

THE JOURNAL OF CHINA UNIVERSITIES OF POSTS AND TELECOMMUNICATIONS
Volume 14, Issue 3, September 2007
ZHANG Yong-jing, LIN Yue-wei
Markov game for autonomic joint radio resource
management in a multi-operator scenario
CLC number TN929.5 Document A Article ID 1005-8885 (2007) 03-0048-08
Abstract This article addresses the autonomy of joint radio
resource management (JRRM) between heterogeneous radio
access technologies (RATs) owned by multiple operators. By
modeling the inter-operator competition as a general-sum
Markov game, correlated-Q learning (CE-Q) is introduced to
generate the operators’ pricing and admission policies at the
correlated equilibrium autonomically. The heterogeneity in
terms of coverage, service suitability, and cell capacity amongst
different RATs are considered in the input state space, which is
generalized using multi-layer feed-forward neural networks for
less memory requirement. Simulation results indicate that the
proposed algorithm can produce rational JRRM polices for each
network under different load conditions through the autonomic
learning process. Such policies guide the traffic toward an
optimized distribution and improved resource utilization, which
results in the highest network profits and lowest blocking
probability compared to other self-learning algorithms.
Keywords autonomic, JRRM, multi-operator, reinforcement
learning (RL), Markov game
1 Introduction
The co-existence of heterogeneous RATs, including universal
mobile telecommunications system (UMTS), wireless local
area networks (WLAN), and many others, characterizes the
Beyond 3rd generation (B3G) environment in the future. The
overlapping coverage, diverse service requirements,
complementary technical characteristics entail the integration
and cooperation between the RATs for better user experience
and higher system performance [1]. Based on the software-
defined radio technology, the end-to-end reconfigu- rability [2]
has been developed to facilitate the JRRM by providing
terminals and networks the abilities of dynamically selecting
and adapting to the required RATs and operating spectrum
range [3]. Several studies have been done in this area concerning
Received date: 2006-03-03
ZHANG Yong-jing ( ), LIN Yue-wei
School of Telecommunication Engineering, Beijing University of Posts and
Telecommunications, Beijing 100876, China
E-mail: yongjing.zhang@gmail.com
different aspects, such as joint session admission control [4],
joint session scheduling [5], and joint load control [6]. However,
they focus mostly on the single-operator scenario where a
centralized JRRM controller can have the resources well
managed across RATs in a cooperative way. In a
multi-operator scenario, such entity is hardly applicable so
that JRRM tasks should be decentralized and the
inter-operator competition must also be considered.
Furthermore, existing studied have not addressed the
autonomy of the management, which is becoming more and
more important as the system complexity grows higher with
the increasing technologies and devices that overwhelm users
and network administrators [7].
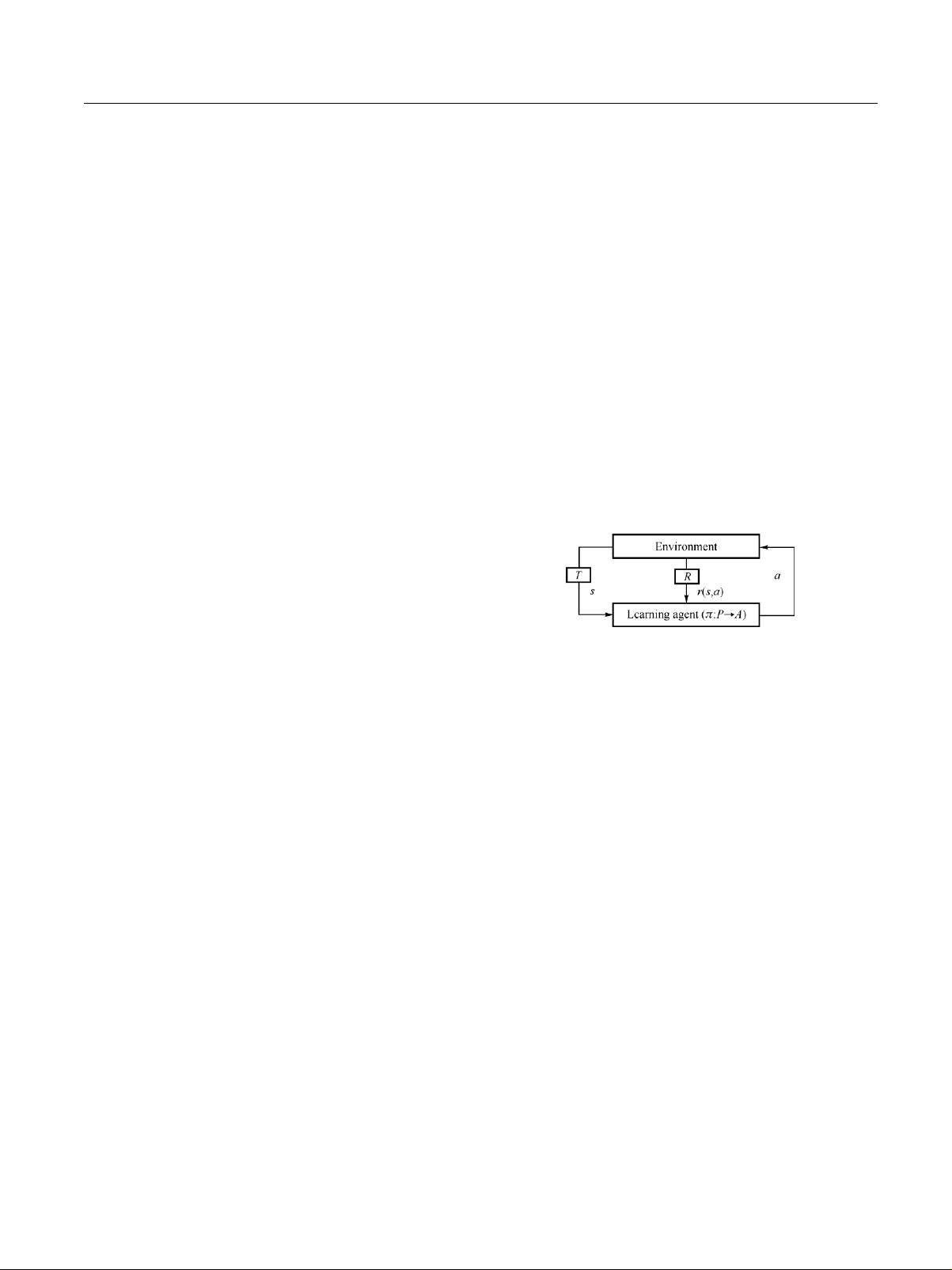
To generate the optimal JRRM policies for individual RAT
autonomically, learning capability is indispensable to the
JRRM entities (called agents). Amongst several categories of
machine learning techniques, RL seems most promising for its
successful applications in many areas including robotics,
computer game playing [8], as well as, mobile communication
systems [9]. RL enables an agent to learn to act without
knowing the environment model; however, its convergence
requires the assumption of Markov decision process (MDP),
which is no longer satisfied in a multi-agent environment as in
the multi-operator JRRM issue. Fortunately, several multi-
agent RL (MARL) algorithms [1013] have been developed in
the framework of Markov game. In spite of their respective
limitations, these algorithms provide the opportunities for the
solution to the problem.
In this article, an attempt is made to realize the multi-
operator JRRM in an autonomic way by formulating it as a
Markov game and using the CE-Q approach [13]. Considering
the practical challenge of the memory requirement, neural
network-based function approximation is also adopted in the
solution to generalize the large input state space.
2 Problem definition
2.1 JRRM in a multi-operator scenario
Supposing multiple operators running several heterogeneous
RATs overlapped in a densely populated area, people equipped
剩余7页未读,继续阅读
资源评论













