
书书书
第 40卷 第 3期 国 防 科 技 大 学 学 报 Vol.40No.3
2018
年 6月 JOURNALOFNATIONALUNIVERSITYOFDEFENSETECHNOLOGY Jun.2018
doi:10.11887/j.cn.201803023 http://journal.nudt.edu.cn
关系抽取中远监督错误标注消除
汝承森,唐晋韬,谢松县,李莎莎,王 挺
(国防科技大学 计算机学院,湖南 长沙 410073)
摘 要:目前远监督方法被广泛应用于关系抽取任务。然而,远监督方法中存在大量错误标注现象,给
远监督方法的学习效果带来了很大的影响。提出利用语义 Jaccard度量关系短语与依存词间语义相似性的错
误标注消除方法。消除错误标注后的训练数据用于训练模型,完成关系抽取。实验结果表明:该方法可以有
效消除错误标注,提高关系抽取的性能。
关键词:关系抽取;远监督;错误标注;语义相似性
中图分类号:TP391 文献标志码:A 文章编号:1001-2486(2018)03-148-05
Reducingwronglabelsindistantsupervisionforrelationextraction
RUChengsen,TANGJintao,XIESongxian,LIShasha,WANGTing
(CollegeofComputer,NationalUniversityofDefenseTechnology,Changsha410073,China)
Abstract:Distantsupervisionhasbeenwidelyusedforrelationextractionrecently.Inthedistantsupervision,manylabelsmaytowrongly
marked,whichexertsabadimpactonrelationextraction.AmethodtoreducewronglabelswasintroducedbyusingthesemanticJaccardtomeasure
semanticsimilaritybetweentherelationphrasesandthedependencyterms.Thetrainingdataafterreducingwronglabelswasusedtotrainthe
relationextractors.Theexperimentalresultsshowthattheproposedmethodcaneffectivelyreducewronglabelsandimprovetherelationextraction
performancecomparedwiththestateofartmethods.
Keywords:relationextraction;distantsupervision;wronglabels;semanticsimilarity
当今时代,信息呈现爆炸式增长,能够快速准
确地从海量信息中获取用户所需要的信息显得尤
为重要。信息抽取技术
[1-2]
的出现为用户解决了
这一难题。关系抽取是信息抽取的关键技术之
一,是一个从文本中抽取结构化信息的过程
[3]
,
对于问答系统、机器阅读以及知识图谱等应用具
有重要意义。但是,关系抽取方法通常面临缺少
标注数据问题
[4]
。标注数据需要耗费大量人力
物力。为缓解标注语料不足问题,Mintz等
[5]
利用
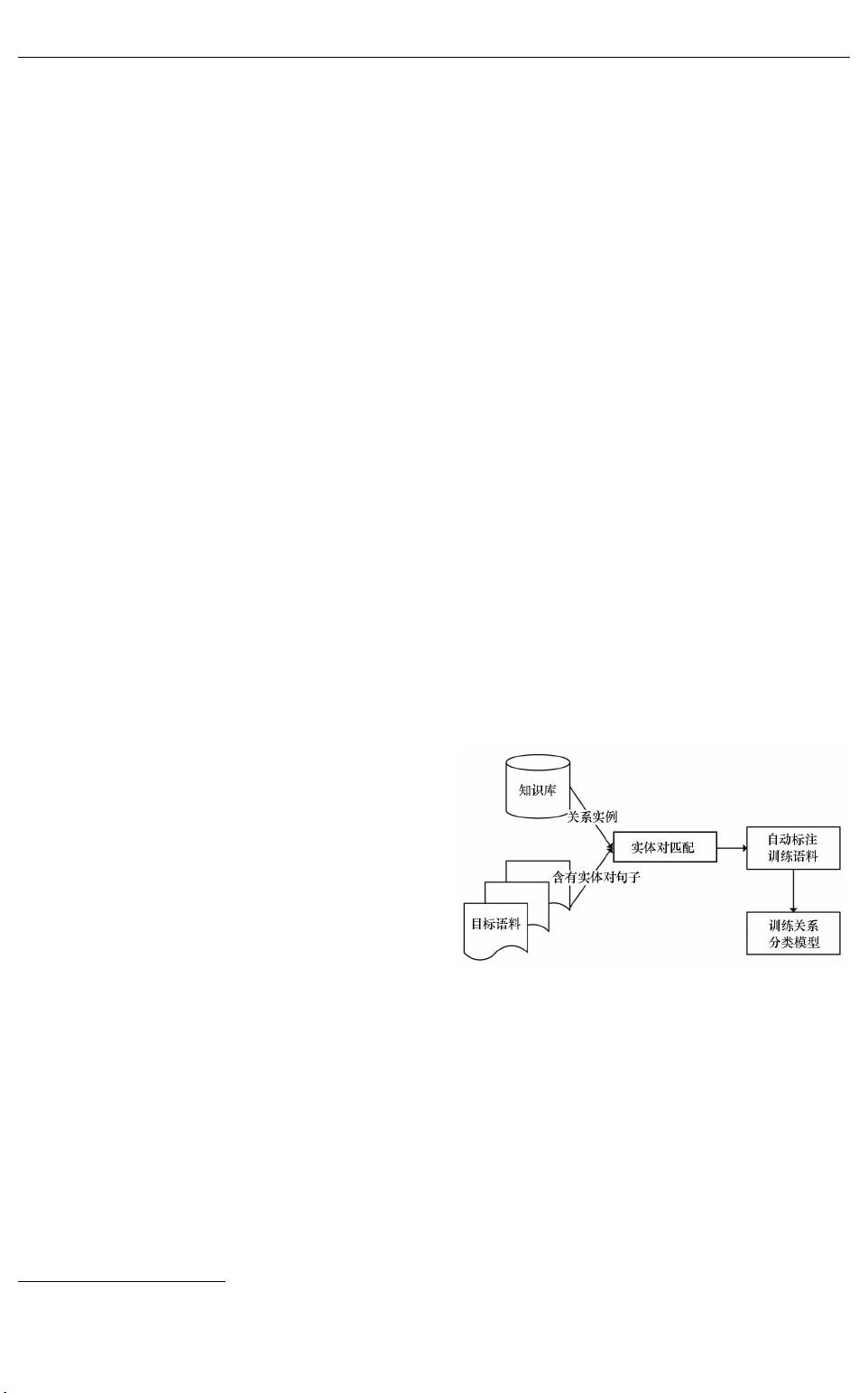
远监督方法进行关系抽取。如果一个句子包含的
实体对与知识库中已有关系实例的实体对相同,
远监督方法将该句子标注为对应关系的实例,具
体流程如图
1所示。
远监督方法可以自动标注训练语料,节省了
大量人力物力。但是,由于两个实体间的关系可
能不止一种,这样就会导致错误标注现象。为消
除错误标注,
Riedel
[6]
与 Hoffmann
[7]
等假设同一
实体对的所有出现中至少有一个是特定关系的正
图 1 远监督关系抽取流程
Fig.1 Processofdistantsupervisionrelationextraction
确描述,使用多实例学习消除错误标注训练正例
的影响。他们的工作没有直接消除错误标注训练
正例。当实体对只在语料中出现了一次并且没有
描述目标关系时,上述方法就会失效。为了直接
消除错误标注训练正例,Takamatsu等
[8]
提出了
一种生成模型方法,依据标注语料评估关系对应
模式的概率,消除错误标注。Han等
[9]
提出了一
收稿日期:2016-11-25
基金项目:国家自然科学基金资助项目(61472436,61532001,61303190)
作者简介:汝承森(1988—),男,山东聊城人,博士研究生,Email:ruchengsen@nudt.edu.cn;
王挺(通信作者),男,教授,博士,博士生导师,
Email:tingwang@nudt.edu.cn
资源评论


weixin_38707240
- 粉丝: 5
- 资源: 921









最新资源
- 2015-2024年上市公司商道融绿esg评级数据(年度)
- DeepSeek:通用人工智能从入门到精通的技术解析与应用指南
- 离散扩展龙伯格观测器:扰动补偿功能下的鲁棒性能优化及动态响应增强策略,离散扩展龙伯格观测器:具有扰动补偿功能的高鲁棒性预测控制系统,一种具有扰动补偿功能的离散扩展龙伯格观测器,有较好的参数摄动扰动抑制
- 无刷直流电机BLDC三闭环控制系统的Matlab Simulink仿真模型搭建:原理、波形记录与参数详解,无刷直流电机BLDC三闭环控制系统的Matlab Simulink仿真模型搭建:原理、波形记录
- 基于Python的Django-vue基于spark的短视频推荐系统的设计与实现源码-说明文档-演示视频.zip
- DeepSeek写的重力球迷宫手机小游戏
- 单相变压器绕组与铁芯振动形变仿真模型:洛伦兹力与磁致伸缩效应下的动态响应分析,COMSOL单相变压器绕组与铁芯振动形变仿真模型:基于洛伦兹力与磁致伸缩效应的时域分析,comsol的单相变压器绕组及铁芯
- 新兴经济体二氧化碳排放报告2024.pdf
- 激光熔覆技术:COMSOL模拟建模与视频教程服务,助力激光研究人员与工程师的专业提升,激光熔覆技术:COMSOL软件下的建模与视频教程应用指南,COMSOL 激光 激光熔覆 名称:激光熔覆 适用人群:
- 2000-2023年上市公司价值链升级数据(含原始数据+计算代码+结果)
- COMSOL仿真下的钢架无损超声检测:焊接区域及周边缺陷识别技术,角钢梁纵波转横波检测原理揭秘,Comsol仿真技术下的钢架无损超声检测:角钢梁缺陷的精准识别与定位,Comsol仿真钢架无损超声检测
- 基于FPGA的图像坏点像素修复算法实现及Matlab辅助验证:探索其原理、测试与使用视频教程 注:标题中的“可刀”一词在此上下文中并无实际意义,因此未被包含在标题中 标题长度符合要求,并尽量简洁明了
- 2008-2022年各省环境污染指数数据(原始数据+结果).xlsx
- zhaopin_mzhan.apk
- 权威科研机构发布钢轨表面缺陷检测数据集,含400张图像和8种类别缺陷,mAP达0.8,附赠lunwen,钢轨表面缺陷检测数据集:包含400张图片与八种缺陷类别,适用于目标检测算法训练与研究 ,钢轨表面
- C形永磁辅助同步磁阻电机Maxwell参数化模型:转子手绘设计及关键参数优化分析,基于Maxwell参数化模型的C形永磁辅助同步磁阻电机研究:转子手绘非UDP模块的参数化设计及优化分析,C形永磁辅助同
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


