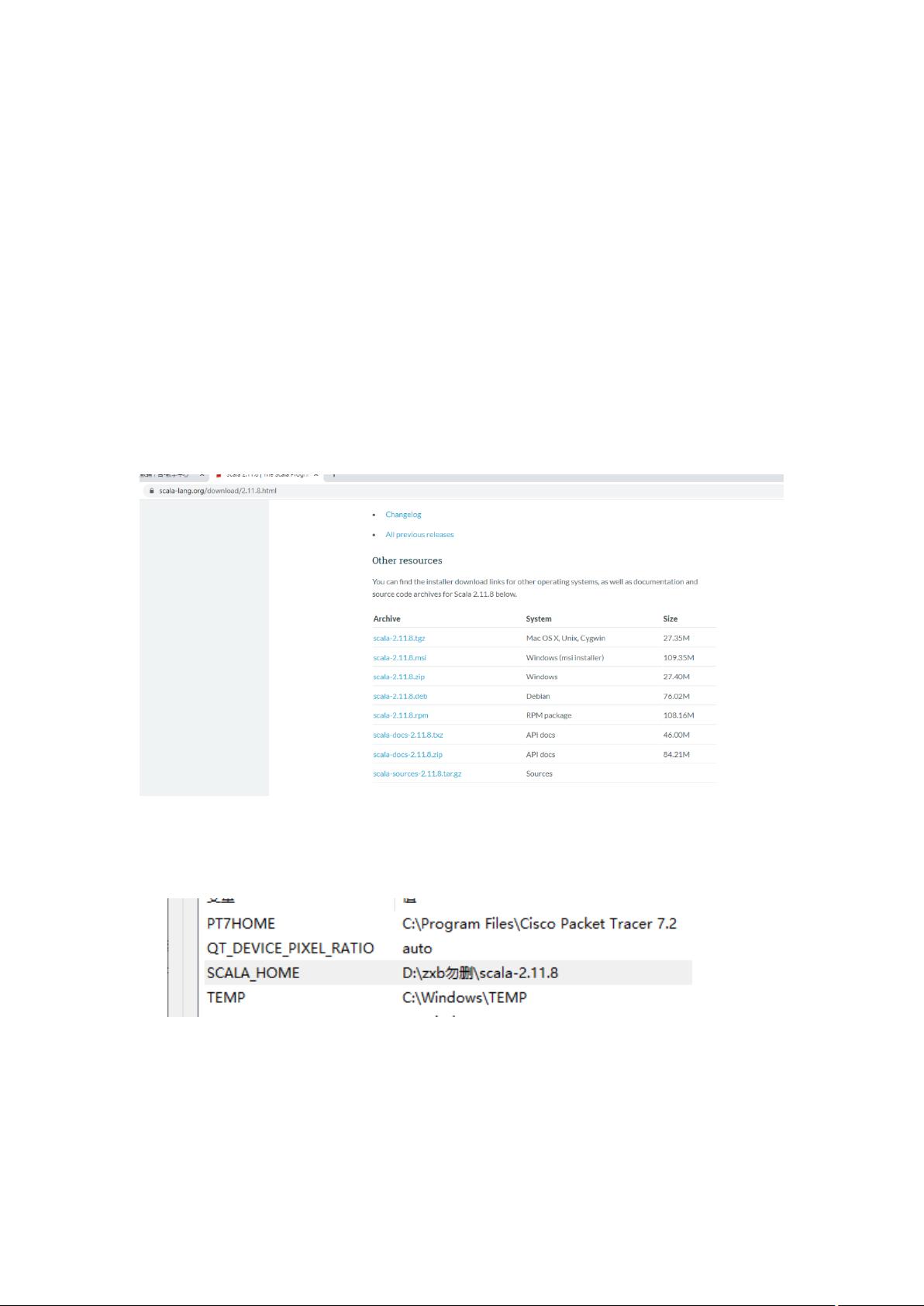
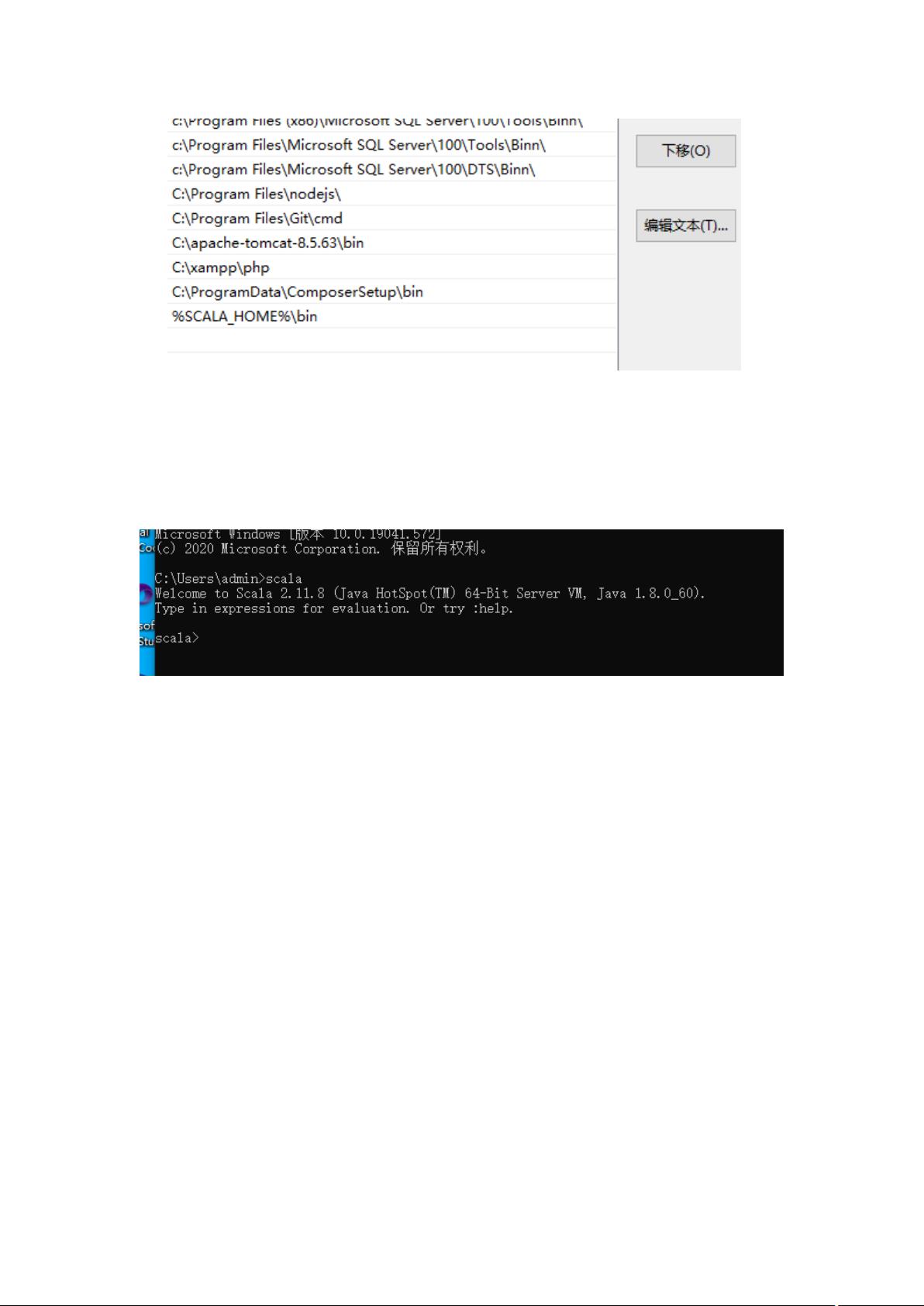
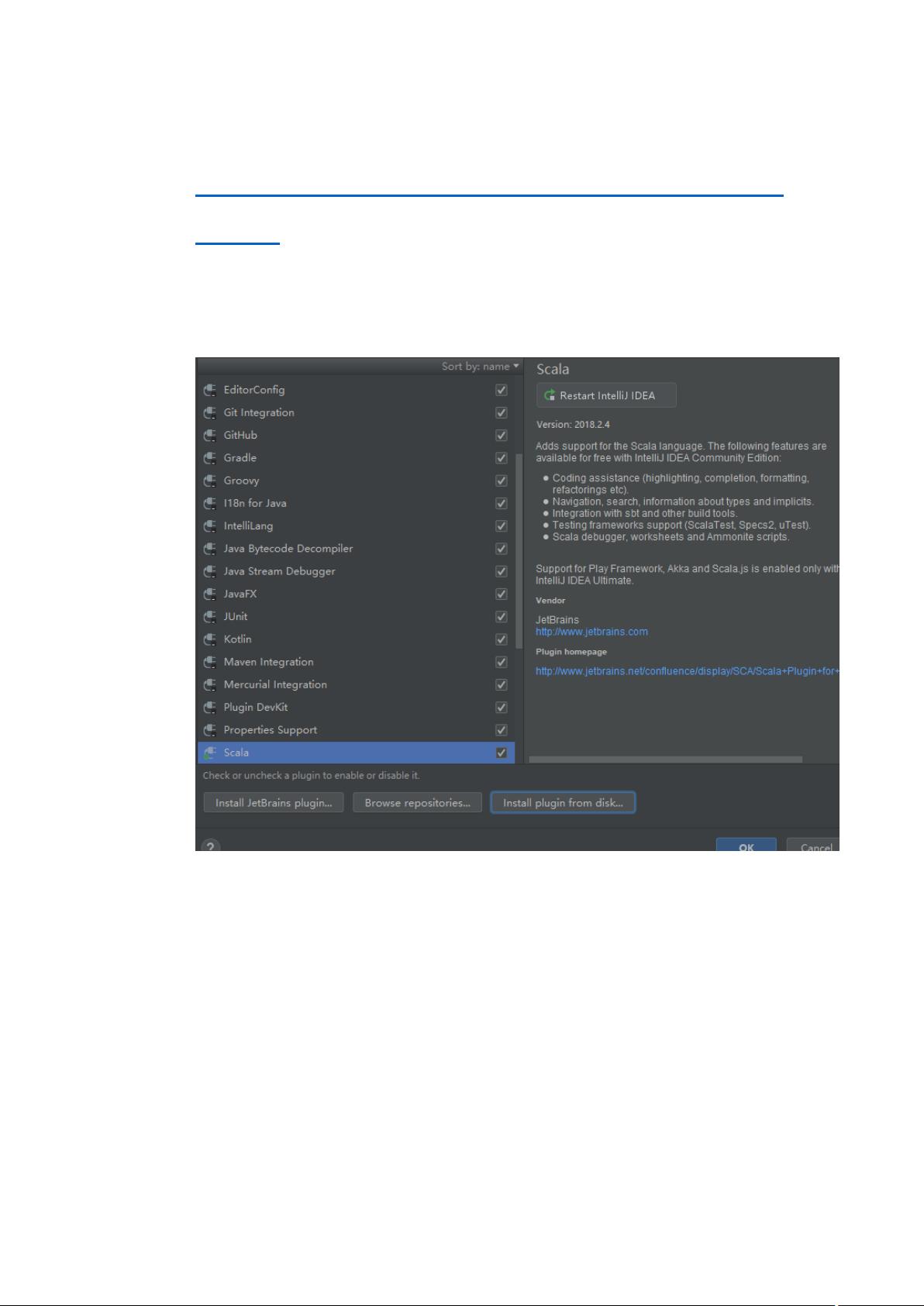
Spark是大数据处理领域的一款高效、通用且可扩展的计算框架,它主要设计用于处理大规模数据集。本笔记主要关注Spark的基础知识,同时也涉及了Scala语言的学习,因为Spark主要是用Scala编写的。 Scala是一种静态类型的多范式编程语言,它结合了面向对象和函数式编程的特点。在第一章中,我们学习了Scala的基本入门知识,包括如何在不同操作系统上安装Scala,需要先安装Java Development Kit (JDK),确保版本符合要求。在集成开发环境(Integrated Development Environment, IDEA)中,我们需要下载并安装Scala插件以便进行开发。创建Scala程序的步骤包括创建新项目、选择源代码包、创建Scala类,如Class、Object或Trait。 接着,进入Scala的基础语法部分,包括声明值和变量。在Scala中,变量分为可变变量(var)和不可变常量(val)。数据类型方面,Scala有着丰富的内置类型,所有的值都有其特定的类型,包括基本数值类型和函数类型。此外,Scala支持算术运算符,它们与Java类似,但使用方法调用的形式,如`a.+`(b)`。控制语句结构涵盖条件分支(if...else)和循环(for、while、do...while)语句,这些语句在Scala中具有独特的语法结构。 在方法和函数的讨论中,了解到Scala中的方法是类的一部分,而函数则可以赋值给变量。定义方法使用`def`,调用时直接使用方法名,而函数也可以使用`val`定义,使得函数可以作为一等公民对待。在数据结构部分,我们接触到Scala的数组、列表、集合等概念,这些都是处理大数据时非常重要的数据组织形式。 Spark开发需要扎实的Scala基础,包括其语法、数据结构和控制流。理解这些基础知识对于有效地利用Spark进行大数据分析至关重要。在后续的学习中,我们将会深入到Spark的RDD(Resilient Distributed Datasets)、DataFrame、Spark SQL,以及Spark的并行计算模型、容错机制等核心概念,这些都是Spark在大数据处理中强大的功能体现。
剩余181页未读,继续阅读








评论0
最新资源