过程:文本处理的过程:
词项化—>去除停用词—->词干提取或词形还原
1. 简单看看简单看看json文件的基本内容:文件的基本内容:
example.json:
{
“array”: [1,2,3,4],
“boolean”: “True”,
“object”: {
“a”: “b”
},
“string”: “Hello World”
}
简单的处理代码:
import json
#打开文件
jsonfile=open("example.json")
#加载数据
data=json.load(jsonfile)
print(data['array'],data['boolean'],data['object'],data['string'])
结果如下:
2.语句分离语句分离
前边应该进行文本清理,如前面对html语言进行处理不必要字符,以及删去长度短的字母。
语句分离即将大段原生文本分割成一系列语句。
利用利用
sent_tokenize
分离语句分离语句
:













评论0