
深度学习架构深度学习架构
连接主义体系结构已存在 70 多年,但新的架构和图形处理单元 (GPU) 将它们推到了人工智能的前沿。深度学习架构是最近
20 年内诞生的,它显著增加了神经网络可以解决的问题的数量和类型。本文将介绍 5 种最流行的深度学习架构:递归神经网
络 (RNN)、长短期记忆 (LSTM)/门控递归单元 (GRU)、卷积神经网络 (CNN)、深度信念网络 (DBN) 和深度叠加网络 (DSN),
然后探讨用于深度学习的开源软件选项。
深度学习不是单个方法,而是一类可用来解决广泛问题的算法和拓扑结构。深度学习显然已不是新概念,但深度分层神经网络
和 GPU 的结合使用加速了它们的执行,深度学习正在突飞猛进地发展。大数据也助推了这一发展势头。因为深度学习依赖于
监督学习算法(这些算法使用示例数据训练神经网络并根据成功水平给予奖惩),所以数据越多,构建这些深度学习结构的效
果就越好。
深度学习与 GPU 的兴起
深度学习由不同拓扑结构的深度网络组成。神经网络已存在很长一段时间,但多层网络(每个层提供一定的功能,比如特征提
取)的开发让它们变得更加实用。增加层数意味着各层之间和层内有更多相互联系和更多权值。在这里,GPU 可为深度学习
带来助益,使训练和执行这些深度网络成为可能(原始处理器在这方面的效率不够高)。
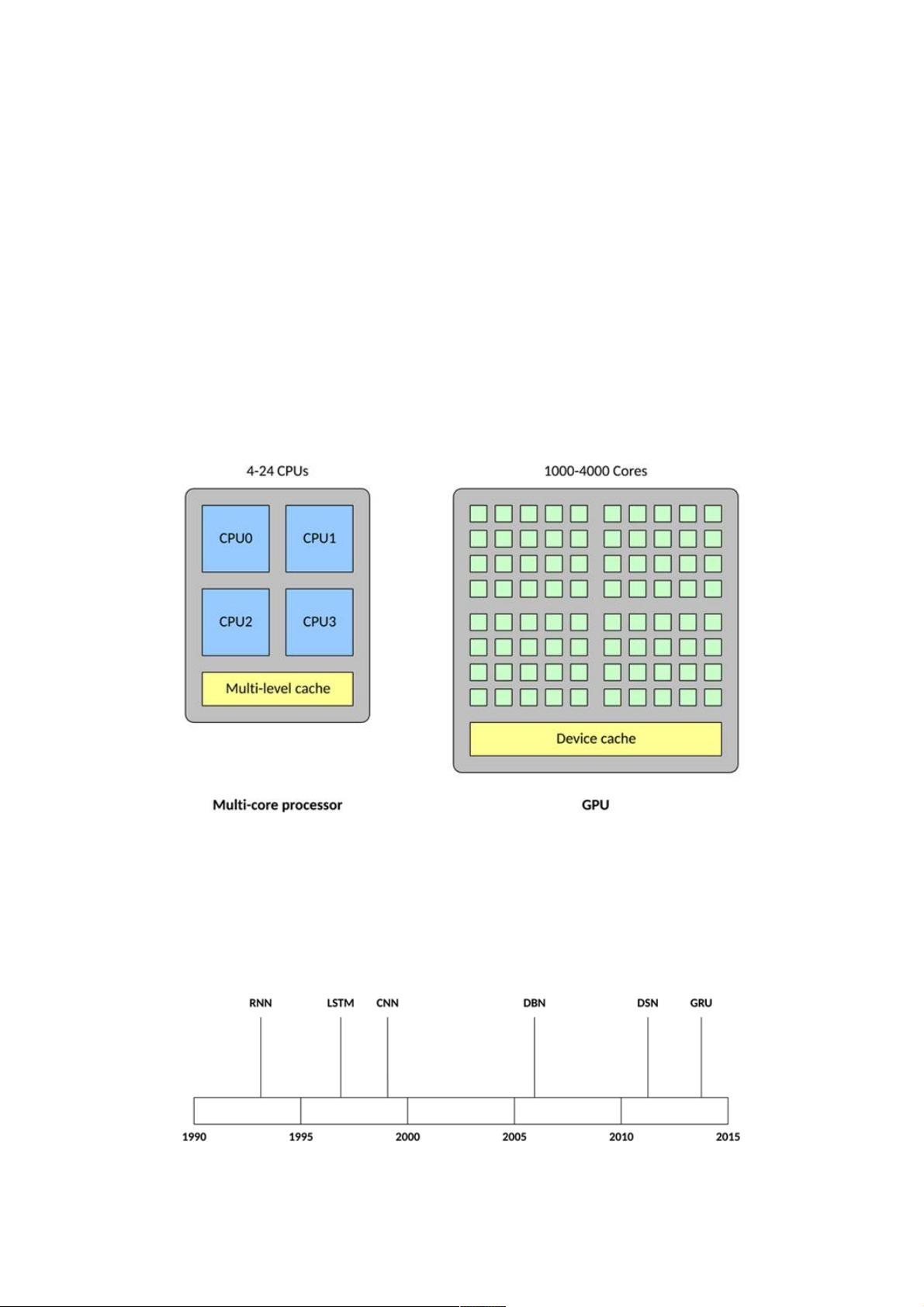
GPU 在一些关键方面与传统多核处理器不同。首先,一个传统处理器可能包含 4 – 24 个通用 CPU,但一个 GPU 可能包含
1,000 – 4,000 个专用数据处理核心。
与传统 CPU 相比,高密度的核心使得 GPU 变得高度并行化(也就是说,它可以一次执行许多次计算)。这使得 GPU 成为大
型神经网络的理想选择,在这些神经网络中,可以一次计算许多个神经元(传统 CPU 可以并行处理的数量要少得多)。GPU
还擅长浮点矢量运算,因为神经元能执行的运算不止是矢量乘法和加法。所有这些特征使得 GPU 上的神经网络达到所谓的高
度并行(也就是完美并行,几乎不需要花精力来并行化任务)。
深度学习架构
深度学习中使用的架构和算法数量丰富多样。本节将探讨过去 20 年来存在的深度学习架构中的 5 种。显然,LSTM 和 CNN
是此列表中最古老的两种方法,但也是各种应用中使用最多的两种方法。
这些架构被应用于广泛的场景中,但下表仅列出了它们的一些典型应用。

剩余6页未读,继续阅读
资源评论


weixin_38702945
- 粉丝: 9
- 资源: 964









最新资源
- 基于QT实现的简单的停车场管理系统详细文档+全部资料+高分项目.zip
- 基于QT实现的银行管理系统详细文档+全部资料+高分项目.zip
- 基于QT实现的一个简单的个人网盘系统,分为好友操作和文件操作两部分。详细文档+全部资料+高分项目.zip
- 基于Qt实现的组态软件运行时系统原型详细文档+全部资料+高分项目.zip
- 基于Qt与MySQL的管理系统详细文档+全部资料+高分项目.zip
- 基于QT与C++的地铁自动售票系统详细文档+全部资料+高分项目.zip
- 基于Qt与C++开发的车载音乐播放系统详细文档+全部资料+高分项目.zip
- thinkphp6内核学生成绩管理系统源码 内附安装说明 站长亲测
- 基于粒子群的PMU优化配置 软件:MATLAB 介绍:电力系统PMU优化配置,为了使电力系统达到完全可观,以PMU配置数量最少为目标函数,运用粒子群算法进行优化处理,在IEEE30 39 57 118
- record_20241224_09_16_49.mp3
- Python实例-Python分块拆分txt文件中的数据
- Python实例-Python汇总各单位Excel档领料记录并加总每日领用次数
- Python实例-Python制作图形用户界面(GUI)让操作可视化
- mmexport1729869897900.jpg
- IMG_20241222_075106.jpg
- ThinkPHP5 MVC框架图书管理系统源码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


