
Spark Core 笔记笔记02
Spark Core学习学习
对最近在看的赵星老师Spark视频中关于SparkCore的几个案例进行总结。
目录目录1.WordCountWordCount 执行流程详解2.统计最受欢迎老师topN1. 方法一:普通方法,不设置分组/分区2. 方法二:设置分组和过滤器3. 方法三:自定义分区器3.根据IP计算归属地
1.WordCount
Spark Core入门案例。
//创建spark配置,设置应用程序名字
//val conf=new SparkConf().setAppName("ScalaWordCount")
//设置本地调试
val conf=new SparkConf().setAppName("ScalaWordCount").setMaster("local[4]")
//创建spark执行的入口
val sc=new SparkContext(conf)
//指定以后从哪里读取数据创建RDD
//sc.textFile(args(0)).flatMap(_.split("")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).saveAsTextFile(args(1))
val lines: RDD[String] = sc.textFile(args(0))
//切分压平
val words:RDD[String]=lines.flatMap(_.split(""))
//将单词和一组合
val wordAndOne: RDD[(String, Int)] = words.map((_,1))
//按key进行聚合
val reduced: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//排序
val sorted: RDD[(String, Int)] = reduced.sortBy(_._2,false)
//将结果保存到HDFS中
sorted.saveAsTextFile(args(1))
//释放资源
sc.stop()
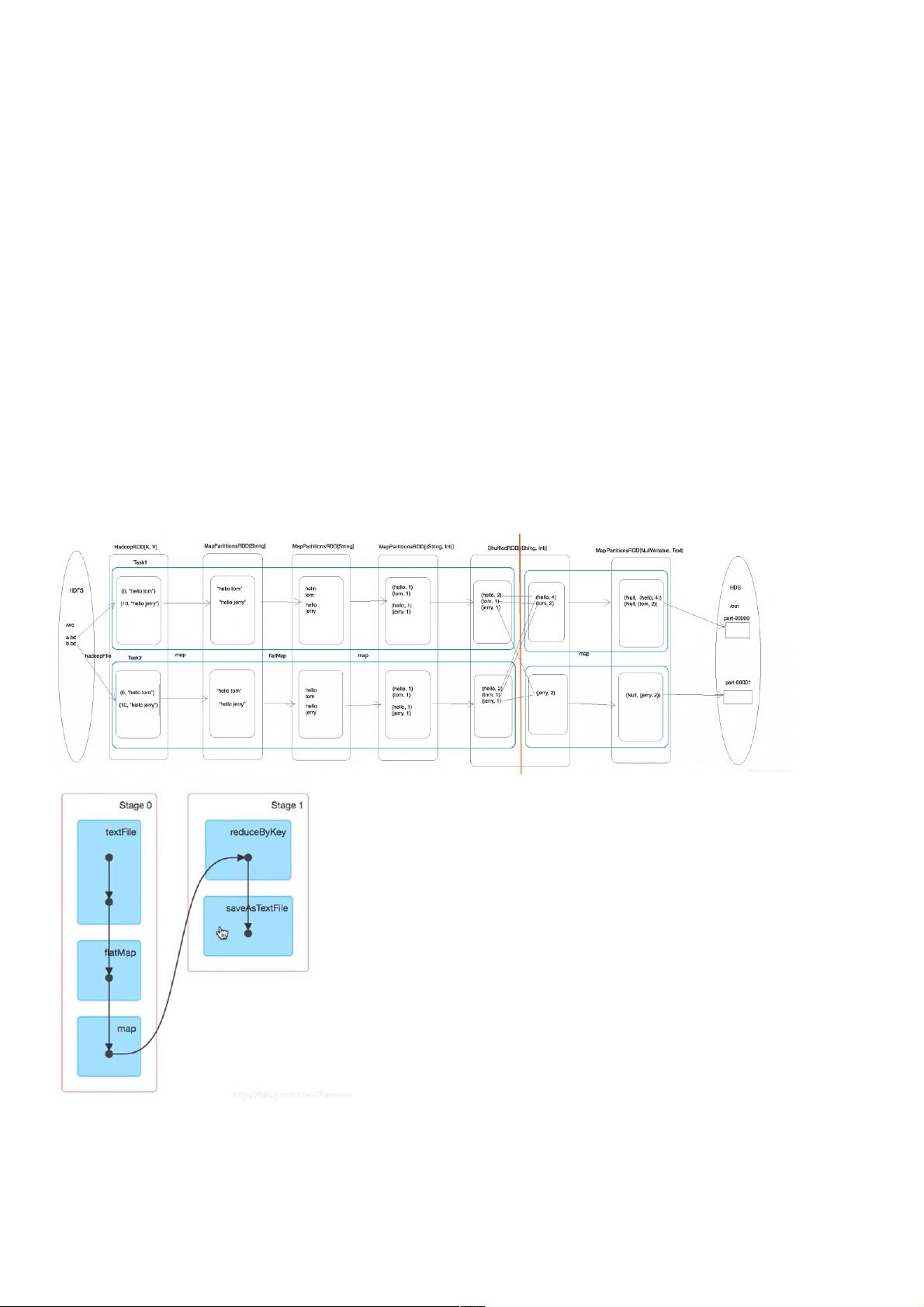
WordCount 执行流程详解执行流程详解
WordCount执行过程中一共生成6个 RDD,2个Stage(一次shuffle),task取决于分区数量
注意点:
1. textFile方法生成两个RDD,一个为HadoopRDD,一个为内部调用map方法产生的MapParitionsRDD
2. 切分Stage的方法为区分宽窄依赖,shuffle次数等于宽依赖次数
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
WordCount执行流程:
DAG可视化:可视化:
2.统计最受欢迎老师统计最受欢迎老师topN
数据描述:
数据格式为以下类型:http://学科.edu360.cn/老师
http://bigdata.edu360.cn/laozhang
http://bigdata.edu360.cn/laozhang
http://bigdata.edu360.cn/laozhao
http://bigdata.edu360.cn/laozhao
http://javaee.edu360.cn/xiaoxu
http://javaee.edu360.cn/laoyang
1. 方法一:普通方法,不设置分组方法一:普通方法,不设置分组/分区分区
//创建spark配置,设置应用程序名字
val conf=new SparkConf().setAppName("ScalaWordCount").setMaster("local[4]")
资源评论


weixin_38709379
- 粉丝: 3
- 资源: 954









最新资源
- 基于Python基于TensorFlow深度学习卷积神经网络自动识别网站验证码设计毕业源码案例设计详细文档+全部资料+优秀项目+源码.zip
- 基于Python卷积神经网络人脸识别驾驶员疲劳检测与预警系统设计毕业源码案例设计详细文档+全部资料+优秀项目+源码.zip
- 基于pytorch卷积神经网络的中文手写汉字识别,使用HWDB数据库详细文档+全部资料+优秀项目+源码.zip
- 基于pytorch框架的手写字体分类和识别(采用卷积神经网络模型)详细文档+全部资料+优秀项目+源码.zip
- 基于Pytorch的卷积神经网络MNIST手写数字识别 适用于Pytorch与神经网络入门学习详细文档+全部资料+优秀项目+源码.zip
- 基于tensorflow的的cnn卷积神经网络的图像识别分类详细文档+全部资料+优秀项目+源码.zip
- 基于tensorflow2.x卷积神经网络的寻迹小车实现详细文档+全部资料+优秀项目+源码.zip
- 基于TensorFlow的人脸识别卷积神经网络详细文档+全部资料+优秀项目+源码.zip
- 基于Tensorflow卷积神经网络天气图像识别系统设计毕业源码案例设计详细文档+全部资料+优秀项目+源码.zip
- 基于TensorFlow的深度学习、深度增强学习代码详细文档+全部资料+优秀项目+源码.zip
- 基于VGGNet16卷积神经网络的猫狗识别详细文档+全部资料+优秀项目+源码.zip
- 基于TensorFlow平台,使用卷积神经网络,实现CIFAR-10图像分类。详细文档+全部资料+优秀项目+源码.zip
- 基于百度API的菜品识别、动物识别和植物识别以及基于机器学习的卷积神经网络的手写体识别详细文档+全部资料+优秀项目+源码.zip
- 基于卷积神经网络 MINST 手写数字识别详细文档+全部资料+优秀项目+源码.zip
- 基于卷积神经网络(CNN)的人脸在线识别系统详细文档+全部资料+优秀项目+源码.zip
- 基于常规波束形成的时间窗方法以及基于卷积神经网络的时间窗方法水下目标方位估计算法详细文档+全部资料+优秀项目+源码.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


