
基于基于Hadoop的数据密集型应用开发优化平台的数据密集型应用开发优化平台
1、引言
互联网数据处理、科学计算、商业智能等领域都存在着海量数据处理需求,存在大量数据密集型应用[1]。Google提出了Map
Reduce [2]编程模型,开发人员只需要编写单个节点的处理任务,由计算平台来提供任务的并行处理及维护,大大降低了并行
编程的难度。这种计算平台通常建立在分布式文件系统之上,可以实现很好的可扩展性和容错性,逐渐成为云计算平台的重要
组成部分。
但是采用Map Reduce编程模型开发一个数据密集型应用,用户不仅需要对各个数据操作按照Map Reduce进行实现,还要实
现多个操作之间中间数据的传输,实现复杂的数据处理流程,另外采用Map Reduce编程模型编写的代码十分复杂,流程类的
处理任务的代码量将急剧膨胀,难于维护。如何为这些计算平台提供高效的编程模型和开发工具成为重要的研究方向,模型驱
动的方法可以提高编程的效率,也利于在模型层进行性能优化,在很多领域有成功经验,比如数据仓库领域的ETL(Extract-
Transform-Load)工具都提供了可视化的数据流程设计工具。
Apache Hadoop平台实现了Map Reduce编程模型,作为一个成熟的开源平台被广泛采用,目前国内外的研究者也大都集中于
Hadoop平台进行分布式数据并行处理的研究。 我们深入了研究面向Hadoop平台的模型驱动的分布式数据并行编程模型及性
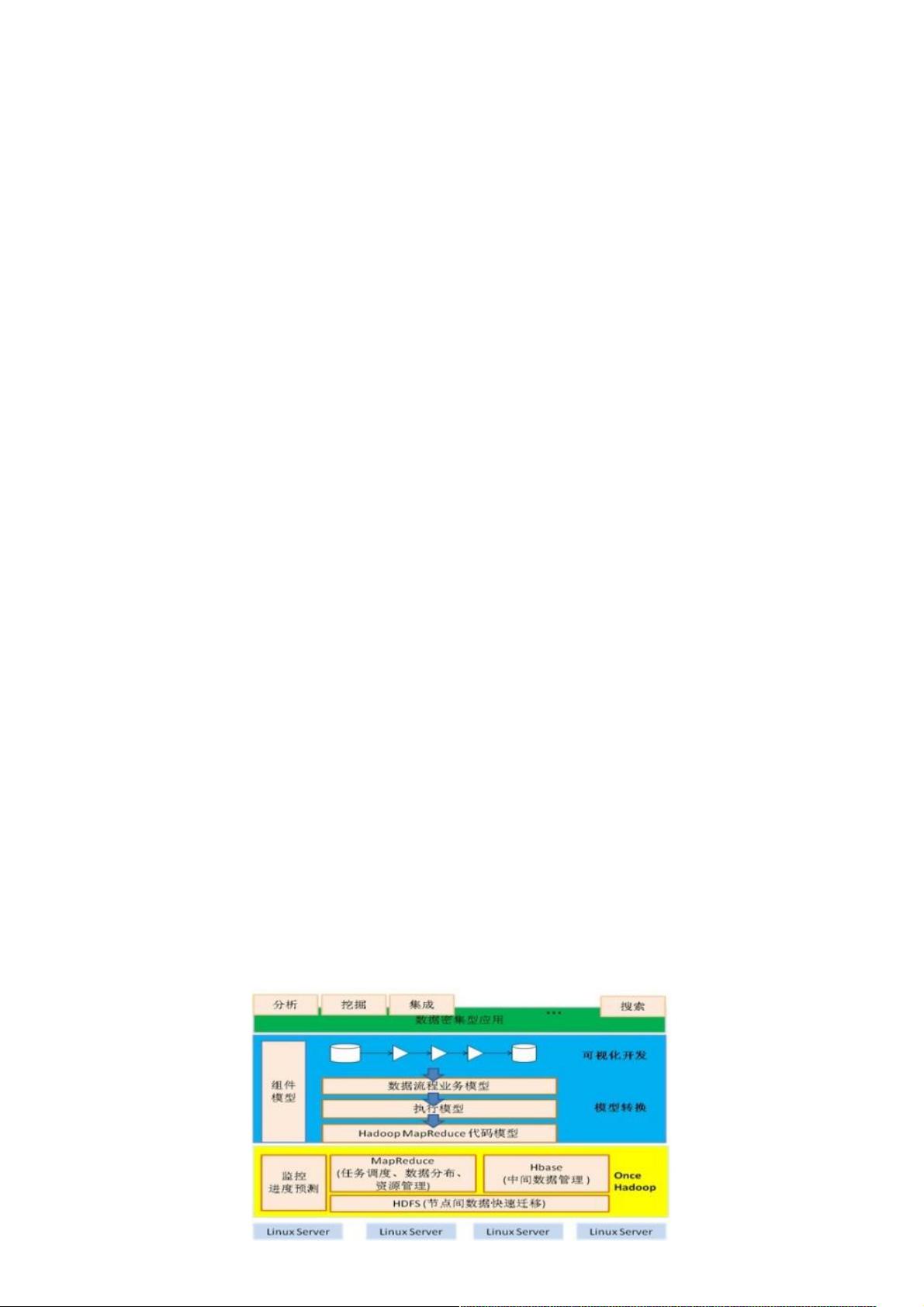
能优化关键技术。提出一个开发框架,首先可视化地建模数据处理流程,并将其转换为MapReduce任务构成的有向无环图,
再映射到MapReduce的代码模型,最终实现自动生成MapReduce代码。提供一些预定义的数据操作组件,并定义了组件模
型,支持用户自定义组件。基于该框架和Hadoop平台,我们实现了一个数据密集型应用开发优化平台OnceDICP(Once Data
Intensive Computing Platform)。本文重点介绍平台架构与模型转换部分技术,平台性能优化等部分将在后续的文章中介绍。
2、相关工作
MapReduce编程模型首先由Google的工程师提出,很多科研机构或企业都对MapReduce实现上做了大量的研究,Hadoop实
现了可以在普通的商用机器集群上并行处理海量数据的MapReduce软件框架[3],Hive提供了基于SQL的简单查询语言Hive
QL来简化数据处理流程的操作,同时支持用户自定义的Map和Reduce操作[7]。Pig也是基于Hadoop平台提供了一种类SQL的
声明式编程语言pigLatin[8],Sawzall则提供了一种类C语言的编程方式实现MapReduce,但是这些系统也存在以下几个问
题:(1)没有统一的数据操作组件模型来支持用户自定义数据处理操作。(2)对于普通用户来说使用系统提供的简化MapReduce
的编程语言仍然有困难,(3)使用通用的MapReduce流程引擎,由于不同流程的差异性,会导致不必要的判断而带来性能上的
损失,(4)系统在MapReduce运行参数设置上对用户完全透明,这对于不同的流程执行效率会带来不稳定的影响。
ETL(Extract, Transform, Load)工作流是典型的数据处理流程,[4,5]将ETL工作流建模为有向无环图,给出了一个通用的框
架,并采用LDL语言表示每个操作节点的处理逻辑。[6]则将ETL工作流采用UML来建模,对状态图进行扩展。数据处理流程并
没有统一的学术定义,这些研究从不同角度给出了数据处理流程的建模方法。本文期望采用建模的方法支持用户的快速开发,
提高数据处理流程开发的可维护性,因此要研究可以转换为云计算平台执行代码的数据处理流程模型。
云计算技术在国内也广受关注,有研究者在2008年就对数据密集型应用的编程模型进行了综述[10],[9]介绍了国内研究者开
发的基于Hadoop的并行数据挖掘平台,该系统已用于中国移动通信企业TB级数据的挖掘。针对编程方法层次,国内研究者关
注的还不多。
3、模型驱动开放框架
3.1模型驱动开发原理
在实际应用场景中,虽然相同的数据流程处理的过程相同,但是在数据量大小,数据格式,处理平台,硬件环境等都会存在很
多差异,为了屏蔽这些差异,给数据处理系统带来最大的灵活性,可以使用模型驱动的开发方法,首先建立从数据处理流程业
务功能角度定义的业务模型,从业务角度来描述流程的业务功能,然后再根据业务模型建立具体编程模型相关的执行模型,执
行模型按照一定的计算模式(MapReduce,串行,并行)定义了流程执行调度策略,接着根据执行模型建立相应的代码模型
(可以使用Java,C,C++等各种语言来实现),最后根据代码模型和执行模型使用代码生成技术来生成流程的实现代码。模
型驱动的方法通过模型重用,对于同一个数据处理流程,可以在保持业务模型不变的情况下根据数据量大小等情况分别选择使
用串行,并行或者MapReduce的方式的执行模型去执行数据处理流程等,给系统带来最大的灵活性和可重用性,同时通过对
模型的按照一些规则进行自动的优化调整可以不断提升流程的运行效率。
资源评论


weixin_38703626
- 粉丝: 3
- 资源: 974









最新资源
- springboot060师生共评的作业管理系统设计与实现.zip
- springboot257基于SpringBoot的中山社区医疗综合服务平台.zip
- MATLAB程序:多微网优化,多能源系统优化,多Energyhub 协同优化 摘要:基于多能量集成的优点,本文建立了一个基于交互控制的双级两阶段框架,以实现互联多能量系统(MESs)之间的最佳能量供应
- springboot062购物推荐网站的设计与实现.zip
- springboot258流浪动物救助网站.zip
- springboot257基于SpringBoot的中山社区医疗综合服务平台_0303174040.zip
- 6自由度机械臂MATLAB仿真KUKA KR6机器人仿真 simulink simscape 逆向运动学,正向运动学 非线性控制
- springboot063知识管理系统.zip
- springboot259交通管理在线服务系统的开发.zip
- springboot259交通管理在线服务系统的开发_0303174040.zip
- springboot064高校学科竞赛平台.zip
- springboot260火锅店管理系统.zip
- springboot260火锅店管理系统_0303174040.zip
- GlobalUrban-ISA-GS.rar 全球城市边界、不透水表面及绿地数据集下载
- Labview工业以太网Ethernetip TCP通讯培训支持所有Ethernetip协议的设备和模块常用罗克韦尔 ABPLC,欧姆龙NXNJPLC数据标签通讯让你从原理上学会从此定值自己的通讯协议
- springboot261高校专业实习管理系统的设计和开发.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


